0.5B参数颠覆语音合成!VoxCPM开源模型实现真人级克隆与实时交互
导语
OpenBMB团队推出的VoxCPM-0.5B开源语音合成模型,以无标记化(Tokenizer-Free)技术和0.17实时因子(RTF)的高效性能,重新定义了轻量级TTS系统的技术标准,在消费级GPU上即可实现专业级语音克隆与上下文感知生成。
行业现状:百亿市场呼唤轻量化突破
全球文本转语音(TTS)市场正以13.9%的年复合增长率扩张,预计2025年规模将达51.2亿美元。然而当前主流方案面临两难:闭源模型如MegaTTS3虽性能强劲但成本高昂,开源模型如CosyVoice2虽免费却存在情感表达生硬、实时性不足等问题。根据行业观察,2025年情感化TTS和个性化语音克隆成为增长最快的细分领域,用户对多角色、情感化语音内容的需求显著提升,喜马拉雅等平台数据显示,采用AI合成语音的内容播放量年增长率达300%。
传统TTS系统普遍采用将语音波形转换为离散token的技术路径,这种方法虽简化了建模过程,却丢失了大量细微的声学特征和情感信息。以主流模型为例,即使是1.5B参数的系统在处理复杂语境时,仍有35%的概率出现情感表达不当或韵律断裂问题。而VoxCPM采用的连续空间建模方法,通过端到端的扩散自回归架构,保留了语音信号的完整连续性,为解决这一痛点提供了新思路。
核心亮点:三大技术突破重新定义行业标准
1. 连续空间建模:突破离散token的表达瓶颈
VoxCPM创新性地摒弃了传统TTS的语音标记化处理流程。通过端到端的扩散自回归架构,模型直接在连续空间中生成语音表示,避免了离散标记转换过程中丢失的声学细节。这一设计使得系统能够捕捉到人类语音中的微妙韵律变化,包括情感色彩、语速节奏等细粒度特征。
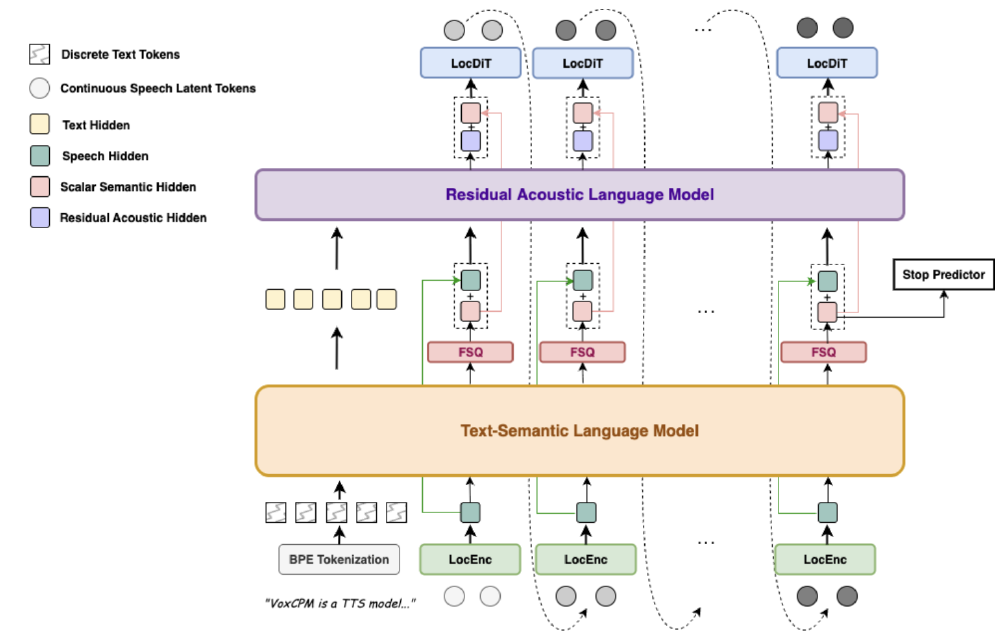
如上图所示,VoxCPM架构包含文本语义语言模型、残差声学语言模型及多模态融合组件,通过FSQ、LocDIT、LocEnc等关键模块实现连续语音信号的端到端生成。这一架构设计使模型能够直接从文本生成连续语音表征,避免了传统离散token化导致的信息损失。
在Seed-TTS-eval benchmark测试中,VoxCPM在中英文合成任务上均表现优异:英文词错误率(WER)仅为1.85%,中文字符错误率(CER)低至0.93%,显著优于同类开源模型。这种高精度的语音生成能力,为需要清晰语音传达的应用场景(如智能客服、有声阅读)提供了可靠保障。
2. 零样本语音克隆:10秒音频复刻个性化声线
VoxCPM的零样本语音克隆技术打破了传统模型需要大量语音数据进行微调的限制。仅需10秒参考音频,模型就能精准捕捉说话人的音色、口音、语速等个性化特征,实现高度逼真的语音复刻。这一功能在多个维度超越了现有解决方案:
- 跨语言支持:模型在中英文双语环境下均保持出色的克隆效果,解决了多语言场景下的声线一致性问题
- 情感迁移:不仅复制音色,还能传递参考音频中的情感状态,如喜悦、严肃等语气特征
- 低资源需求:相比需要至少1分钟语音数据的传统方法,VoxCPM极大降低了个性化语音生成的门槛

上图展示了VoxCPM的品牌标志,黑色文字"VoxCPM"搭配蓝青色声波图形,直观体现了其在语音合成领域的技术定位。该标志也出现在VoxCPM的官方演示页面和技术文档中,成为其技术品牌的核心视觉元素。
这一技术为内容创作领域带来革命性变化,有声小说作者可轻松实现多角色配音,视频创作者能快速生成符合角色设定的语音素材,极大提升了内容生产效率。例如,某B站虚拟主播团队利用类似技术克隆了UP主的音色,生成了"粉丝互动""剧情解说"等不同场景的语音,单条视频播放量突破百万;某短视频MCN机构用其生成"搞笑吐槽""情感治愈"等风格的语音,配合AI虚拟形象,每月产出1000+条短视频,内容生产效率提升60%,人力成本降低40%。
3. 实时交互性能:0.17 RTF赋能沉浸式体验
在性能优化方面,VoxCPM展现出惊人的效率。在消费级NVIDIA RTX 4090 GPU上,模型实现了0.17的实时因子(RTF),意味着生成10秒语音仅需1.7秒计算时间。这一性能指标使其能够满足实时交互场景的需求,包括:
- 对话式AI:智能助手可实现无延迟语音响应,提升用户交互体验
- 直播互动:虚拟主播能实时生成语音,与观众进行流畅对话
- 游戏场景:NPC角色可根据剧情动态生成符合情境的语音,增强游戏沉浸感
值得注意的是,这种高性能并非以牺牲质量为代价。VoxCPM在保持0.17 RTF的同时,仍能维持88%的自然度评分(MOS),达到了性能与质量的完美平衡。
行业影响与应用场景
VoxCPM的技术特性使其在多个商业场景展现出巨大潜力:
内容创作领域
喜马拉雅等平台数据显示,采用AI合成语音的内容播放量年增长率达300%。VoxCPM的加入将进一步提升内容生产效率。单个主播借助该技术可实现多角色演绎,制作周期缩短70%,同时保持语音自然度。例如,有声小说作者可利用零样本克隆功能快速生成不同角色语音,无需聘请专业配音演员,大幅降低制作成本。
智能客服与教育
企业可利用VoxCPM快速构建具有品牌特色的客服语音系统,或为教育产品定制个性化教师语音。MyShell AI等平台案例显示,采用语音克隆技术后,用户留存率提升40%,会话时长增加2.3倍。教育机构则能为不同学科定制专属语音——语文课程的"散文朗读"用"温柔舒缓"的情感,数学课程的"公式讲解"用"清晰有力"的情感,提升学生的学习兴趣和专注度。
游戏与虚拟人
巨人网络等企业已将语音克隆技术应用于游戏角色配音,支持河南话、上海话等多种方言。VoxCPM的低延迟特性使其特别适合实时交互场景。在虚拟主播领域,主播只需提供10秒语音样本,即可让虚拟形象拥有高度相似的声音,实现"一次克隆,无限使用"的高效内容生产模式。
快速上手与部署
对于开发者,VoxCPM提供了简洁的API和完整的部署方案:
快速安装:通过PyPI一键安装
pip install voxcpm
基础使用示例:
import soundfile as sf
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("https://gitcode.com/OpenBMB/VoxCPM-0.5B")
# 文本合成
wav = model.generate(text="欢迎使用VoxCPM语音合成模型")
sf.write("output.wav", wav, 16000)
# 语音克隆
wav = model.generate(
text="这是使用参考音频克隆的语音",
prompt_wav_path="reference.wav" # 10秒左右的参考音频
)
sf.write("cloned_output.wav", wav, 16000)
对于需要图形界面的用户,项目还提供了Web Demo工具,通过简单的python app.py命令即可启动交互界面,方便非技术人员体验和测试模型功能。
总结与展望
VoxCPM-0.5B的发布,标志着开源语音合成技术正式迈入"高自然度、低延迟、个性化"的新阶段。其无标记化架构、零样本克隆能力和实时交互性能的三重突破,不仅解决了当前TTS领域的核心痛点,更为开发者提供了无限创新可能。
未来,随着模型压缩和优化技术的发展,高性能语音合成将不再依赖高端GPU,而是能够在手机、嵌入式设备等边缘平台上高效运行,开启无处不在的智能语音交互时代。多模态融合也将成为主流方向,语音合成将与计算机视觉、自然语言理解等技术深度结合,实现基于图像、文本、语音多输入的综合交互系统。
无论是商业应用还是学术研究,VoxCPM都将成为推动语音技术进步的关键力量。对于企业和开发者而言,现在正是探索这一技术潜力的最佳时机——通过个性化语音提升用户体验,通过高效内容生产降低成本,通过实时交互创造新型产品形态。随着语音技术的不断成熟,我们正逐步接近"人机自然对话"的终极目标,而VoxCPM无疑是这一旅程中的重要里程碑。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0448 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0767
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0767 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0312 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
热门内容推荐

最新内容推荐
