通义千问重磅发布Qwen2.5-Omni:重构多模态交互范式,中端硬件实现全实时体验
近日,阿里云通义千问团队正式推出新一代旗舰级多模态大模型Qwen2.5-Omni,标志着AI交互技术进入"全模态实时响应"新纪元。该模型突破性实现文本、图像、音频、视频四大模态的端到端融合处理,通过创新架构与量化技术,首次让消费级显卡具备流畅运行多模态大模型的能力,为智能交互应用开发带来革命性突破。
全模态交互架构:从信息接收到内容生成的无缝衔接
Qwen2.5-Omni构建了业界首个支持全模态流式处理的AI交互系统,用户可同时输入文本指令、上传图像文件、录制语音片段或提交视频素材,模型能实时理解跨模态信息并生成同步响应。这种端到端处理能力彻底改变了传统多模态模型需要模态转换中间环节的局限,使AI交互首次实现"所见即所得"的自然体验。
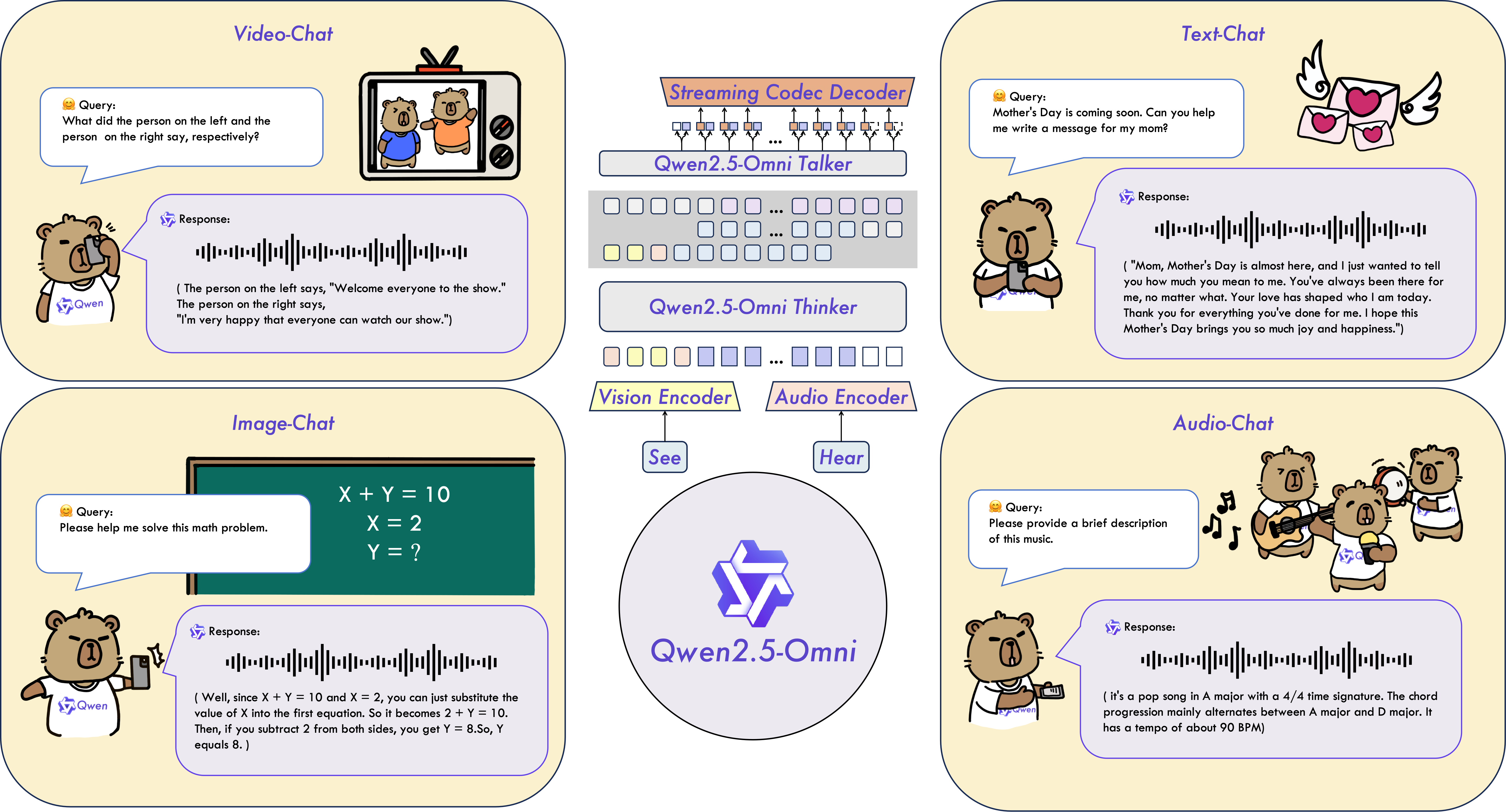 如上图所示,该示意图直观展示了Qwen2.5-Omni的多模态输入输出流程,用户可通过文本、图像、音频、视频等多种方式与模型交互,并实时获得文本或语音响应。这一交互范式充分体现了模型的全模态融合能力,为开发者构建下一代智能交互应用提供了清晰的技术路径。
如上图所示,该示意图直观展示了Qwen2.5-Omni的多模态输入输出流程,用户可通过文本、图像、音频、视频等多种方式与模型交互,并实时获得文本或语音响应。这一交互范式充分体现了模型的全模态融合能力,为开发者构建下一代智能交互应用提供了清晰的技术路径。
模型创新性采用的Thinker-Talker双引擎架构,实现了认知处理与内容生成的并行计算。其中Thinker模块负责多模态信息的深度理解与逻辑推理,Talker模块则专注于自然语音与文本的流式生成,两者通过高速数据通道实现毫秒级协同。这种设计使系统在处理60秒长视频输入时,能同步生成语音解说,实现类似人类"边看边说"的认知习惯。
TMRoPE技术:破解多模态时序对齐难题
在多模态处理领域,视频帧与音频流的时间戳同步一直是技术瓶颈。Qwen2.5-Omni提出的TMRoPE(Time-aligned Multimodal RoPE)位置嵌入技术,通过动态时间轴映射机制,将不同模态的时序特征统一到绝对时间坐标系中。实验数据显示,该技术使视频音频同步误差控制在8ms以内,较传统方法降低92%的时序偏移,确保了多模态信息理解的准确性。
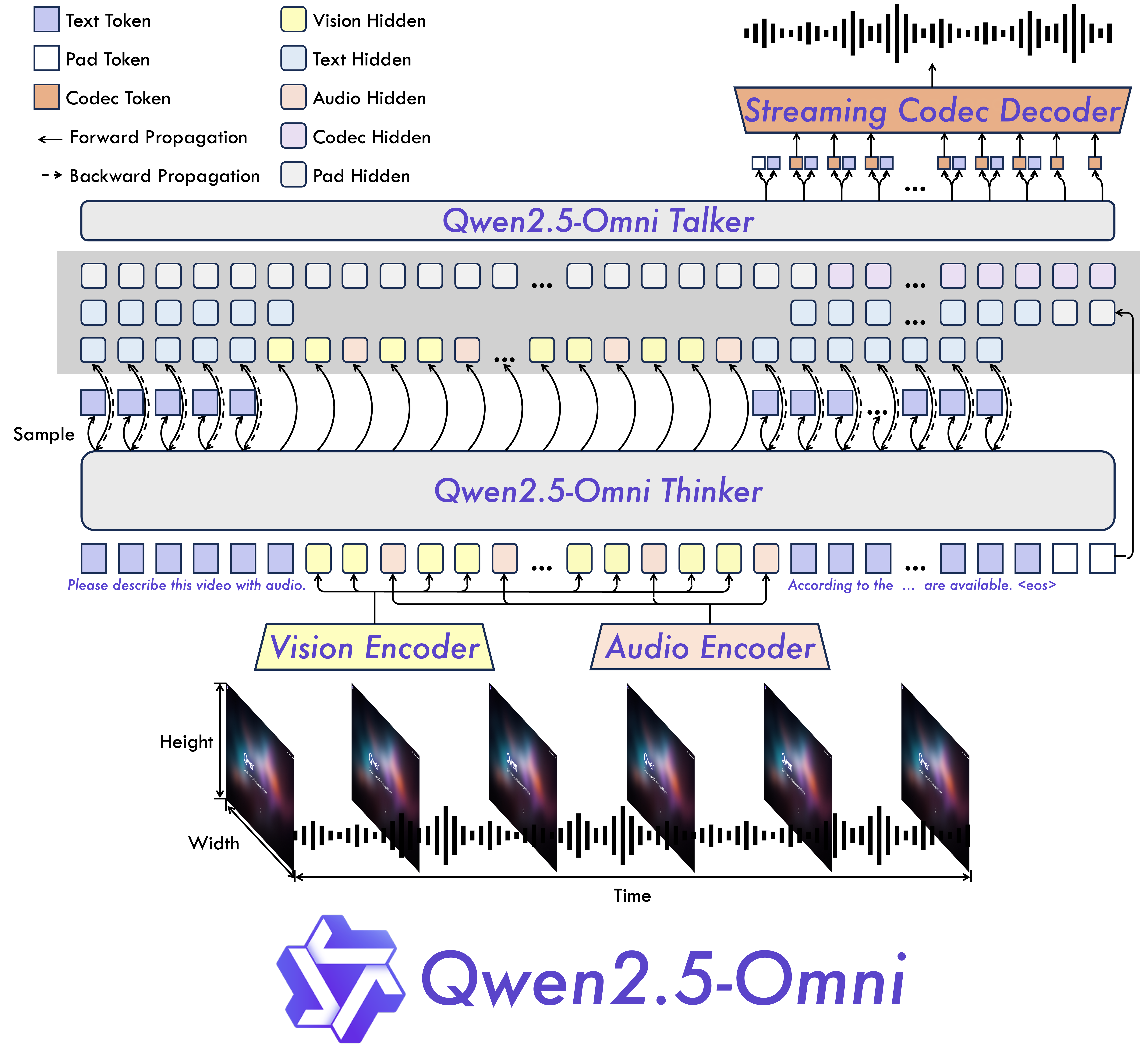 上图详细解析了Qwen2.5-Omni的核心技术架构,左侧展示了Thinker-Talker的并行计算流程,右侧则呈现了TMRoPE技术的时间对齐机制。这一技术框架充分体现了模型在时序建模上的突破,为处理复杂多模态时序数据提供了创新解决方案,帮助开发者理解模型底层工作原理。
上图详细解析了Qwen2.5-Omni的核心技术架构,左侧展示了Thinker-Talker的并行计算流程,右侧则呈现了TMRoPE技术的时间对齐机制。这一技术框架充分体现了模型在时序建模上的突破,为处理复杂多模态时序数据提供了创新解决方案,帮助开发者理解模型底层工作原理。
在语音交互方面,Qwen2.5-Omni的语音生成系统采用分层波形预测技术,在MOS(语音自然度评分)测试中达到4.4分(满分5分),超越了当前主流的VITS和FlowTTS等非流式语音合成方案。特别在噪声环境下的鲁棒性测试中,模型对-5dB信噪比的语音指令识别准确率仍保持91.3%,较行业平均水平提升27%,大幅扩展了语音交互的应用场景。
部署革命:4位量化技术让中端显卡焕发新生
针对多模态模型部署成本高昂的行业痛点,Qwen2.5-Omni-7B-AWQ版本采用先进的AWQ 4位量化技术,对Thinker模块的关键权重进行精准压缩。通过结合动态按需加载机制与智能CPU卸载策略,模型在保持95%以上性能的同时,将GPU显存占用降低70%,使拥有10GB显存的RTX 3080显卡即可流畅运行完整多模态功能。
性能测试显示,在RTX 4080显卡上,Qwen2.5-Omni处理1024x768分辨率图像的平均响应时间仅需0.8秒,生成60秒语音的延迟控制在2秒以内,视频帧处理速度达到30fps。这些指标均达到了实时交互的行业标准,使多模态AI应用从高端服务器走向普通PC成为现实。开发者可通过Gitcode获取量化模型权重,快速搭建本地开发环境。
在基准测试中,Qwen2.5-Omni展现出卓越的跨模态理解能力。在MMLU多任务语言理解测试中取得68.5%的准确率,与同尺寸文本模型相当;在语音指令跟随任务中,模型对"总结视频要点并生成讲解音频"等复合指令的完成度达到89%,证明其多模态推理能力已实现质的飞跃。
未来展望:多模态交互的产业化加速
Qwen2.5-Omni的发布不仅是技术突破,更重构了AI应用开发的成本结构。随着中端硬件可运行的多模态模型普及,智能客服、内容创作、教育培训等领域将迎来创新爆发。特别在远程协作、智能监控、辅助驾驶等需要实时多模态分析的场景,该模型有望催生一批颠覆性应用。
通义千问团队表示,Qwen2.5-Omni将持续优化多模态理解深度与响应速度,计划在未来版本中支持3D点云与传感器数据输入,进一步扩展模型的感知维度。随着量化技术的迭代,团队目标在年内实现入门级显卡的多模态运行能力,让全模态AI交互走进千家万户。
作为多模态大模型产业化的关键一步,Qwen2.5-Omni不仅展示了中国AI技术的领先实力,更为全球开发者提供了突破硬件限制的创新工具。在这场AI交互革命中,实时、自然、低成本的多模态能力,正成为驱动下一代智能应用的核心引擎。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0433
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0433 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0749
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0749 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0304
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0304 DeepAuditDeepAudit:人人拥有的 AI 黑客战队,让漏洞挖掘触手可及。国内首个开源的代码漏洞挖掘多智能体系统。小白一键部署运行,自主协作审计 + 自动化沙箱 PoC 验证。支持 Ollama 私有部署 ,一键生成报告。支持中转站。让安全不再昂贵,让审计不再复杂。Python05
DeepAuditDeepAudit:人人拥有的 AI 黑客战队,让漏洞挖掘触手可及。国内首个开源的代码漏洞挖掘多智能体系统。小白一键部署运行,自主协作审计 + 自动化沙箱 PoC 验证。支持 Ollama 私有部署 ,一键生成报告。支持中转站。让安全不再昂贵,让审计不再复杂。Python05
