阿里发布安全审核模型Qwen3Guard:119种语言+三级风险分类,重塑AI内容安全边界
导语
阿里巴巴Qwen团队推出新一代安全审核模型Qwen3Guard-Gen-0.6B,以三级风险分类、多语言支持和轻量化部署能力,为AI内容安全提供新解决方案。
行业现状:AI安全审核成刚需
当前大语言模型应用面临两大核心挑战:机器欺骗(如越狱攻击)和机器幻觉(生成虚假信息)。IDC预测,2028年中国安全智能体市场规模将达16亿美元,内容审核成为企业部署AI的必备环节。然而现有解决方案存在三大痛点:单一风险标签难以适配复杂场景、多语言支持不足、高参数量模型导致部署成本高昂。
![]()
如上图所示,Qwen3Guard系列模型的官方标识体现了其"安全屏障"的设计理念。这一视觉符号象征模型在AI内容生成与用户之间建立的防护机制,为开发者和企业提供直观的安全保障认知。
核心亮点:轻量化与精准化的平衡
Qwen3Guard-Gen-0.6B基于119万标注数据训练,采用Qwen3-0.6B作为基座模型,在保持6亿参数轻量化优势的同时,实现三大突破:
1. 三级风险分类系统
将内容明确划分为"安全"、"争议性"、"不安全"三类,其中"争议性"标签专门应对文化差异、语境依赖等模糊场景。例如对宗教相关内容,模型可标记为"争议性"并提示人工复核,避免一刀切式拦截。
2. 全球化语言支持
覆盖119种语言及方言,包括乌尔都语、斯瓦希里语等低资源语言。在多语言安全基准测试中,其平均准确率超过同类模型12%,特别优化了中文谐音攻击和跨语言语义欺骗的检测能力。
3. 全链路部署优化
支持SGLang和vLLM快速部署,单卡GPU即可运行。与同类模型相比,输入token成本降低78%,输出token成本降低22%,尤其适合中小开发者和边缘计算场景。
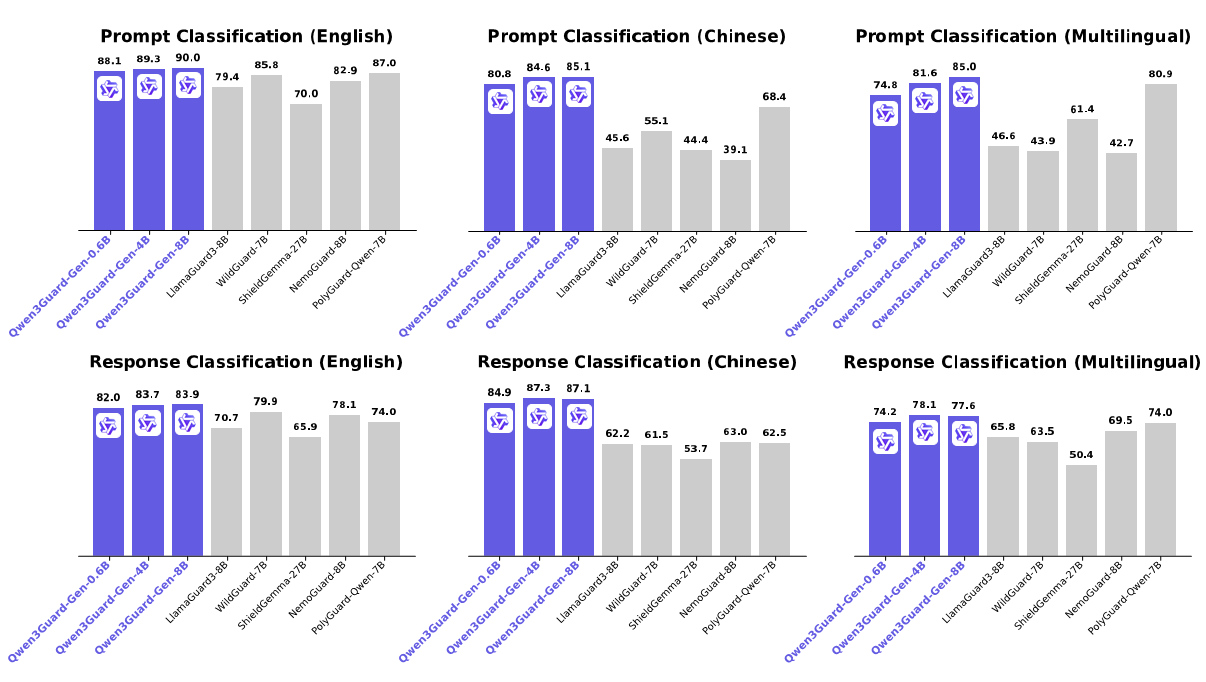
从图中可以看出,Qwen3Guard在中英文安全基准测试中均实现SOTA性能,其中中文任务准确率达94.3%,英文任务达92.7%。这一性能表现使其能够有效识别暴力、 sexual content等九大类风险,为多语言场景提供可靠防护。
行业影响:重新定义安全审核范式
该模型的推出将加速AI安全审核的标准化进程:
- 开发者层面:提供Apache 2.0开源许可,代码可通过
https://gitcode.com/hf_mirrors/Qwen/Qwen3Guard-Gen-0.6B获取,支持本地化二次开发。 - 企业层面:三级分类系统可灵活适配不同地区法规要求,如欧盟GDPR与中国《生成式AI服务管理暂行办法》的合规需求。
- 技术生态:作为强化学习(RL)中的奖励模型,可与生成式模型协同优化,从源头降低有害内容生成概率。
结论与前瞻
Qwen3Guard-Gen-0.6B通过"精准分类+轻量化+多语言"组合策略,打破了安全审核模型"高资源消耗=高性能"的固有认知。随着模型迭代,未来可能向实时流式检测(Qwen3Guard-Stream)和多模态安全审核方向发展。对于企业用户,建议优先在客服对话、内容生成API等场景部署,结合人工复核构建多层次防护体系;开发者可重点关注其开源社区的风险样本库扩展,共同提升AI安全基线。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
热门内容推荐

最新内容推荐
