探索SprayHound:安全高效地探索AD权限路径
在网络安全领域,理解和探索企业的内部结构是一项至关重要的任务,尤其是当涉及到Active Directory(AD)这样的复杂环境时。今天,我们将深入介绍一个名为SprayHound的开创性工具——它不仅为安全研究人员提供了强大而安全的密码喷洒功能,还能够与Bloodhound无缝协作,揭示通往Domain Admins之路的神秘面纱。
项目介绍
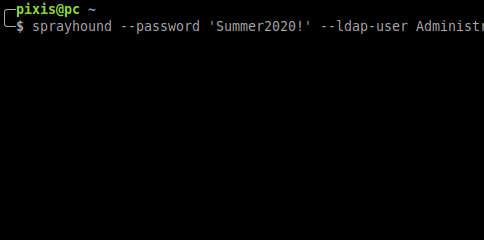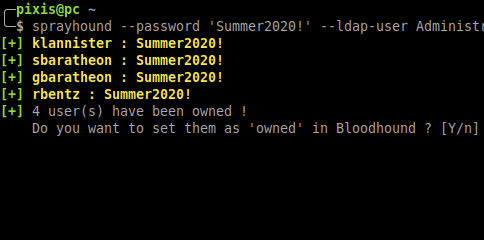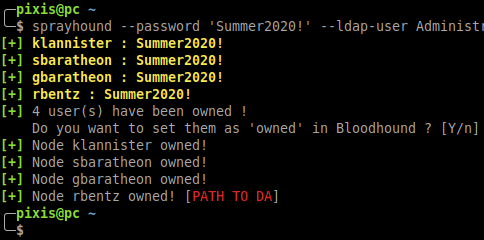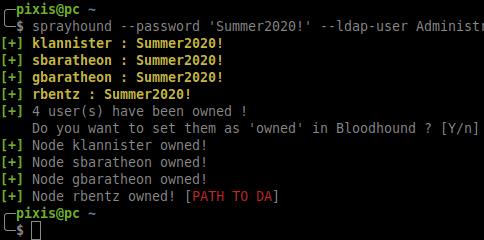
SprayHound,目前处于积极开发中,是一个专为Python设计的强大库。它的核心目的是使安全专家能够在维持高安全性标准的同时,有效地对AD环境进行密码喷洒测试。通过它的帮助,你可以安全地验证潜在的弱密码,同时利用Bloodhound的图形化拓扑,将已攻破的账户标记为“已拥有”,进而策略性地规划通往最高权限的路线。
项目技术分析
SprayHound采用了巧妙的技术架构,确保了操作的安全性和效率:
-
智能密码喷洒:与其他可能触发警报的喷洒工具不同,SprayHound设计了一种更加微妙且难以被检测的方式执行密码喷洒,减少了被防护系统捕捉的风险。
-
Bloodhound集成:该工具直接与Bloodhound的数据模型对接,允许用户直观地看到哪些账户已被成功“喷洒”,并分析这些账户如何成为通往域管理员的跳板。这种整合极大地增强了攻击模拟和路径规划的能力。
-
健壮的日志记录和反馈机制:SprayHound不仅执行操作,还详细记录过程,为后续分析提供宝贵数据,帮助用户理解每一步的成效。
项目及技术应用场景
对于企业和安全研究团队而言,SprayHound是评估自身AD环境安全性的宝贵工具:
-
安全审计:企业可以使用SprayHound来识别和修复潜在的薄弱环节,增强其AD环境的安全防御。
-
渗透测试:安全咨询公司或红队可以借助SprayHound更准确地模拟真实世界的攻击场景,评估组织的抵抗能力。
-
教育与培训:网络安全课程中,SprayHound可用于教学目的,帮助学生理解AD安全的重要性和复杂的访问控制逻辑。
项目特点
-
安全优先:在实施敏感操作时始终将不引起不必要的注意放在首位。
-
兼容性强:与Bloodhound的深度整合使得分析结果一目了然,无需额外的中间步骤。
-
易于使用:Python语言的广泛接受度加上清晰的文档,降低了学习曲线,即便是新手也能迅速上手。
-
灵活可扩展:开放源代码鼓励社区贡献,使得SprayHound能够不断进化,适应新的安全挑战。
综上所述,SprayHound不仅是网络安全领域的强大新兵,更是提升组织安全意识、加强AD管理不可或缺的工具。无论是专业安全研究者还是IT管理人员,都不应错过这个能够深入了解和加固自己AD环境的机会。立即探索SprayHound,解锁更深层次的网络权限控制之道!
# 探索SprayHound:安全高效地探索AD权限路径
SprayHound,正处于积极开发中的Python库,旨在安全执行Active Directory的密码喷洒测试,并结合Bloodhound优化域内权限路径发现。通过智能操作和与Bloodhound的无缝对接,SprayHound为网络安全专家开启了一扇高效评估与规划的窗口。
- **智能且安全的密码喷洒**
- **Bloodhound集成,助力权限路径可视化**
- **详尽日志支持深度分析**
适用于安全审计、渗透测试与教育训练,SprayHound以其独特优势,成为了保护和强化AD安全的得力助手。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0769
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0769 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0313
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0313 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
