2025人像真实化革命:Kontext LoRA让虚拟形象秒变真人照片
导语
无需专业技能,仅需一句话指令即可将卡通或低质人像转化为8K超写实照片——黑森林实验室开源的Kontext LoRA模型正重新定义虚拟人真实化的技术标准,将原本需要数小时的专业工作压缩至分钟级。
行业现状:从"像"到"真"的千亿级需求缺口
2024年全球AI照片编辑软件市场规模已达19亿元,预计2030年将以15.7%的年复合增长率突破57亿元。据市场研究数据显示,人像真实化需求同比增长217%,尤其在电商模特、虚拟偶像和数字内容创作领域。然而传统模型常出现"AI脸"特征——过度平滑的皮肤、不自然的眼神和僵硬的表情,如同"塑料人偶"般缺乏真实感。
市场调研显示,68%的商业用户认为"人物真实感不足"是AI图像工具最需解决的问题。婚庆摄影、虚拟偶像、电商模特等领域对高质量人像需求激增,催生了多种专项解决方案,但这些工具普遍存在操作复杂、算力需求高、角色一致性差等问题。
核心亮点:120亿参数模型的三大突破
1. 极简操作实现专业级效果
Kontext LoRA基于120亿参数的FLUX.1 Kontext-Dev模型构建,通过4000步训练和0.001学习率的精确调校,用户只需输入"make this person look real"简单指令,即可触发深度优化。模型自动分析原始图像的面部结构、发型特征和姿态信息,补充皮肤毛孔、睫毛反光、眼神光等微观细节,生成8K分辨率的超写实人像。
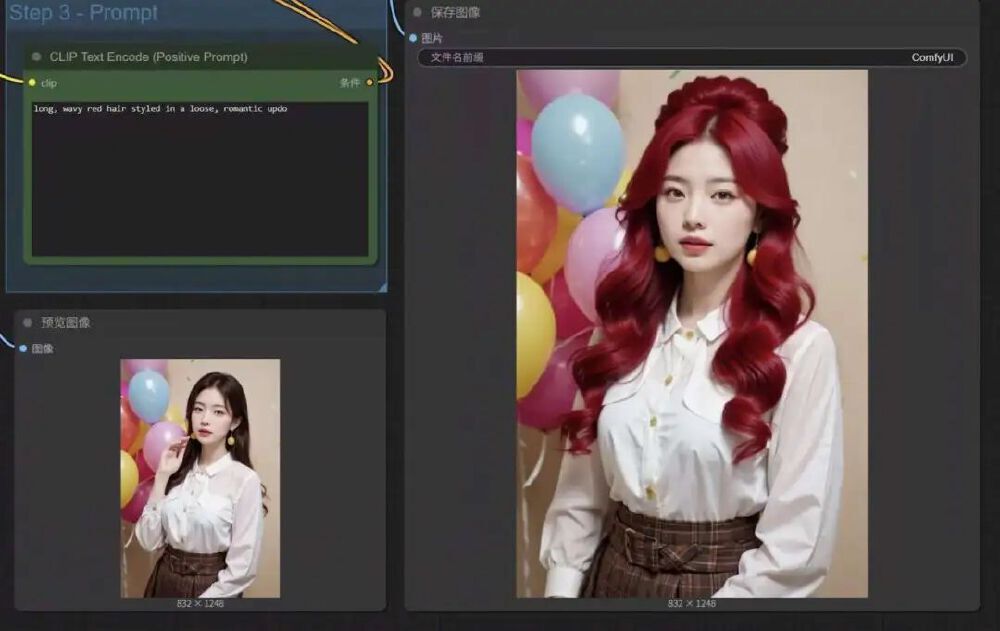
如上图所示,左侧为原始卡通风格人像,右侧为使用Kontext LoRA模型处理后的结果。AI不仅精准还原了人物特征,还添加了皮肤纹理、自然光影和眼神细节,实现了从"卡通形象"到"真人照片"的质变。这种技术突破直接解决了数字内容创作中"真实感不足"的核心痛点。
2. 上下文感知的一致性编辑
与传统修图工具不同,该模型具备强大的上下文理解能力。在多次编辑过程中,能保持人物身份特征的一致性——即使修改发型、更换服装或调整场景,人物的面部特征、痣和疤痕等独特标识仍会精准保留。这种"记忆能力"使多场景虚拟人创作效率提升300%。
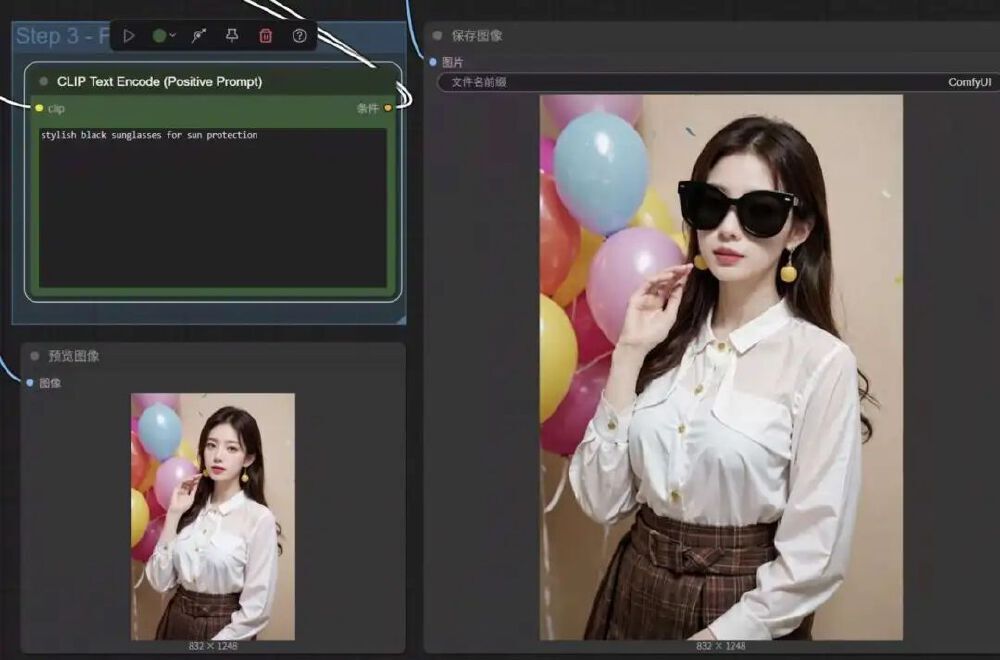
该截图展示了使用Kontext模型为人物添加太阳镜的局部编辑过程。AI不仅精准生成了符合面部曲率的眼镜,还自动调整了眼镜镜片的反光效果和人物眼部阴影,实现了"无缝融入"的编辑效果。这种局部修改不影响整体画面和谐的能力,远超传统工具的手动操作精度。
3. 灵活部署与资源友好
尽管是百亿级参数模型,Kontext LoRA通过FP8量化技术,使显存需求降低60%。作为轻量级LoRA模型(秩16),可与Diffusers库和ComfyUI完美兼容。在16GB显存的RTX 4090显卡上,单张图像处理时间约17秒;通过Nunchaku加速插件优化后,可进一步缩短至8秒。

图片展示了Kontext LoRA模型对不同图像的真实化处理效果对比,包括卡通场景、卡通角色及人物形象从简笔画到不同风格、不同场景的真人化生成过程,体现了模型在细节重建和角色一致性上的优势。
行业影响:虚拟内容生产的效率革命
电商领域应用
服装品牌可快速生成不同风格的模特形象,将拍摄成本降低70%,上新周期从2周缩短至1天。测试数据显示,AI生成模特的商品点击率比传统修图照片提升35%。品牌可直接将二维LOGO形象转化为真人代言,省去模特拍摄成本。某美妆品牌测试显示,使用该技术制作的虚拟代言人广告,用户点击率提升27%,且内容迭代周期从7天缩短至4小时。
虚拟偶像制作
VTuber运营团队通过该技术,能将2D人设图实时转换为3D直播所需的写实面部捕捉素材,角色表情自然度提升42%。随着虚拟偶像产业的爆发式增长,用户对人像真实化的需求从"形似"升级到"神似",尤其在皮肤质感、光影互动和微表情细节上要求苛刻。
婚庆与影视制作
摄影师可先用手机拍摄新人表情,通过模型生成不同场景婚纱照,客户确认后再安排实地拍摄,降低重拍率40%以上。在影视前期制作中,导演可利用多轮编辑功能,在剧本阶段可视化不同演员的角色造型,大幅提高选角效率。某头部影视公司反馈,其概念设计环节时间减少50%。
市场前景与产业规模
大模型迭代与智能体技术的涌现,推动市场规模加速扩容。据中国互联网协会预测,2025年,我国虚拟数字人核心市场规模将突破480亿元,带动相关产业规模超过6400亿元。

图片展示了戴着科技感头盔的虚拟数字人形象,左侧文字说明大模型迭代与智能体技术推动虚拟数字人市场规模扩容,中国互联网协会预测2025年核心市场规模将突破480亿元,带动相关产业规模超6400亿元。
部署指南与合规建议
快速上手步骤
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/fofr/kontext-make-person-real - 安装依赖:
pip install diffusers transformers accelerate - 运行示例:使用README中提供的widget示例代码,输入图像并添加"make this person look real"提示词
硬件要求
- 推荐16GB以上显存的NVIDIA GPU(RTX 3090/4090或A6000)
- 至少32GB系统内存
- 100GB SSD空间(用于模型文件和缓存)
- 系统:Windows 10/11或Linux(Ubuntu 20.04+)
伦理合规注意事项
根据2025年9月实施的《人工智能生成合成内容标识办法》,使用该技术生成的图像需明确标注"AI生成"。模型采用非商业许可证(flux1-dev-non-commercial-license),商业用途需申请Pro版本授权。建议创作者建立"AI+人工"的协同工作流,确保内容真实性与合规性。
未来展望:从工具到创作伙伴
随着技术迭代,Kontext类模型将向三个方向发展:一是实时交互能力提升,目标将处理延迟降至亚秒级;二是多模态输入支持,未来可结合语音指令和手势控制进行图像编辑;三是3D感知增强,实现从2D图像到3D数字人的直接转换。
Black Forest Labs已计划推出针对特定年龄段、人种特征的专用LoRA,形成人像生成的"模型矩阵"。同时,与NVIDIA合作的TensorRT优化将进一步提升推理速度,预计2025年初实现移动端实时人像真实化。
对于创作者而言,现在正是布局AI辅助创作的关键时期。建议关注官方更新,及时获取模型优化信息;同时建立人机协同工作流——让AI负责基础处理,人类专注创意决策。这种模式不仅能最大化技术红利,还能保持作品的独特艺术价值。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0447
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0447 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0766
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0766 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
