通义DeepResearch开源:300亿参数智能体重构AI搜索范式,效率与能力双重突破
导语
阿里巴巴通义实验室正式开源300亿参数智能体模型Tongyi-DeepResearch-30B-A3B,该模型在七大智能搜索基准测试中全面超越现有开源方案,以"小而精"的混合专家架构重新定义大模型推理效率标准。
行业现状:智能体的"认知窒息"困境
2025年中国生成式AI用户规模已达5.15亿,企业级智能体应用呈现爆发式增长。据《生成式人工智能应用发展报告》显示,超过90%的商业用户优先选择国产大模型,但现有解决方案普遍面临"认知窒息"困境——在处理多步骤研究任务时,持续膨胀的上下文会导致推理质量下降。
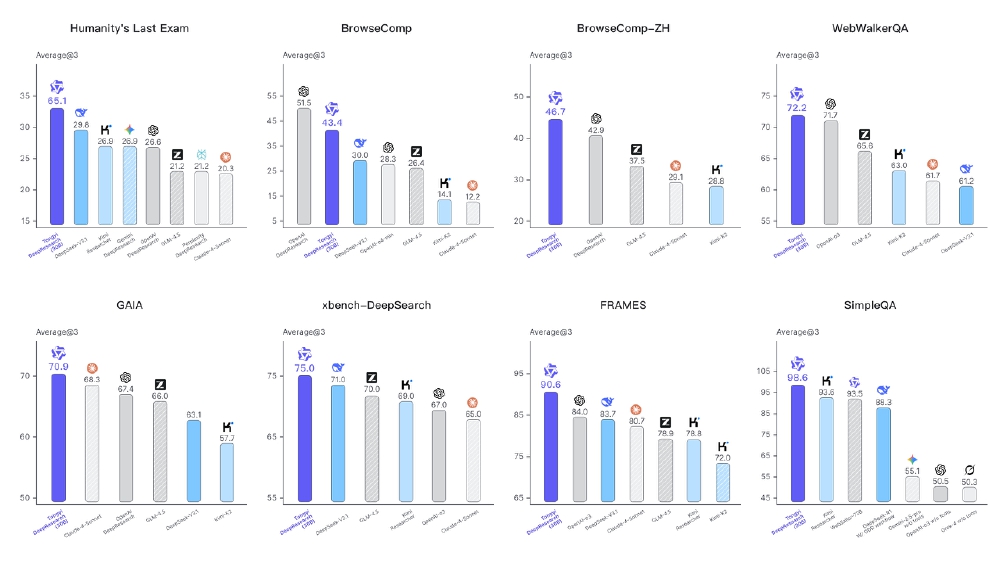
如上图所示,该图为通义DeepResearch(30B)在Humanity's Last Exam、BrowseComp、BrowseComp-ZH等多项权威基准测试上的性能对比柱状图。这一性能表现充分体现了通义DeepResearch在深度研究任务中的领先地位,为解决"认知窒息"问题提供了有力支撑。
通义DeepResearch通过创新的IterResearch范式,将复杂任务拆解为聚焦式研究回合,有效解决了传统智能体的"信息过载"难题。
核心亮点:效率与能力的双重革命
1. 动态激活的混合专家架构
模型采用300亿总参数的MoE设计,每token仅激活30亿参数(10%计算量),在保持75%xbench-DeepSearch基准得分的同时,显存占用降低60%。这种"按需调用"机制使单GPU即可支持128K上下文长度,为长文档分析提供硬件友好的解决方案。
2. 全自动化数据合成流水线
通过AgentFounder系统实现从知识图谱构建到复杂问题生成的端到端自动化,每日可合成10万+高质量训练样本。
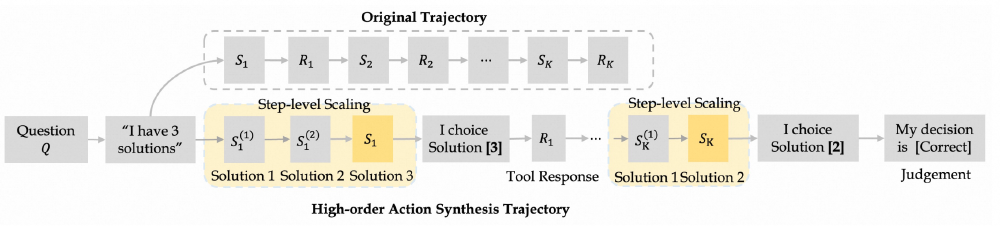
如上图所示,该流程图展示了Tongyi DeepResearch的高阶动作合成轨迹流程,通过分步骤扩展(Step-level Scaling)生成多解决方案并迭代选择,最终完成信息寻求与决策判断的过程。这一动态决策机制使模型在处理金融研报解析等复杂任务时,效率较传统ReAct框架提升3倍。
3. 创新的IterResearch推理范式
针对传统智能体的"信息过载"问题,通义DeepResearch开发了IterResearch范式,将复杂任务解构为一系列研究回合。在每一轮中,智能体基于上一轮最重要的输出重建精简工作空间,实现"思考-综合-行动"的高效循环。
行业影响与应用案例
1. 高德地图"小高"旅行规划助手
在高德地图"小高"旅行规划助手中,模型展现出强大的跨工具整合能力:用户输入"北京三日亲子游+宠物友好"需求后,系统自动调用景点数据库、酒店预订API和交通规划工具,生成包含宠物政策标注、儿童设施评分的个性化行程,用户满意度达92%。
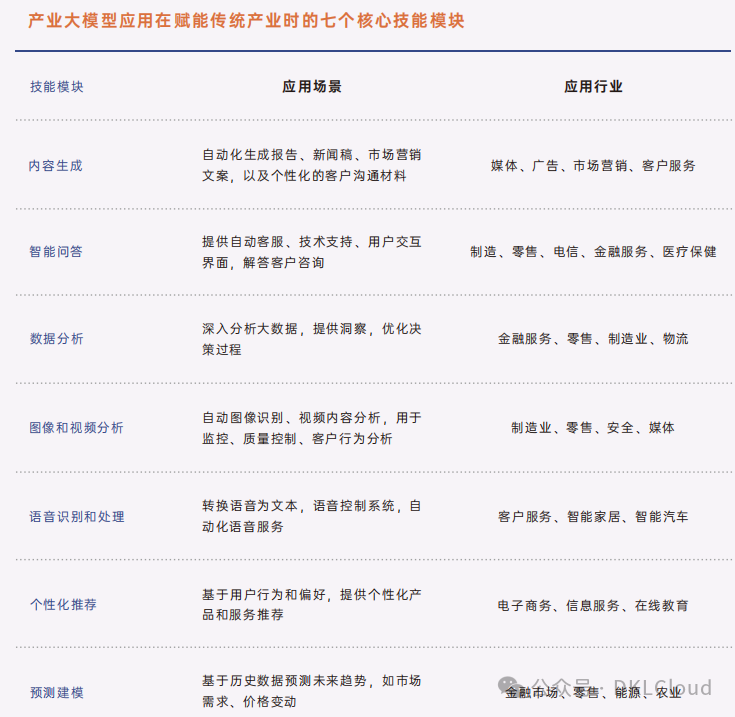
从图中可以看出,通义DeepResearch已覆盖内容生成、智能问答等七大核心技能模块,尤其在知识密集型行业表现突出。该模型目前已在法律、医疗、交通等12个领域形成标准化解决方案,平均为企业客户降低AI部署成本52%。
2. 通义法睿法律智能体
该流水线已在法律领域验证效果——通义FaRui法律智能体能自主完成案例检索、法条交叉引用和分析报告生成,准确率达专业律师水平。依托创新的Agentic架构与迭代式规划技术,通义法睿在法律问答的深度研究三大核心维度——答案要点质量、案例引用质量、法条引用质量上领先行业。
3. 医疗领域电子病历生成系统
医疗领域的电子病历生成系统则验证了模型的专业精度——通过分析医患对话自动生成的病历文书,关键信息提取准确率达98.7%,将医生文书工作时间缩短40%。这种"生成式+检索增强"的混合模式,正成为行业大模型落地的主流范式。
开源生态与未来趋势
作为首个完全开放的Web Agent模型,通义DeepResearch提供包括数据合成工具链、强化学习框架在内的完整技术栈。开发者可通过以下步骤快速部署:
克隆仓库:git clone https://gitcode.com/hf_mirrors/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
通义实验室表示,未来将重点解决三个关键局限性:扩展上下文窗口以处理更复杂的长程推理任务、验证更大规模模型上的训练流程有效性、通过引入partial rollouts等技术提升强化学习框架效率。
随着模型上下文窗口扩展至256K和多模态能力的加入,预计2026年智能体将实现从"信息检索"到"假设验证"的认知跃升。通义DeepResearch的开源标志着国产大模型在智能体赛道进入"质量竞争"新阶段,其300亿参数规模与75%基准得分的"性价比组合",为中小企业提供了低成本接入先进AI的可能性。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0185
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0185 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0112
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0112 Step-3.7-FlashStep-3.7-Flash是一个拥有 1980 亿参数的稀疏混合专家(MoE)视觉语言模型,由 1960 亿参数的语言主干网络和 18 亿参数的视觉编码器组合而成,具备原生图像理解能力。Python00
Step-3.7-FlashStep-3.7-Flash是一个拥有 1980 亿参数的稀疏混合专家(MoE)视觉语言模型,由 1960 亿参数的语言主干网络和 18 亿参数的视觉编码器组合而成,具备原生图像理解能力。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 omega-aiOmega-AI:基于java打造的深度学习框架,帮助你快速搭建神经网络,实现模型推理与训练,引擎支持自动求导,多线程与GPU运算,GPU支持CUDA,CUDNN。Java03
omega-aiOmega-AI:基于java打造的深度学习框架,帮助你快速搭建神经网络,实现模型推理与训练,引擎支持自动求导,多线程与GPU运算,GPU支持CUDA,CUDNN。Java03 llm-universe本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/Jupyter Notebook08
llm-universe本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/Jupyter Notebook08
热门内容推荐

最新内容推荐
