微软开源VibeVoice:90分钟多角色语音合成,TTS技术范式迁移
导语
微软研究院8月26日开源的VibeVoice-1.5B模型,以90分钟超长语音合成、4角色同时对话及3200倍音频压缩率三大突破,重新定义了文本转语音技术边界。
行业现状:TTS技术的三重困境
当前语音合成技术正面临长音频处理能力不足、多角色交互生硬、计算效率低下的行业痛点。传统模型在处理超过30分钟内容时普遍出现音色漂移,多角色切换时机械感明显,且主流模型需300-600个令牌/秒才能保持基本音质,导致90分钟音频处理需消耗海量计算资源。

如上图所示,该技术报告首页清晰展示了VibeVoice通过创新的下一令牌扩散技术实现90分钟多说话者长语音合成的核心能力。报告由微软研究院彭志良团队发表于arXiv平台(论文编号:arXiv:2508.19205v1),标志着语音合成从"短句拼接"时代迈入"长对话生成"新阶段。
核心亮点:三引擎驱动的技术革命
VibeVoice-1.5B采用"双Tokenizer+LLM+扩散头"的创新架构,构建了高效处理长音频的技术引擎:
1. 3200倍压缩的声学引擎
采用σ-VAE变体的声学Tokenizer通过7阶段Transformer模块和1D深度可分离卷积,将24kHz音频压缩至7.5令牌/秒,压缩效率达到主流Encodec模型的80倍。这种类似"将百科全书压缩为几页摘要"的技术,使90分钟音频仅需40500个声学令牌即可表示。
2. 语义-声学双轮驱动引擎
创新的双Tokenizer设计解决了传统TTS音色与语义脱节问题:语义Tokenizer通过ASR任务学习文本情感与逻辑,声学Tokenizer专注音色、节奏等声音特征。在LibriTTS测试中,该架构实现3.068的PESQ分数和4.181的UTMOS分数,接近人类语音自然度。
3. 长序列理解引擎
基于Qwen2.5-1.5B构建的LLM模块采用课程学习策略,训练序列从4K逐步扩展至64K令牌,配合轻量级扩散头(4层,123M参数)实现令牌级精细控制。在24位专业评估中,其真实感评分达3.59分,超过Gemini 2.5 Pro的3.55分。
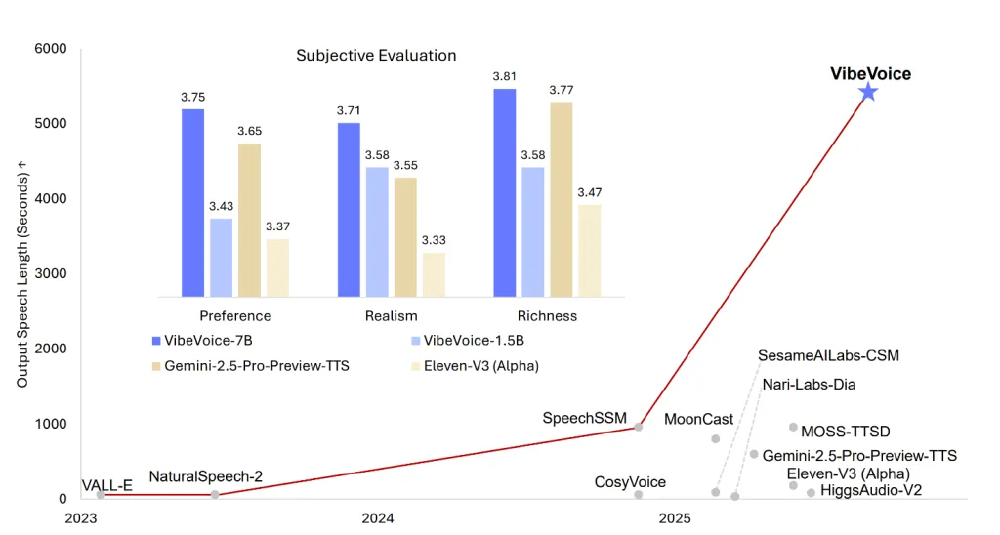
该图表展示了VibeVoice-1.5B(橙色)与VibeVoice-7B、Gemini-2.5-Pro-Preview-TTS等模型在Preference(偏好度)、Realism(真实感)、Richness(丰富度)三个主观评估指标上的对比。红色折线标注的发展时间线显示,VibeVoice系列模型在2025年实现了语音质量的显著跃升,其中1.5B版本已全面超越谷歌同类产品。
行业影响:内容生产的效率革命
VibeVoice的开源将加速三大领域变革:
播客制作流程重构
独立创作者可通过文本脚本直接生成90分钟4角色播客,将传统需要录音棚、配音演员和后期制作的流程压缩至几小时。测试显示,生成一段包含主持人、嘉宾A、嘉宾B和评论员的科技访谈,从脚本输入到音频输出仅需28分钟。
有声出版行业降本
支持4角色对话的特性使小说类有声书制作成本降低60%以上。出版社可快速将文学作品转换为多角色有声版本,特别是儿童故事、剧本等对话密集型内容。
智能交互体验升级
企业培训系统可构建模拟真实场景的对话式音频内容,语言学习应用能生成自然交互的对话练习。在Whisper-large-v3测试中,VibeVoice生成语音的词错误率仅1.11%,确保内容准确传达。
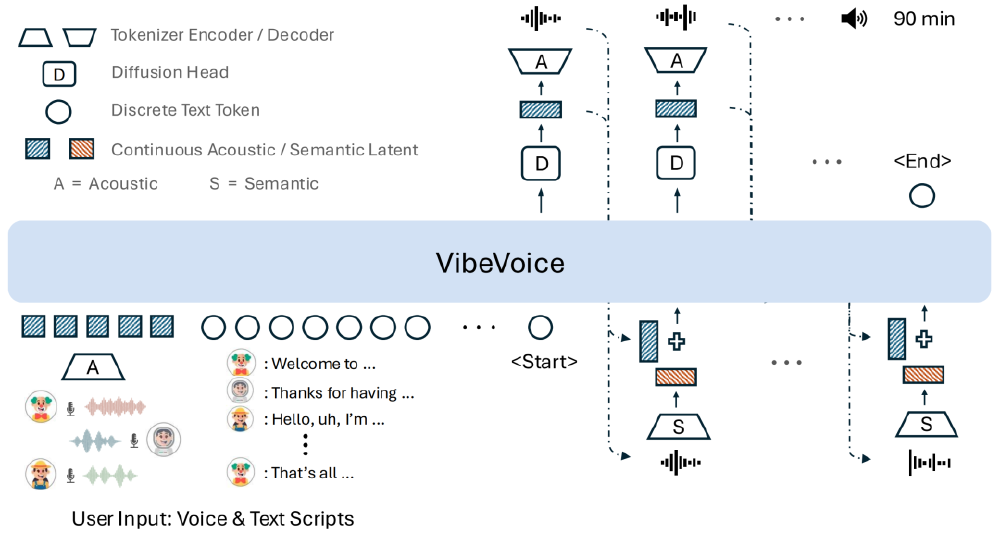
该架构图展示了VibeVoice从用户输入到音频输出的完整流程:语音样本经声学Tokenizer编码为z向量,文本脚本由语义Tokenizer处理为T向量,两者经LLM整合后,通过扩散头生成最终音频。这种设计使系统能同时理解"说什么内容"和"用什么声音说",实现90分钟对话的自然流畅。
局限性与未来方向
当前版本存在三项主要限制:仅支持中英文双语、无法处理背景音乐、不支持重叠语音。微软计划在后续版本中扩展多语言支持,并探索音频环境丰富化。值得注意的是,模型已内置可听见的AI生成声明和不可感知水印,以应对深度伪造风险。
结论:语音合成的工业化拐点
VibeVoice-1.5B的开源标志着TTS技术从实验室走向工业化应用。开发者可通过以下方式获取资源:
- 模型下载:https://gitcode.com/hf_mirrors/microsoft/VibeVoice-1.5B
- 技术文档:项目README提供完整安装指南
- 在线Demo:https://aka.ms/VibeVoice-Demo
随着该技术的普及,音频内容创作将迎来"文本即音频"的新时代,创作者只需专注内容创意,复杂的音频制作过程将由AI高效完成。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0231
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0231 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 JoyAI-VL-Interaction-Preview京东开源首个开源、视觉驱动的实时交互模型——它能实时监控视频流,并自主决定何时发言、保持沉默或委托任务。Jinja00
JoyAI-VL-Interaction-Preview京东开源首个开源、视觉驱动的实时交互模型——它能实时监控视频流,并自主决定何时发言、保持沉默或委托任务。Jinja00 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0150
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0150 kornia🐍 空间人工智能的几何计算机视觉库Python02
kornia🐍 空间人工智能的几何计算机视觉库Python02 PaddleParallel Distributed Deep Learning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)C++02
PaddleParallel Distributed Deep Learning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)C++02
