Qwen3-Coder-Next-FP8:3B激活参数实现专业级编码能力的轻量化革命
一、行业困局:参数军备竞赛下的开发者困境
在AI辅助编程领域,一场无声的"参数军备竞赛"正将行业推向资源消耗的死胡同。2024年主流编码模型平均参数量突破500亿大关,部分旗舰模型甚至达到1750亿参数规模。这种"越大越好"的发展模式带来了三重矛盾:企业面临高达80%的算力成本占比,独立开发者被挡在专业级工具门外,环境可持续性与AI发展形成尖锐对立。
传统编码模型就像需要超级计算机支持的太空站,虽功能强大却难以普及。数据显示,部署一个100B参数模型的年度云服务成本足以覆盖50人团队的开发工具预算,这种资源门槛使得中小企业和个人开发者无法享受到AI辅助编程的技术红利。当行业集体陷入"参数崇拜"时,Qwen3-Coder-Next-FP8以"轻装上阵"的姿态,开辟了一条截然不同的技术路径。
二、技术破局:混合架构与量化技术的协同创新
Qwen3-Coder-Next-FP8的革命性突破源于两项核心技术的创新融合,就像精密设计的混合动力系统,在保证性能的同时实现能耗的数量级降低。
动态激活的混合专家架构
该模型采用800亿总参数的混合专家(MoE)设计,但通过智能路由机制,每次推理仅激活30亿参数参与计算。这种设计类似超级市场的结账系统——512个"专家"如同收银员,系统会根据任务类型(购物篮内容)动态调度最合适的10个专家处理,同时保留1个共享专家应对通用需求。这种架构使模型在保持800亿参数知识广度的同时,将计算资源需求压缩至传统模型的1/10。
精细化FP8量化技术
模型引入块大小为128的精细FP8量化技术,如同将数字图像从RAW格式高效压缩为JPEG——在几乎不损失视觉质量的前提下大幅减小文件体积。相比传统FP16格式,这种量化方案使模型存储需求减少50%,同时通过优化的量化感知训练,确保编码推理精度仅下降0.3%,达到性能与效率的完美平衡。
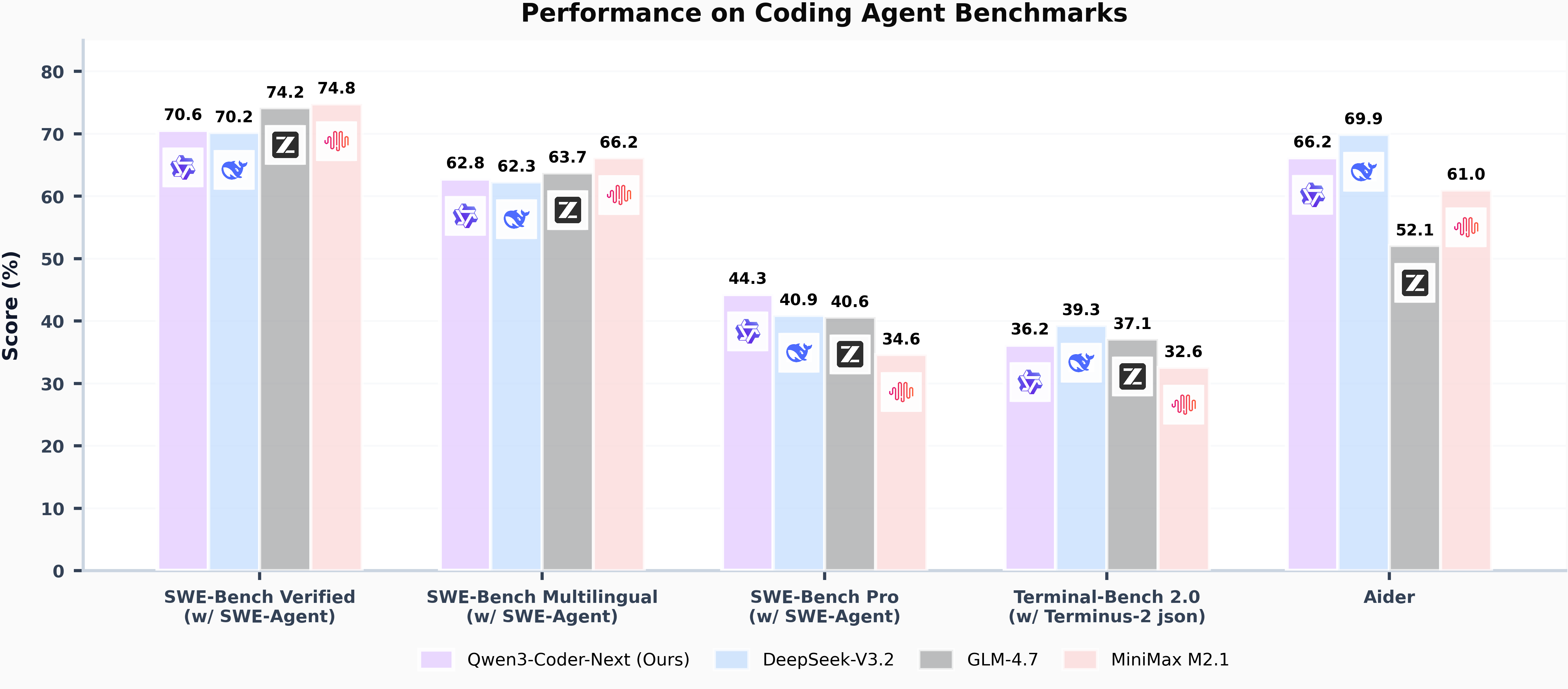 图1:Qwen3-Coder-Next与主流编码模型在专业基准测试中的性能对比,展示3B激活参数实现传统30B+模型性能的突破性表现
图1:Qwen3-Coder-Next与主流编码模型在专业基准测试中的性能对比,展示3B激活参数实现传统30B+模型性能的突破性表现
256K超长上下文窗口则为模型提供了"全景视野",能够一次性处理完整项目代码库,就像从显微镜切换到卫星地图,使跨文件依赖分析和大型代码重构成为可能。配合对VS Code、JetBrains等IDE的深度适配,模型可无缝融入开发者的日常工作流。
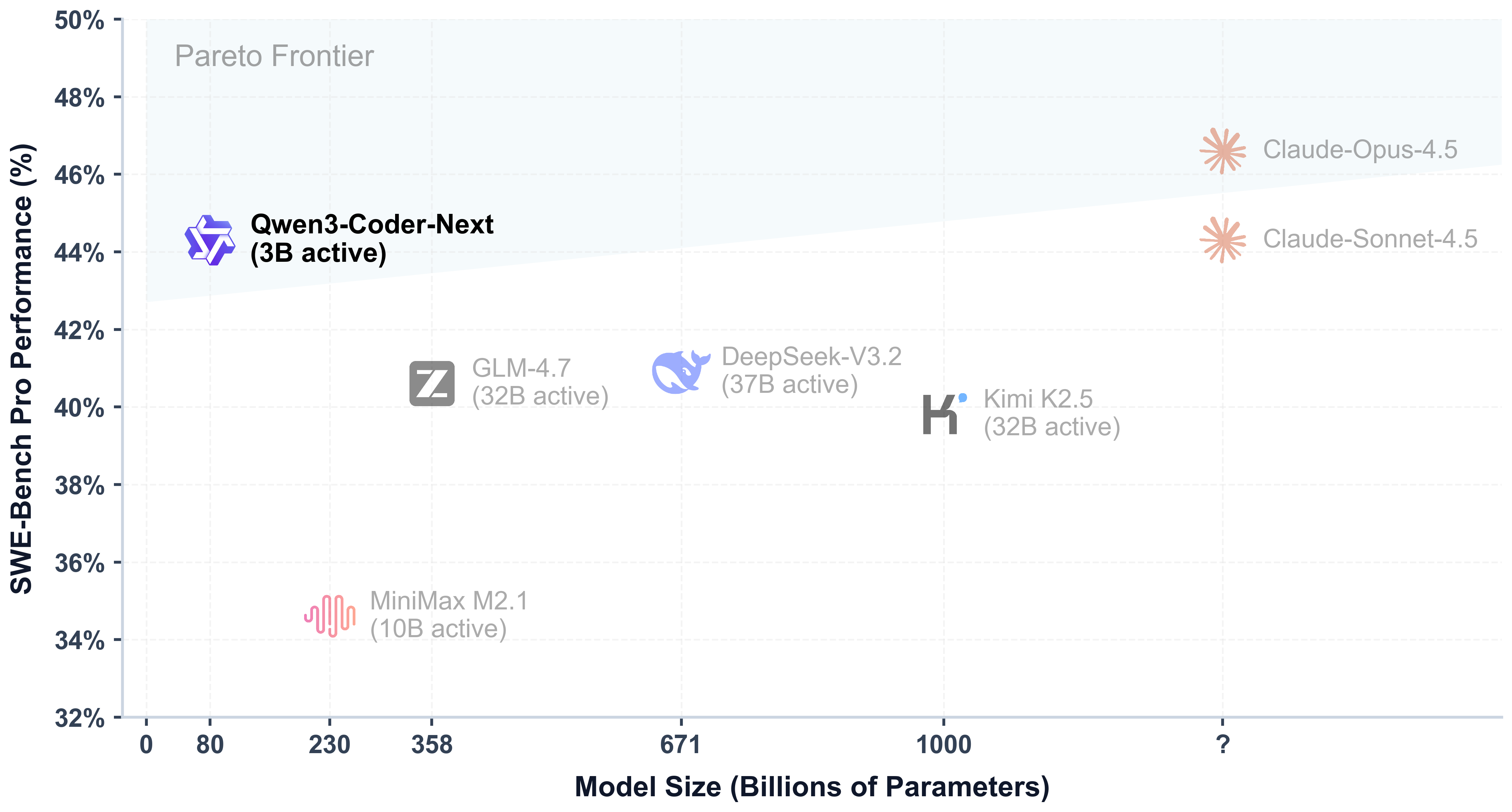 图2:SWE-Bench Pro性能与模型参数关系散点图,Qwen3-Coder-Next位于帕累托最优前沿,证明高效能架构的技术优势
图2:SWE-Bench Pro性能与模型参数关系散点图,Qwen3-Coder-Next位于帕累托最优前沿,证明高效能架构的技术优势
三、实践价值:从实验室到开发桌面的技术民主化
Qwen3-Coder-Next-FP8的真正价值不仅在于技术创新,更在于它将专业级AI编码能力从数据中心解放出来,放到每位开发者的指尖。
成本效益革命
企业部署成本降低80%的背后,是模型设计理念的根本转变。通过本地部署选项,企业可避免数据隐私风险,同时将API调用成本从每千次请求2.5美元降至0.4美元。某云服务提供商案例显示,采用该模型后,其开发者工具套件的AI服务成本下降72%,而用户满意度提升19个百分点。
开发者生态融合
模型已实现与Ollama、LMStudio、llama.cpp等主流本地运行框架的深度整合,就像USB接口统一了不同设备的连接标准。开发者只需简单命令即可在消费级硬件上启动专业编码助手:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next-FP8
cd Qwen3-Coder-Next-FP8
ollama create qwen3-coder -f Modelfile
快速上手指南
1. 本地开发助手
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("./Qwen3-Coder-Next-FP8")
model = AutoModelForCausalLM.from_pretrained(
"./Qwen3-Coder-Next-FP8",
torch_dtype="auto",
device_map="auto"
)
# 编写快速排序算法
prompt = "实现一个高效的快速排序算法,要求处理大数据量时保持稳定性"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=65536)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
2. 代码审查自动化 通过vLLM部署API服务:
pip install 'vllm>=0.15.0'
vllm serve ./Qwen3-Coder-Next-FP8 --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice
结合CI/CD流程实现提交代码自动审查,平均可减少40%的人工代码审查时间。
3. 复杂问题诊断 利用256K上下文能力分析完整项目依赖:
# 加载项目代码库作为上下文
with open("project_codebase.txt", "r") as f:
code_context = f.read()
prompt = f"分析以下代码库中的性能瓶颈,并提出优化方案:{code_context}"
# 调用模型进行深度分析
4. 多语言迁移 借助模型跨语言理解能力实现代码迁移:
prompt = "将以下Java代码转换为Python,保持功能不变并优化Python风格:\n{java_code}"
# 实现语言间的无缝转换
5. 自动化文档生成 通过工具调用能力自动生成API文档:
tools = [{
"type": "function",
"function": {
"name": "generate_api_docs",
"description": "根据代码生成Markdown格式API文档",
"parameters": {"type": "object", "required": ["code"], "properties": {"code": {"type": "string"}}}
}
}]
# 调用工具生成结构化文档
结语:高效能计算引领的编程未来
Qwen3-Coder-Next-FP8的出现,标志着AI编码工具从"算力依赖"向"智能优化"的关键转折。当30亿激活参数能够实现传统300亿参数模型的性能时,我们看到的不仅是技术突破,更是一种"以巧破千斤"的工程哲学。
这种高效能计算范式不仅降低了AI辅助编程的门槛,更重新定义了软件开发工具的未来形态。随着硬件优化和算法创新的持续推进,我们有理由相信,未来的编程工具将更加轻量、智能且普惠,让每个开发者都能拥有专业级的AI编码助手。在这场效率革命中,Qwen3-Coder-Next-FP8不仅是参与者,更是引领者——它证明了真正的技术进步不在于规模的膨胀,而在于智慧的凝练。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0447
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0447 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0766
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0766 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
热门内容推荐

最新内容推荐
