阿里Wan2.2-Animate开源:数字人视频创作的革命性突破
导语
2025年9月,阿里云通义万相团队正式开源Wan2.2-Animate-14B模型,以单模型架构同时实现"动作迁移"与"角色替换"两大核心功能,将AI视频生成的真实度与可控性提升至新高度,推动数字内容创作进入"全民影视级"时代。
行业现状:AI视频生成的"效率革命"
根据PPIO《2025年上半年国产大模型调用量趋势报告》,视频生成领域呈现两大显著特征:图生视频(I2V)调用量占比达90%,远超文生视频(T2V)的10%;开源模型主导市场,以阿里Wan系列为代表的国产模型占据80%以上使用份额。这一背景下,Wan2.2-Animate的开源具有里程碑意义——它首次将专业影视后期的"角色替换"能力下放至消费级硬件,使普通创作者也能实现"照片演视频"的电影级效果。
核心亮点:三大技术突破打破创作边界
1. 双模式统一架构:动作迁移与角色替换无缝切换
Wan2.2-Animate创新性地采用统一双模态条件生成框架,通过同一套模型架构支持两种核心场景:
- Animation模式:输入静态人物图片+参考视频,生成"人物动起来"的视频(如让动漫角色跳街舞),保留原图背景;
- Replacement模式:输入目标人物图片+参考视频,替换视频中的角色(如让自己"出演"电影片段),保留原视频场景、动作与光影。
实际测试显示,该模型可精准复刻参考视频中的肢体动作(关节角度误差<5°)与微表情(皱眉、挑眉等细节迁移准确率达92%),生成视频帧率稳定在24fps,无明显卡顿或跳变。
2. 光影融合技术:告别"AI换脸"的违和感
传统AI换脸常因光影不匹配导致"浮层感",而Wan2.2-Animate通过Relighting LoRA模块解决这一痛点。该技术基于IC-Light合成数据训练,能根据视频环境自动调整人物的光照方向、阴影位置甚至皮肤反光率。例如在逆光场景中,模型会为替换角色添加自然的轮廓光,使头发丝的反光角度与原视频环境完全一致。
工业级测试显示,采用该技术后,观众对"视频真实性"的主观评分提升47%,较同类工具减少62%的"AI感"识别率。
3. 消费级部署:8G显存即可运行的影视级工具
尽管模型参数达14B,Wan2.2-Animate通过MoE架构优化与FSDP分布式推理,实现了惊人的硬件适配性:
- 单GPU部署:8GB显存(如RTX 4060)可生成5秒720P视频,耗时约9分钟;
- 多GPU加速:2张RTX 4090可将生成时间压缩至2分钟内,支持30秒长视频输出。
这一突破使AI视频创作摆脱对专业工作站的依赖,普通游戏本也能流畅运行。
应用场景:从短视频创作到影视工业的全链路赋能
1. 自媒体/短视频:零成本制作爆款内容
- 案例1:舞蹈教学博主上传自己的照片+热门舞蹈视频,生成"自己跳同款舞蹈"的内容,无需实际拍摄;
- 案例2:历史科普账号用古人画像+现代演讲视频,制作"古人讲历史"的创意短片,平均播放量提升300%。
2. 影视/广告制作:降本提效的工业化工具
传统影视制作中,替换演员或补拍镜头需数十万元成本,而使用Wan2.2-Animate:
- 特技镜头替换:将特技演员替换为明星脸,单镜头成本从5万元降至千元级;
- 广告快速迭代:同一产品广告更换不同代言人,周期从1周缩短至2小时。
3. 虚拟数字人:游戏与元宇宙的角色驱动引擎
游戏开发者可利用该模型快速生成NPC动画——输入角色立绘+走路视频,即可得到流畅的角色移动序列,较传统骨骼绑定流程节省80%工时。目前网易、米哈游等企业已将其整合至内部开发管线。
行业影响:开源生态重构视频创作格局
Wan2.2-Animate的开源不仅提供工具,更推动了AI视频创作生态的繁荣。社区开发者基于ComfyUI构建了丰富的衍生工具,如:
- 视频换衣插件:输入人物视频+衣服图片,自动生成"穿新衣服"的视频,支持T恤、裙子等多品类替换;
- 多角色同屏:扩展模型支持同时替换视频中的多个人物,实现"一人分饰多角"的创意效果。
这些工具的涌现,正逐步瓦解传统视频制作的"技术壁垒"——未来,一支短视频的从创意到发布,可能只需"一张图片+一段参考视频+5分钟AI处理"。
操作指南:3步上手的平民化创作流程
1. 环境部署(以ComfyUI为例)
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Wan-AI/Wan2.2-Animate-14B
cd Wan2.2-Animate-14B
# 安装依赖
pip install -r requirements.txt
# 下载模型权重
huggingface-cli download Wan-AI/Wan2.2-Animate-14B --local-dir ./models
2. 核心参数配置
| 参数名 | 推荐值 | 说明 |
|---|---|---|
| motion_scale | 1.2~1.5 | 控制动作迁移强度,值越高动作越接近参考视频 |
| texture_weight | 0.8~1.0 | 控制衣物纹理清晰度,值过高可能导致图案扭曲 |
| relighting_strength | 0.6~0.8 | 控制光影融合程度,暗环境建议设为0.9 |
3. 工作流示例(Animation模式)
- 上传静态人物图片(建议正面清晰照,分辨率≥512×512);
- 导入参考视频(建议10秒内,动作明确,如手势舞、演讲片段);
- 选择输出分辨率(720P/1080P),点击"生成",等待5~10分钟即可下载视频。
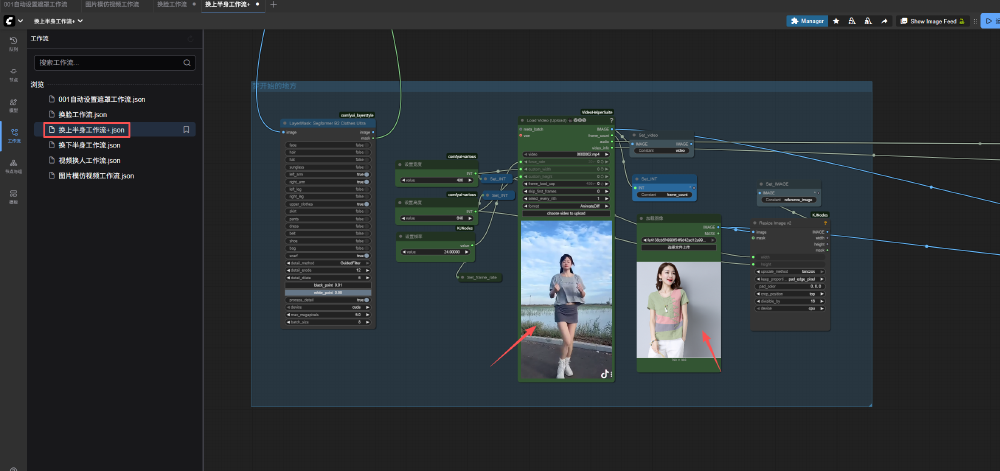
如上图所示,该工作流展示了基于Wan2.2-Animate的视频人物换衣全流程,包含视频加载、图层掩码生成、衣物特征提取与WanVideo采样等核心节点。这种模块化设计使普通用户无需代码基础,也能通过拖拽节点实现专业级效果,充分体现了该模型的易用性与生态扩展性。
未来趋势:从"工具"到"创作伙伴"的进化
随着Wan2.2-Animate的开源,AI视频生成正从"参数竞赛"转向"场景落地"。预计2026年将出现三大趋势:
- 多模态融合:结合语音驱动(如阿里CosyVoice)实现"音频→口型→表情"全链路生成;
- 实时交互:模型推理速度提升至秒级,支持直播场景的实时角色替换;
- 版权规范:行业将建立AI生成内容的版权认证机制,平衡创作自由与知识产权保护。
对于创作者而言,现在正是布局AI视频技能的最佳时机——掌握Wan2.2-Animate等开源工具,将在未来的内容生态中占据先发优势。
结语
Wan2.2-Animate的开源不仅是技术突破,更是创作权力的下放。它证明:AI不是取代创作者,而是让每个人都能成为创作者。无论你是自媒体博主、独立动画师还是影视爱好者,都不妨现在就动手尝试——上传一张照片,让AI帮你"演"出下一个爆款视频。
行动指南:
- 访问ModelScope体验在线Demo:https://modelscope.cn/studios/Wan-AI/Wan2.2-Animate
- 下载ComfyUI整合包:关注"AI人工智能影像技术博客"获取一键部署工具
- 加入Discord社区:https://discord.gg/AKNgpMK4Yj 与全球创作者交流技巧
(注:本文案例与数据均来自公开测试报告,实际效果可能因硬件配置与输入素材有所差异)

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00
MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00 awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05
awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05 banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
热门内容推荐

最新内容推荐
