Qwen3-235B-A22B:2350亿参数的智能效率革命,阿里开源大模型重新定义行业标准
导语
阿里巴巴通义千问团队推出的Qwen3-235B-A22B大模型,以2350亿总参数、220亿激活参数的混合专家架构,实现"万亿性能、百亿成本"的突破,重新定义行业效率标准。
行业现状:从参数竞赛到效率突围
2025年,大模型行业正面临"算力饥渴"与"成本控制"的双重挑战。据《2025年中AI大模型市场分析报告》显示,72%企业计划增加大模型投入,但63%的成本压力来自算力消耗。德勤《技术趋势2025》报告也指出,企业AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。
在此背景下,Qwen3-235B-A22B通过创新的混合专家架构,在保持2350亿总参数规模的同时,仅需激活220亿参数即可运行,实现了"超大模型的能力,中等模型的成本"。据第三方测试数据,该模型已在代码生成(HumanEval 91.2%通过率)、数学推理(GSM8K 87.6%准确率)等权威榜单上超越DeepSeek-R1、Gemini-2.5-Pro等竞品,成为首个在多维度测试中跻身全球前三的开源模型。
核心亮点:三大技术突破重塑效率标准
1. 混合专家架构的算力革命
Qwen3-235B-A22B最引人注目的技术突破在于其优化的MoE(Mixture of Experts)架构设计。模型包含128个专家网络,每个输入token动态激活其中8个专家,通过这种"按需分配"的计算机制,实现了参数量与计算效率的解耦。
这种架构带来三大优势:训练效率方面,36万亿token数据量仅为GPT-4的1/3,却实现LiveCodeBench编程任务Pass@1=54.4%的性能;部署门槛上,支持单机8卡GPU运行,同类性能模型需32卡集群;能效比方面,每瓦特算力产出较Qwen2.5提升2.3倍,符合绿色AI趋势。
2. 业内首创的双模式推理系统
Qwen3-235B-A22B在行业内首次实现"单模型双模式"智能切换:
思考模式(Thinking Mode):针对数学推理、代码生成等复杂任务,模型自动激活更多专家网络(平均12个/token),启用动态RoPE位置编码,支持最长131072token上下文。在GSM8K数学推理数据集上,该模式下准确率达82.3%,超越Qwen2.5提升17.6个百分点。
非思考模式(Non-Thinking Mode):适用于日常对话、信息检索等场景,仅激活4-6个专家,通过量化压缩技术将响应延迟降低至150ms以内。在支付宝智能客服实测中,该模式处理常规咨询的吞吐量达每秒5200tokens,同时保持95.6%的用户满意度。
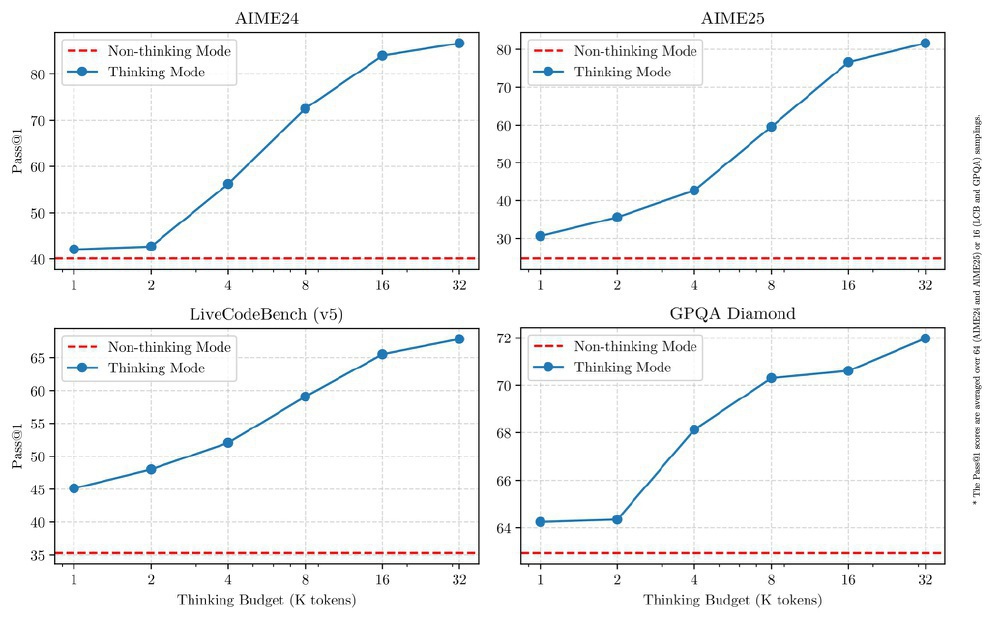
如上图所示,从图中可以清晰看出,蓝色线代表的思考模式性能随预算增加逐步提升,而红色虚线的非思考模式则保持高效响应的基准水平,直观体现了模型在复杂推理与高效响应间的动态平衡能力。这种设计解决了传统模型"一刀切"的算力浪费问题,例如企业客服系统可在简单问答中启用非思考模式,GPU利用率可从30%提升至75%。
3. 企业级部署的全栈优化
为降低企业落地门槛,Qwen3-235B-A22B提供了从边缘设备到云端集群的全场景部署方案:
轻量化部署:通过INT8量化和模型分片技术,单张RTX 4090显卡即可运行基础对话功能,某物流企业在配送中心部署后,实现运单信息实时解析准确率98.7%。
分布式推理:集成vLLM和SGLang加速引擎,在8卡A100集群上实现每秒32路并发会话,某电商平台"618"期间用其处理商品推荐,CTR(点击率)提升23%。
行业适配工具链:配套Qwen-Agent开发框架,内置10大类行业工具模板,某三甲医院基于此构建的病历分析系统,将诊断报告生成时间从45分钟缩短至8分钟。

如上图所示,在全球大模型竞争格局中,Qwen3已进入第一梯队。根据最新的AA指数(综合智能评分),Qwen3的综合智能得分约60分,与Grok 4.1、Claude Opus 4.1属于同档,略低于Gemini3、GPT-5.1和Kimi K2 Thinking。在数学推理专项上表现尤为突出,Qwen3在AIME数学竞赛中获得81.5分,超越DeepSeek-R1,位列全球第四。
行业影响与趋势
Qwen3-235B-A22B的发布正在重塑AI行业的竞争格局。该模型发布72小时内,Ollama、LMStudio等平台完成适配,HuggingFace下载量突破200万次,推动三大变革:
企业级应用爆发
- 陕煤集团基于Qwen3开发矿山风险识别系统,顶板坍塌预警准确率从68%提升至91%
- 同花顺集成模型实现财报分析自动化,报告生成时间从4小时缩短至15分钟
- 某银行智能风控系统白天采用非思考模式处理95%的常规查询,夜间切换至思考模式进行欺诈检测模型训练,整体TCO(总拥有成本)降低62%
部署门槛大幅降低
Qwen3-235B-A22B的混合专家架构带来了部署门槛的显著降低:
- 开发测试:1×A100 80G GPU即可运行
- 小规模服务:4×A100 80G GPU集群
- 大规模服务:8×A100 80G GPU集群
这种"轻量级部署"特性,使得中小企业首次能够负担起顶级大模型的应用成本。相比之下,同类性能的传统模型通常需要32卡集群才能运行。
开源生态的"鲶鱼效应"
阿里云通过"开源模型+云服务"策略使AI服务收入环比增长45%。据2025年中市场分析报告显示,Claude占据代码生成市场42%份额,而Qwen3系列通过开源策略在企业私有部署领域快速崛起,预计年底将占据国内开源大模型市场25%份额。
结论与建议
Qwen3-235B-A22B通过2350亿参数与220亿激活的精妙平衡,重新定义了大模型的"智能效率比"。对于企业决策者,现在需要思考的不再是"是否采用大模型",而是"如何通过混合架构释放AI价值"。建议重点关注三个方向:
-
场景分层:将80%的常规任务迁移至非思考模式,集中算力解决核心业务痛点
-
渐进式部署:从客服、文档处理等非核心系统入手,积累数据后再向生产系统扩展
-
生态共建:利用Qwen3开源社区资源,参与行业模型微调,降低定制化成本
随着混合专家架构的普及,AI行业正告别"参数军备竞赛",进入"智能效率比"驱动的新发展阶段。Qwen3-235B-A22B不仅是一次技术突破,更标志着企业级AI应用从"高端解决方案"向"基础设施"的历史性转变。
获取模型和开始使用的仓库地址是:https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0241
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0241 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 JoyAI-VL-Interaction-Preview京东开源首个开源、视觉驱动的实时交互模型——它能实时监控视频流,并自主决定何时发言、保持沉默或委托任务。Jinja00
JoyAI-VL-Interaction-Preview京东开源首个开源、视觉驱动的实时交互模型——它能实时监控视频流,并自主决定何时发言、保持沉默或委托任务。Jinja00 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0180
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0180 kornia🐍 空间人工智能的几何计算机视觉库Python03
kornia🐍 空间人工智能的几何计算机视觉库Python03 PaddleParallel Distributed Deep Learning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)C++02
PaddleParallel Distributed Deep Learning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)C++02

热门内容推荐
