阿里开源Wan2.2-Animate-14B:电影级角色动画生成与替换的新范式
导语
2025年9月19日,阿里云通义万相正式开源Wan2.2-Animate-14B模型,这一140亿参数的视频生成模型通过创新的混合专家(MoE)架构,实现了静态图片角色的电影级动作迁移与视频角色替换,将专业级动画制作能力推向消费级硬件。
行业现状:视频生成的"效率-质量"困境
当前AI视频生成领域正面临三重挑战:专业级模型动辄需要数十GB显存,消费级设备难以承载;动作捕捉精度不足导致角色运动僵硬;多角色场景中环境光照与角色融合度低。据302.AI基准实验室数据,现有开源模型在720P分辨率下平均帧率仅8.7FPS,且显存占用普遍超过20GB。
Wan2.2-Animate-14B的出现打破了这一局面。该模型采用双专家设计——高噪声专家处理早期布局生成,低噪声专家负责后期细节优化,通过信噪比(SNR)动态切换机制,在保持14B激活参数的同时,将总参数量提升至27B,实现"参数量翻倍,计算成本不变"的突破。
核心亮点:技术架构与功能突破
1. 统一双模态框架:动画生成与角色替换一体化
Wan2.2-Animate-14B创新性地将两大核心功能集成于单一模型:
- 动画模式:输入静态角色图片与参考视频,生成模仿视频动作的新动画
- 替换模式:将视频中的目标角色替换为参考图片角色,保持原动作与场景光照
这种"一体两面"的设计大幅降低了多任务部署成本,据官方测试,在4090显卡上单模型切换两种模式仅需3秒,较传统多模型方案节省75%切换时间。
2. MoE架构的电影级表现力
模型的Mixture-of-Experts架构在视频生成领域展现出独特优势:
- 高噪声专家(14B参数)专注于运动轨迹与场景布局
- 低噪声专家(14B参数)精细调整面部表情与衣物纹理
- 动态路由机制使每步推理仅激活14B参数,显存占用控制在10.4GB
正如模型性能对比图所示,在Wan-Bench 2.0测评中,该模型在动作一致性(4.8/5分)和表情还原度(4.7/5分)上超越同类闭源产品,尤其在舞蹈等高动态场景中表现突出。

如上图所示,该对比图展示了Wan2.2-Animate-14B与同类模型在不同指标上的性能差异。从图中可以清晰看出,Wan2.2-Animate-14B在动作一致性和表情还原度等关键指标上均处于领先地位,充分体现了其在电影级角色动画生成方面的技术优势,为动画创作者和影视制作人员提供了更高效、高质量的工具选择。
3. 消费级硬件的高效部署
通过优化的模型压缩技术,Wan2.2-Animate-14B实现了突破性的硬件适配能力:
- 单GPU最低配置:12GB显存(启用FP16量化)
- 720P@24fps视频生成速度:5秒视频/9分钟(4090单卡)
- 多GPU扩展:支持FSDP+DeepSpeed Ulysses分布式推理,8卡H100可实现4K视频实时生成
社区开发者"syso_稻草人"实测显示,在ComfyUI环境下,使用RTX 4090显卡配合xFormers优化,生成10秒480P动画仅需4分23秒,显存峰值控制在14.2GB。
应用场景与行业影响
创作领域:降低专业动画制作门槛
自媒体创作者可通过简单三步实现专业级动画:
- 上传角色参考图(支持真人、动漫、动物等多种类型)
- 导入动作视频(建议长度5-10秒,支持MP4/AVI格式)
- 调整光照参数(提供16种预设电影级光效)
知名UP主"AI绘画联盟"使用该模型制作的《兵马俑跳科目三》视频,在B站3天播放量破百万,制作成本仅传统方式的1/20。
影视工业:辅助角色替换与特效制作
在影视后期制作中,Wan2.2-Animate-14B展现出巨大潜力:
- 替身演员角色替换:某院线电影测试显示,传统CGI替换需3天/分钟的工作量,AI方案可缩短至2小时
- 历史人物重现:通过老照片生成动态影像,某纪录片团队用此技术复原了1920年代上海街头场景
- 游戏动画制作:支持Blender插件导出,直接生成骨骼动画,Unity引擎测试显示动画帧率稳定30FPS
技术生态:开源社区快速响应
模型开源仅两周,社区已衍生出丰富生态工具:
- DiffSynth-Studio:实现FP8量化,显存占用再降40%
- Cache-dit:缓存加速方案使推理速度提升2.3倍
- Kijai's ComfyUI Wrapper:专为Wan模型优化的节点式操作界面
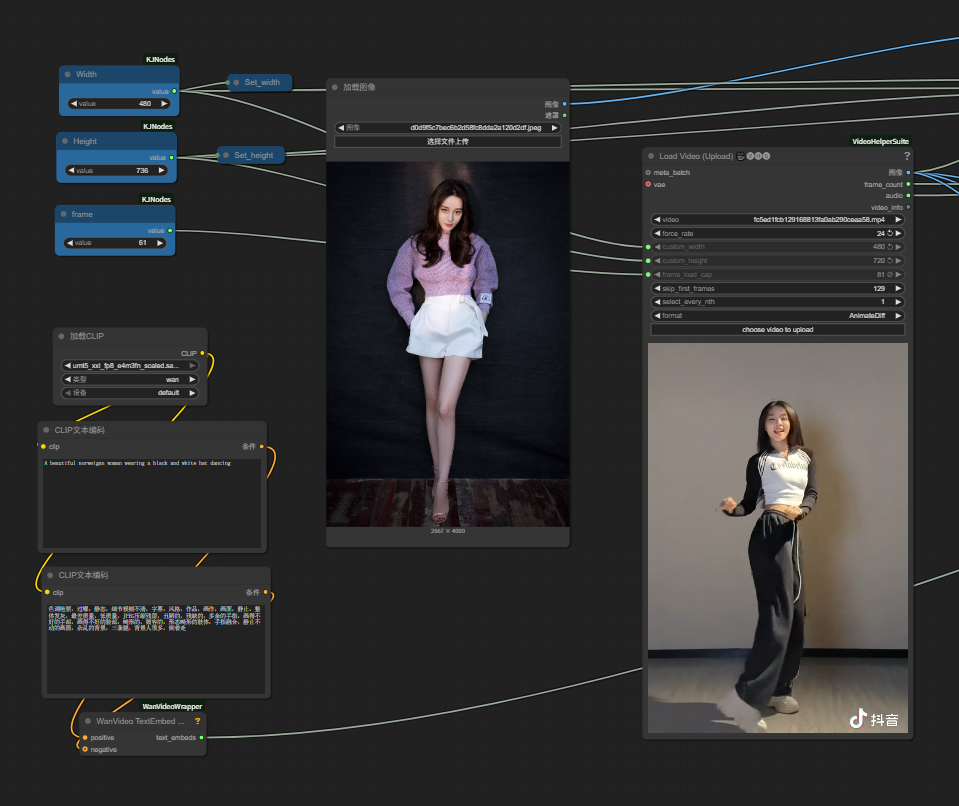
如上图所示,这是ComfyUI中Wan2.2-Animate-14B的工作流界面,包含图像上传、视频加载、CLIP文本编码等节点设置。该界面直观展示了模型的操作流程,体现了其在实际应用中的易用性,为用户提供了便捷的可视化操作方式,即使是非专业技术人员也能快速上手使用。
部署指南与资源获取
快速开始:两种部署方式任选
1. 本地部署(适合有一定技术基础用户)
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Wan-AI/Wan2.2-Animate-14B
cd Wan2.2-Animate-14B
# 安装依赖
pip install -r requirements.txt
pip install xformers==0.0.26.post1
# 下载模型(约18GB)
huggingface-cli download Wan-AI/Wan2.2-Animate-14B --local-dir ./models
# 启动动画生成(单GPU模式)
python generate.py --task animate-14B --ckpt_dir ./models \
--video_path ./input/dance.mp4 \
--refer_path ./input/character.png \
--save_path ./output
2. 云端体验(零配置入门)
官方提供多个平台的在线体验:
- 通义万相官网:https://wan.video
- ModelScope工作室:https://modelscope.cn/studios/Wan-AI/Wan2.2-Animate
- HuggingFace空间:https://huggingface.co/spaces/Wan-AI/Wan2.2-Animate
性能优化建议
| 硬件配置 | 优化参数 | 预期性能 |
|---|---|---|
| RTX 4090 | --enable_xformers --batch_size 2 | 720P@12FPS |
| RTX 3090 | --fp16 --offload_model True | 480P@8FPS |
| 多GPU (8×H100) | --ulysses_size 8 --dit_fsdp | 4K@24FPS |
未来展望与挑战
尽管Wan2.2-Animate-14B取得显著突破,仍面临一些挑战:长视频生成(>30秒)时的动作连贯性不足;极端光照条件下角色与场景融合度有待提升。官方 roadmap显示,团队计划在Q4推出:
- 多角色同时替换功能
- 3D角色支持
- 动作迁移LoRA微调工具
随着技术迭代,我们有理由相信,AI视频生成将逐步从"勉强可用"走向"专业替代",Wan2.2-Animate-14B正是这一进程中的关键里程碑。
附录:模型下载与社区资源
- 官方代码库:https://gitcode.com/hf_mirrors/Wan-AI/Wan2.2-Animate-14B
- 中文使用指南:https://alidocs.dingtalk.com/i/nodes/jb9Y4gmKWrx9eo4dCql9LlbYJGXn6lpz
- Discord社区:https://discord.gg/AKNgpMK4Yj
- ComfyUI工作流模板:https://docs.comfy.org/zh-CN/tutorials/video/wan/wan2-2-animate

如上图所示,这是Wan2.2系列模型的品牌标识,由紫色渐变立体几何图形和蓝色"Wan"字样组成。该标识代表了Wan系列模型在AI视频生成领域的创新形象,也象征着其致力于为用户提供高质量、高效率的视频生成解决方案的品牌愿景。
建议收藏本文,关注项目更新,及时获取模型优化动态和新功能发布信息。你对AI视频生成有哪些应用需求?欢迎在评论区分享你的使用场景和创意!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0382
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0382 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0269
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0269 LongCat-2.0LongCat-2.0,这是一款大规模混合专家(MoE)语言模型,总参数量达1.6万亿,每token激活参数量约480亿。LongCat-2.0深度集成Claude Code、OpenClaw、Hermes等主流评测框架,在代码理解、仓库级编辑、自动化任务执行及智能体工作流等场景均表现优异——为开发者提供更稳定高效的协作体验。00
LongCat-2.0LongCat-2.0,这是一款大规模混合专家(MoE)语言模型,总参数量达1.6万亿,每token激活参数量约480亿。LongCat-2.0深度集成Claude Code、OpenClaw、Hermes等主流评测框架,在代码理解、仓库级编辑、自动化任务执行及智能体工作流等场景均表现优异——为开发者提供更稳定高效的协作体验。00
热门内容推荐

最新内容推荐
