服务健康评分新范式:Apache SkyWalking多维度加权算法解析
你是否还在为分布式系统的健康状态监控而烦恼?面对成百上千的微服务实例,如何快速识别潜在风险、量化服务健康程度,成为运维和开发团队的共同挑战。本文将深入解析Apache SkyWalking(分布式追踪系统,Application Performance Monitoring System)的服务健康评分算法,通过多维度指标加权模型,帮助你构建系统化的服务健康评估体系。读完本文后,你将掌握:
- 服务健康评分的核心指标体系与权重分配逻辑
- 动态阈值计算与异常检测的实现原理
- 如何通过SkyWalking告警插件配置自定义健康规则
- 多场景下的健康评分应用案例与最佳实践
健康评分算法基础架构
Apache SkyWalking的服务健康评分体系构建在其可观测性平台的核心能力之上。该平台通过Probes(探针)采集分布式系统的遥测数据,包括链路追踪(Tracing)、 metrics(指标)、日志(Logging)和事件(Event),经Platform backend(后端平台)聚合分析后,存储于可插拔的存储介质中,并通过UI层可视化呈现。
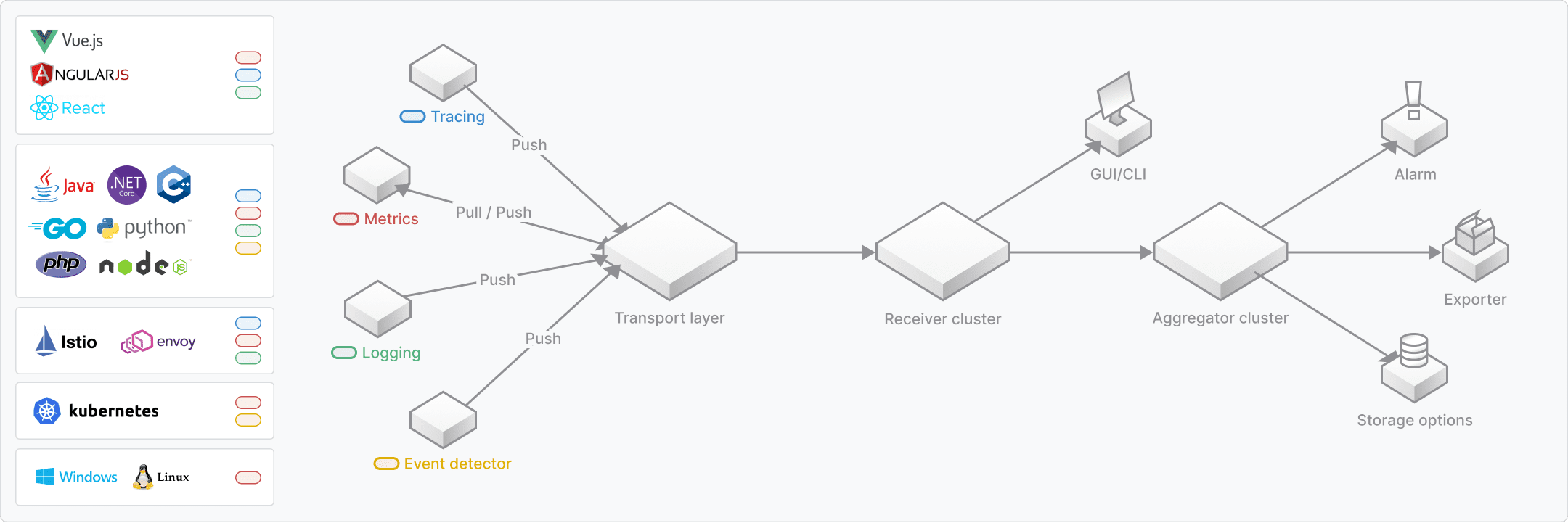
健康评分算法主要集成在后端分析模块,通过以下组件协同工作:
- 指标采集器:从服务实例(Service Instance)和端点(Endpoint)采集基础指标
- 加权计算引擎:基于预定义规则对多维度指标进行加权评分
- 动态阈值模块:结合历史数据计算基准线,实现自适应异常检测
- 告警触发机制:当评分低于阈值时触发通知流程
相关核心实现代码分布在以下模块:
- 指标处理核心逻辑:oap-server/server-core/
- 告警规则管理:oap-server/server-alarm-plugin/
- 多维度查询支持:oap-server/server-query-plugin/query-graphql-plugin/
核心指标体系与权重分配
SkyWalking健康评分算法采用层次化加权模型,将服务健康状态分解为三个层级的指标:服务可用性、性能指标和资源利用率,每个层级包含若干具体指标项,通过动态权重反映不同指标对整体健康度的影响程度。
指标层级结构
| 指标层级 | 包含指标项 | 基础权重 | 指标特性 |
|---|---|---|---|
| 服务可用性 | 服务响应率、端点错误率、实例在线率 | 40% | 直接反映服务是否可用的基础指标 |
| 性能指标 | 平均响应时间、P95延迟、吞吐量 | 35% | 衡量服务质量的核心参数 |
| 资源利用率 | CPU使用率、内存占用、JVM GC频率 | 25% | 反映基础设施支撑能力 |
表:服务健康评分指标层级与权重分配
动态权重调整机制
基础权重可通过配置文件调整,系统还会根据以下因素动态优化权重:
- 服务重要性:核心服务(如支付服务)的可用性权重自动提升20%
- 运行时状态:当资源使用率超过阈值时,对应权重临时增加15%
- 业务周期:高峰期自动提高性能指标权重,非高峰期增加资源利用率权重
权重调整的核心实现位于oap-server/mqe-rt/模块,通过MQE(Metric Query Expression)语法支持复杂的指标计算规则。例如,以下伪代码展示了权重动态调整的逻辑:
// 根据服务重要性调整权重
if (service.getPriority() == ServicePriority.CRITICAL) {
availabilityWeight *= 1.2; // 核心服务可用性权重提升20%
}
// 资源紧张时增加资源指标权重
if (resourceUsage.cpuUsage() > 80%) {
resourceWeight *= 1.15; // CPU使用率超阈值时资源权重提升15%
}
加权评分计算流程
健康评分计算采用百分制(0-100分),分数越高表示服务健康状态越好。计算流程分为四个步骤:指标标准化、指标评分、层级加权和整体评分校准。
计算流程图
graph TD
A[原始指标采集] --> B[指标标准化处理]
B --> C[单指标评分计算]
C --> D[层级加权汇总]
D --> E[动态因子校准]
E --> F[输出健康评分(0-100)]
F --> G{评分是否达标}
G -->|是| H[正常监控]
G -->|否| I[触发告警流程]
图:服务健康评分计算流程
关键计算步骤详解
-
指标标准化 将不同量纲的指标转换为0-100的标准分:
- 正向指标(如响应率):
标准分 = 实际值 / 目标值 * 100 - 负向指标(如错误率):
标准分 = (1 - 实际值/阈值) * 100
- 正向指标(如响应率):
-
层级加权汇总 按层级计算加权得分:
层级得分 = Σ(指标标准分 × 指标权重) 整体初步得分 = Σ(层级得分 × 层级权重) -
动态因子校准 应用动态调整因子:
最终得分 = 初步得分 × 服务重要性因子 × 时间周期因子
相关算法实现在oap-server/server-core/src/main/java/org/apache/skywalking/oap/server/core/analysis/metric/目录下,包含多种指标聚合器实现。
动态阈值与异常检测
SkyWalking健康评分算法的核心优势在于自适应基准线计算,通过历史数据建模实现动态阈值调整,避免静态阈值在系统负载变化时产生大量误报。
基准线计算模型
系统采用滑动窗口算法维护指标基准线:
- 时间窗口:默认7天(可配置)
- 样本数量:每小时采集20个样本点
- 偏差系数:1.5倍标准差(可通过配置调整)
基准线计算公式:动态阈值 = 历史平均值 + 偏差系数 × 标准差
多阶段异常检测
异常检测分为三个阶段:
- 单点异常检测:单个指标超出动态阈值时标记为异常点
- 关联异常分析:检查相关指标是否同时异常(如响应时间增加伴随错误率上升)
- 趋势异常识别:通过斜率检测发现指标的快速恶化趋势(如5分钟内响应时间增加300%)
异常检测的实现代码位于oap-server/analyzer/meter-analyzer/和oap-server/analyzer/event-analyzer/模块,结合了统计方法和简单的机器学习模型。
配置与自定义实践
SkyWalking允许通过配置文件自定义健康评分规则,适应不同业务场景需求。默认配置文件位于dist-material/alarm-settings.yml,包含基础评分规则和告警阈值设置。
基础配置示例
以下是健康评分规则的基础配置片段:
rules:
service_health_score:
metrics-name: service_health_score
op: "less"
threshold: 70 # 健康评分低于70分时触发告警
period: 10 # 每10秒计算一次
count: 3 # 连续3次低于阈值触发告警
silence-period: 5 # 告警静默期5分钟
weights:
availability: 40 # 可用性权重40%
performance: 35 # 性能指标权重35%
resource: 25 # 资源利用率权重25%
高级自定义场景
- 业务指标扩展:通过oap-server/server-configuration/添加自定义指标,如订单转化率
- 权重算法替换:实现IWeightCalculator接口自定义权重计算逻辑
- 多维度评分视图:通过oap-server/server-query-plugin/开发自定义评分dashboard
典型应用场景与最佳实践
微服务架构下的健康监控
在微服务环境中,SkyWalking健康评分可帮助识别"亚健康"服务——那些未完全故障但性能持续下降的服务实例。通过配置实例级评分视图,运维团队可以:
- 快速定位集群中评分最低的5个服务实例
- 分析评分下降的关联指标(如某个实例的GC频率突然增加)
- 自动触发实例重启或流量切换
混合云环境的统一健康视图
对于跨多云平台部署的服务,健康评分算法可:
- 标准化不同云平台的监控指标
- 基于网络延迟动态调整跨区域服务权重
- 结合云厂商SLA数据校准评分基准线
最佳实践建议
- 阶梯式告警配置:设置多级阈值(如70分警告、60分严重、50分紧急)
- 评分历史追踪:保留30天评分数据,用于趋势分析和容量规划
- 服务分组差异化:为核心服务和非核心服务设置不同的评分规则
- 定期校准基准线:系统重大变更后手动触发基准线重计算
相关配置示例可参考docker/docker-compose.yml中的监控栈部署配置,以及docs/en/concepts-and-designs/service-hierarchy.md中关于服务层级关系的说明。
总结与未来演进
Apache SkyWalking的服务健康评分算法通过多维度指标加权模型,为分布式系统提供了系统化的健康评估方法。其核心价值在于:
- 全面性:整合可用性、性能和资源三大维度的关键指标
- 适应性:动态权重和基准线实现自适应异常检测
- 可扩展性:支持自定义指标和评分规则扩展
未来版本计划引入更先进的机器学习模型,实现:
- 基于LSTM的异常预测(提前15分钟预测评分下降趋势)
- 服务依赖图谱的健康传播分析
- AIOps辅助的根因自动定位
通过本文介绍的健康评分算法,运维和开发团队可以构建更主动、智能的服务监控体系,将传统的"故障响应"模式升级为"健康管理"模式,最终提升整个分布式系统的可靠性和稳定性。
官方完整文档可参考:docs/en/ 算法实现细节可查阅:oap-server/
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0769
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0769 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0313
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0313 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
