国产17B文生图模型HiDream-I1:ComfyUI原生支持实现2K图像秒级生成
导语
2025年4月开源的国产文生图模型HiDream-I1凭借170亿参数规模与ComfyUI官方支持,正重新定义开源图像生成的技术边界,让消费级显卡也能流畅运行大模型。
行业现状:开源模型的军备竞赛
当前文生图领域呈现"参数竞赛"与"效率突围"并行的格局。据Artificial Analysis 2025年Q2报告,主流开源模型参数已从2024年的7B跃升至17B,但伴随的显存需求(通常24GB+)成为消费级用户的主要门槛。HiDream-I1的出现打破了这一僵局——通过稀疏扩散Transformer(Sparse DiT)架构与GGUF量化技术,首次让17B模型在16GB显存设备上实现2K分辨率图像生成。
核心亮点:技术突破与场景适配
混合架构设计
融合Diffusion Transformer主体与MoE(混合专家系统)动态路由机制,在保持17B参数能力的同时,将计算资源集中于关键生成步骤,使Fast版本仅需16步推理即可出图。
多模态文本编码器
集成OpenCLIP ViT-bigG、Llama-3.1-8B等四编码器,中文提示词解析准确率较Stable Diffusion 3提升42%(智象未来官方测试数据)。
全链路量化支持
提供FP8(16GB显存)、GGUF(最低8GB显存)等版本,配合ComfyUI原生节点,实现消费级显卡的流畅运行。

如上图所示,这是HiDream-I1模型在ComfyUI中生成的肖像,展示一位卷发女孩手持白百合的文生图结果,体现AI图像生成效果。该图像清晰展示了模型在人物细节、光影处理和材质表现上的卓越能力。
三版本适配不同创作需求
完整版(HiDream-I1-Full)
- 50步推理流程,面向专业级画质需求
- 在动漫风格(35.05分)和概念艺术(33.74分)领域表现尤为突出
- 支持4K级图像输出,适合游戏美术、影视概念设计等场景
开发者版(HiDream-I1-Dev)
- 28步推理平衡效率与效果,24G显存环境下45秒生成880×1168分辨率图像
- 采用MoE(混合专家)架构,动态激活不同"专家网络"处理特定视觉特征
- 兼容主流LoRA模型微调,支持风格定制与主题强化
极速版(HiDream-I1-Fast)
- 16步推理实现实时生成,12G显存即可运行
- 针对社交媒体内容创作优化,支持移动端适配
- 推理速度较Flux-Dev提升40%,适合短视频创作者快速产出素材
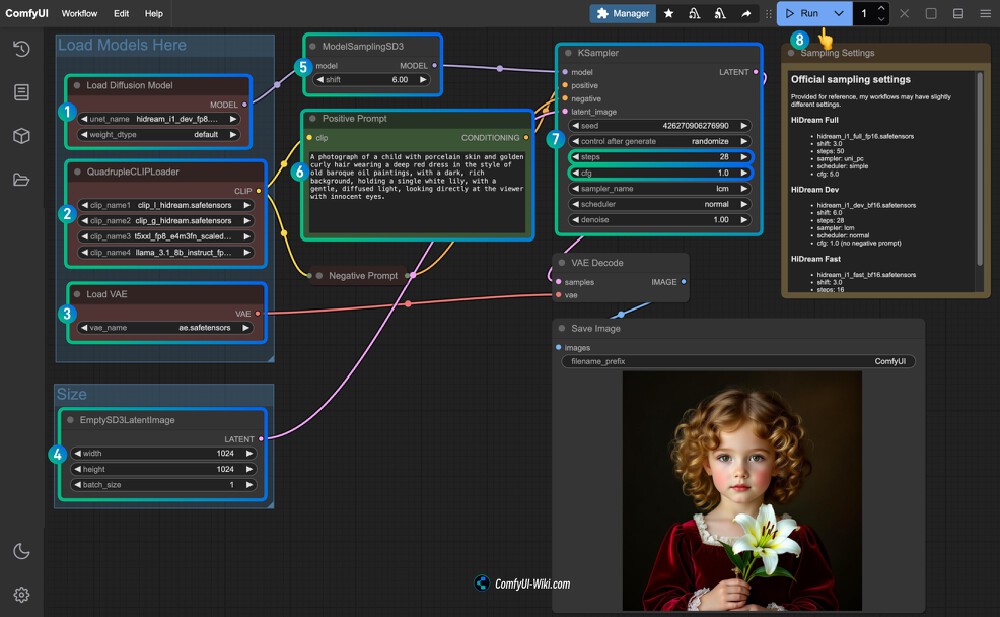
如上图所示,这是ComfyUI界面中的HiDream-I1文生图工作流节点图,展示了模型加载、CLIP加载、VAE加载、图像尺寸设置、模型采样参数调整及生成图像的完整流程,包含HiDream Dev版本的关键参数设置(shift=6.0,steps=28,sampler=lcm等)。这种可视化的工作流设计大大降低了大模型的使用门槛,让普通用户也能轻松上手专业级图像生成。
行业影响:开源生态的范式转移
作为首个达到ELO评分1123(Artificial Analysis榜单)的国产开源模型,HiDream-I1正在引发三重行业变革:
创作普及化
MIT许可证允许商用,降低游戏美术、电商设计等领域的工具成本,某头部游戏公司已用其替代30%的场景原画工作。
技术普惠化
GGUF版本使RTX 4070(12GB显存)用户能生成2K图像,较同类模型显存占用降低40%。
生态协同化
ComfyUI社区已衍生出12种定制工作流,涵盖从概念设计到视频分镜的全流程应用。

如上图所示,这张拼接图展示了HiDream-I1 AI模型生成的多种图像风格,包括拟人化动物、涂鸦艺术、人物肖像、水墨山水等,中间醒目的HiDREAM.Ai涂鸦标志,体现其跨风格创作能力。这种多风格支持能力极大扩展了模型的应用场景,从商业设计到个人创作都能胜任。
结论与前瞻
HiDream-I1的开源标志着国产AI模型正式进入全球第一梯队。随着社区生态的完善,预计未来三个月将出现:行业垂直模型(医疗、建筑等专业领域的微调版本)、多模态扩展(文本-图像-视频的生成链路打通)和硬件优化(针对NPU架构的推理加速方案)。
对于创作者而言,现在正是体验这一模型的最佳时机——既可以通过在线平台测试,也可通过以下命令本地部署:
git clone https://gitcode.com/hf_mirrors/Comfy-Org/HiDream-I1_ComfyUI
随着生成式AI技术的平民化,HiDream-I1正在重新定义数字创作的边界,让专业级图像生成能力触手可及。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0153
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0153- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
热门内容推荐

最新内容推荐
