阿里Wan2.2开源:MoE架构+消费级GPU,视频生成效率革命
导语
阿里巴巴通义万相团队正式开源新一代视频生成大模型Wan2.2,以创新的混合专家(MoE)架构和高压缩VAE技术,首次实现消费级GPU运行720P@24fps专业视频创作,重新定义AI视频生成的效率边界。
行业现状:视频生成的"算力困境"
2025年全球AI视频生成市场规模预计达7.17亿美元,年复合增长率维持在40%以上。当前行业呈现明显分化:谷歌Veo 3等闭源模型通过会员制(902元/月)提供高端服务,而开源方案普遍受限于算力门槛,多数模型停留在480P以下分辨率。传统广告制作中,15秒产品宣传片拍摄成本约2-5万元,采用"AI生成+人工配音"模式可使总成本下降45%,但专业级AI工具的高算力需求仍是中小企业的主要障碍。

如上图所示,Wan2.2的品牌标识体现了其技术定位——通过紫色几何图形与蓝色文字的组合,象征AI视频生成中"精准控制"与"创意自由"的平衡。这一设计理念也体现在模型架构中,通过模块化专家系统实现高效计算与高质量输出的统一。
核心技术突破:MoE架构重构视频生成范式
混合专家系统提升计算效率
Wan2.2采用创新的Mixture-of-Experts(MoE)架构,将视频生成的降噪过程分为两个阶段:高噪声专家专注早期整体布局,低噪声专家负责后期细节优化。每个专家模型约140亿参数,总参数达270亿但每次推理仅激活140亿,在相同计算成本下实现更高模型容量。通过信号噪声比(SNR)动态切换专家,确保在不同生成阶段调用最适合的模型组件。
消费级硬件适配方案
Wan2.2实现突破性硬件兼容性:
- 1.3B轻量版:仅需8.19GB显存,RTX 4090生成5秒480P视频约4分钟
- 14B专业版:支持720P高清视频生成,通过FSDP+USP技术实现8张消费级GPU协同工作
- 5B混合模型:支持720P@24fps文本/图像转视频,是目前最快的同级别模型之一
电影级美学控制系统
模型融入精细美学数据,支持精准控制光影、构图、对比度和色调等电影级风格参数。通过16×16×4高压缩比VAE架构,在保证720P分辨率的同时降低存储需求60%,使模型能同时处理角色动作、服装细节、光影变化等多维度信息。特别优化的I2V-A14B模型在"减少镜头抖动"指标上得分9.4,显著优于行业平均的7.8分。
开发实战:ComfyUI工作流部署指南
环境配置关键步骤
Wan2.2在ComfyUI框架中的部署需要特定依赖配置,核心包括:
- 下载ComfyUI源码:通过GitHub仓库获取as0.3.45版本,确保与模型兼容性
- 修改依赖文件:将requirements.txt中的torch版本指定为2.5.1
- 模型权重部署:按text_encoders、vae、diffusion_models等目录结构存放权重文件
- 插件安装:部署ComfyUI-WanVideoWrapper等专用节点,实现模型加载与推理控制
如上图所示,用户需从GitHub下载指定版本的ComfyUI源码,该页面提供了"Download ZIP"选项用于获取完整部署包。国内用户建议通过魔搭社区获取模型权重,可大幅提升下载速度。源码下载完成后需按照文档要求解压至容器指定目录,为后续依赖安装做准备。
核心节点配置
ComfyUI部署Wan2.2的核心节点包括:
- WanVideoModelLoader:加载主模型,支持多参数自定义
- WanVideoVAELoader:加载VAE模型,将潜变量转换为图像
- LoadWanVideoT5TextEncoder:加载文本编码器
- Get_start_image/Get_end_image:分别加载起始帧和结束帧图像
- WanVideoVACEStartToEndFrame:生成首帧与尾帧之间的动画帧集合
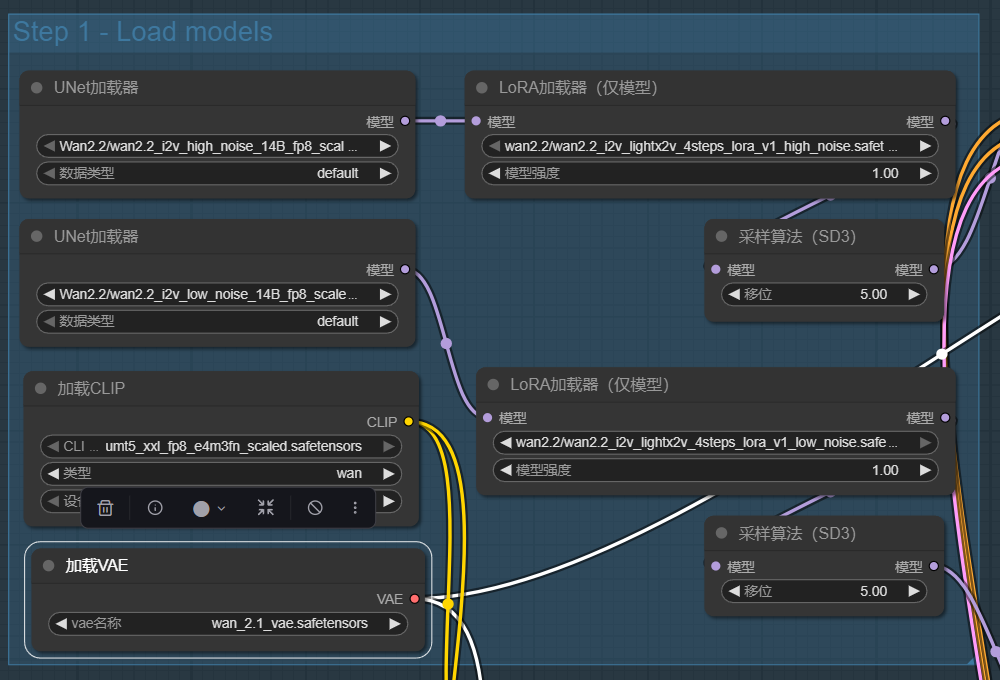
如上图所示,该工作流界面展示了Wan2.2模型加载的核心节点配置。通过模块化设计,用户可直观控制模型各组件的参数,包括采样步数(推荐20步高质量或4-6步快速模式)、分辨率设置(576×864平衡质量与效率)及Lora模型加载(用于特定风格迁移)。这种可视化工作流使非专业用户也能实现电影级视频生成。
行业影响:从"专业壁垒"到"全民创作"
创作门槛大幅降低
Wan2.2的开源特性已形成活跃社区生态,Phantom项目基于其开发了单主体/多主体参考生成框架,UniAnimate-DiT则训练了专用人物动画模型。这种协作模式使中小企业首次具备专业级视频创作能力:
- 婚庆公司:将客户照片转为动态纪念视频
- 教育机构:快速制作课程动画,降低知识可视化成本
- 电商卖家:实现商品展示视频批量生成,提升转化率
商业模式创新加速
开源视频模型正催生新商业模式:有创业者通过提供Wan2.2定制化服务,3个月内实现17万元营收。某MCN机构采用"AI生成+人工审核"流水线,将短视频生产成本从每条300元降至15元,日产量提升至5000条以上。行业数据显示,采用AI视频方案的企业平均内容生产效率提升300%。
技术伦理与规范挑战
随着生成能力提升,内容合规问题凸显。Wan2.2团队实施四步数据清洗流程过滤违规内容,但开源特性也带来滥用风险。行业正形成自律机制,如生成内容水印系统、AI生成检测工具等,为平衡创新与安全提供参考范式。

如上图的LMArena排行榜所示,Wan2.2作为开源模型代表,在性能上已接近部分闭源商业模型。这种技术民主化趋势正在重塑视频创作产业格局——从少数科技巨头垄断,转向开放社区协作创新。随着模型持续优化,预计2026年将出现消费级GPU生成4K电影级视频的能力,进一步模糊专业与业余创作的界限。
未来展望:视频生成的下一个前沿
短期来看,Wan2.2将沿着双轨发展:计划推出的优化版本将进一步提升生成速度30%,ComfyUI插件将实现"一键生成"复杂场景。长期而言,视频生成模型正朝着"世界模型"演进——通过整合物理引擎、知识图谱和多模态理解,未来有望实现"拍摄完整科幻短片"等复杂任务。
对于企业而言,现在正是布局AI视频能力的关键窗口期。建议内容团队评估Wan2.2等开源方案,建立内部AIGC工作流;技术团队关注模型微调与垂直领域优化;决策者则需制定"AI+视频"战略,把握成本重构带来的商业机遇。
项目获取与社区资源
Wan2.2模型已在GitCode开源,仓库地址:https://gitcode.com/hf_mirrors/Wan-AI/Wan2.2-T2V-A14B-Diffusers。社区提供完整的安装教程、模型权重下载及问题解答,支持文本生成视频(T2V)、图像生成视频(I2V)、视频编辑等全栈式创作需求。建议通过官方Discord或微信社群获取最新技术动态与应用案例。
提示:模型部署需注意硬件兼容性,推荐使用RTX 4090或同级别GPU以获得最佳体验。商业应用请遵守Apache 2.0开源协议,确保合规使用生成内容。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00
MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00 awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05
awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05 banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
热门内容推荐

最新内容推荐
