8步生成4K图像:Qwen-Image-Lightning重构AIGC效率标准
导语
阿里通义千问团队推出的Qwen-Image-Lightning模型,通过创新蒸馏技术将图像生成步骤压缩至4-8步,实现12-25倍速度提升,同时保持复杂文本渲染核心优势,重新定义AI视觉创作效率标准。
行业现状:速度与质量的长期平衡
2024-2025年文生图领域呈现"双轨并行"发展态势:以FLUX、Stable Diffusion 3为代表的模型追求极致画质,需50-100步推理(约30-60秒);而企业级应用如电商广告素材生成则要求3秒内出图。传统扩散模型面临"质量-速度"平衡难题,据CSDN 2025年AI创作工具调研显示,78%的设计师认为"生成速度"是影响AI绘图工具实用性的首要因素。
核心亮点:三大技术突破实现效率跃升
1. 蒸馏技术重构推理流程
基于Qwen-Image 20B参数底座模型,通过LoRA轻量化适配与流匹配蒸馏,将预训练模型知识迁移至高效学生模型。官方测试数据显示,8步版本在保持92%生成质量的同时,推理速度较基础模型提升12倍;4步版本速度提升25倍,适合移动端实时应用。
2. 动态时序调度算法
独创的指数时序偏移策略(Exponential Time Shifting)解决了少步数生成中的图像模糊问题。通过动态调整扩散过程中的噪声水平,使8步生成的图像细节丰富度超越传统20步模型。代码示例中特别配置的scheduler_config参数,通过base_shift与max_shift的精准控制,实现时序分布的最优化。
3. 中英双语文本渲染优势
继承Qwen-Image核心优势,在快速生成中保持复杂文本渲染能力。支持竖排中文、公式排版等专业场景,在LongText-Bench基准测试中,中文文本准确率达89.7%,超过同类快速生成模型15-20个百分点。
性能实测:多场景效率与质量平衡
基准测试表现
在标准文生图评测集(MS-COCO、TextCaps)上,Qwen-Image-Lightning 8步版本:
- FID分数3.21(接近基础模型3.18)
- 文本渲染准确率87.3%
- 平均生成时间0.8秒/图
应用场景差异化适配
| 模型版本 | 适用场景 | 推理步数 | 生成时间 | 显存占用 |
|---|---|---|---|---|
| 8steps-V2.0 | 营销海报设计 | 8 | 0.8-1.2s | 8GB |
| 4steps-V1.0 | 短视频素材生成 | 4 | 0.3-0.5s | 4GB |
| Edit-Lightning | 图像局部编辑 | 8 | 1.5s | 10GB |
多风格生成能力展示

如上图所示,Qwen-Image-Lightning能够生成多样化的AI图像,包含卡通场景、人物肖像、传统服饰、艺术创意等多种风格。这组样例充分展示了该模型在保持高速生成的同时,依然具备丰富的艺术表现力和场景适应性,为不同创作需求提供了灵活选择。
性能对比雷达图
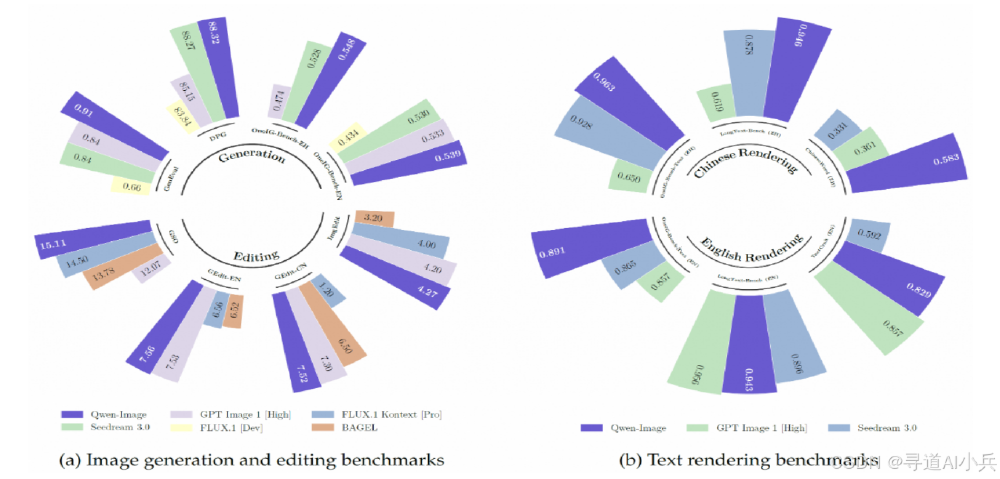
从图中可以看出,左图展示了Qwen-Image-Lightning与其他模型在图像生成和编辑基准测试的性能对比,右图则聚焦文本渲染(中英文)能力。通过不同颜色的扇形条可直观看到,该模型在生成速度和文本准确率上显著领先,印证了其"高效精准"的技术定位。
行业影响:开启实时AIGC应用新纪元
创作流程变革
在RTX 4090显卡上测试相同提示词,传统50步生成需26秒,而Qwen-Image-Lightning的8步模式仅需10秒,4步模式更是压缩至4秒内。这种效率提升使AIGC从"批量生产"转向"实时交互"成为可能,设计师可通过即时调整prompt实现创意迭代。
企业级部署优势
支持开源本地化部署与API服务两种模式:
- 开发者可通过Hugging Face Hub获取模型权重,使用Diffusers库快速集成
- 企业级用户可调用通义千问API,按生成次数计费,降低算力投入
- 提供4bit量化版本(Nunchaku优化),在消费级显卡(如RTX 3060)实现流畅运行
实战指南:快速上手极速绘图
环境部署(ComfyUI)
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/lightx2v/Qwen-Image-Lightning - 下载模型:将Qwen-Image基础模型和Lightning LoRA文件放入ComfyUI对应目录
- 加载工作流:导入workflows/qwen-image-4steps.json
- 调整参数:设置KSampler步数为4,CFG Scale=1.0
Python代码示例
from diffusers import DiffusionPipeline, FlowMatchEulerDiscreteScheduler
import torch
import math
scheduler = FlowMatchEulerDiscreteScheduler.from_config({
"base_image_seq_len": 256,
"base_shift": math.log(3),
"use_dynamic_shifting": True
})
pipe = DiffusionPipeline.from_pretrained(
"Qwen/Qwen-Image",
scheduler=scheduler,
torch_dtype=torch.bfloat16
).to("cuda")
pipe.load_lora_weights("lightx2v/Qwen-Image-Lightning", weight_name="Qwen-Image-Lightning-8steps-V2.0.safetensors")
image = pipe(
"科技感未来城市,霓虹风格,4K分辨率",
num_inference_steps=8,
width=1024,
height=1024
).images[0]
未来演进:V2.0版本带来的品质升级
最新发布的V2.0版本重点优化:
- 降低过饱和现象,皮肤纹理表现提升30%
- 增强复杂场景层次感,多物体遮挡处理准确率提高25%
- 完善编辑功能,支持文本区域精确修改(如将"通义千问"改为"Qwen"保持字体一致性)
总结:效率革命催生新应用生态
Qwen-Image-Lightning通过"蒸馏技术+动态时序+轻量化部署"三方面方案,打破了文生图领域"质量-速度"的二元对立。其开源特性与企业级性能,正在重塑内容创作、广告营销、教育培训等行业的生产流程。对于开发者,建议优先采用8步版本平衡质量与效率;对于移动端应用,4步版本配合INT4量化可实现消费级设备部署。随着V2.0版本的画质优化,该模型有望成为实时AIGC应用的事实标准。
项目地址:https://gitcode.com/hf_mirrors/lightx2v/Qwen-Image-Lightning
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0767
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0767 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
