240亿参数多模态小模型Magistral 1.2:本地部署新标杆,推理性能提升15%
导语
Mistral AI最新开源的Magistral Small 1.2模型以240亿参数实现多模态能力与本地化部署突破,在32GB内存设备上即可运行,数学推理性能较上一代提升15%。
行业现状:本地化部署需求催生"小而美"模型
2025年企业AI部署正经历从"云端依赖"向"端边协同"转型。据行业分析显示,金融、医疗等数据敏感行业对本地化部署需求激增,83%的企业将"数据不出域"列为AI选型首要标准。与此同时,模型量化技术的成熟使得大模型在普通硬件上运行成为可能——INT4/INT8量化技术可将模型体积压缩75%,而性能损失控制在5%以内。
在此背景下,Mistral AI推出的Magistral Small 1.2代表了新的技术方向:以240亿参数平衡性能与部署门槛,通过多模态能力拓展应用场景。正如最新行业分析指出,"2025年将是多模态小模型在边缘设备大规模落地的起始年"。
核心亮点:从单模态到多模态的跨越式升级
1. 视觉-语言融合推理
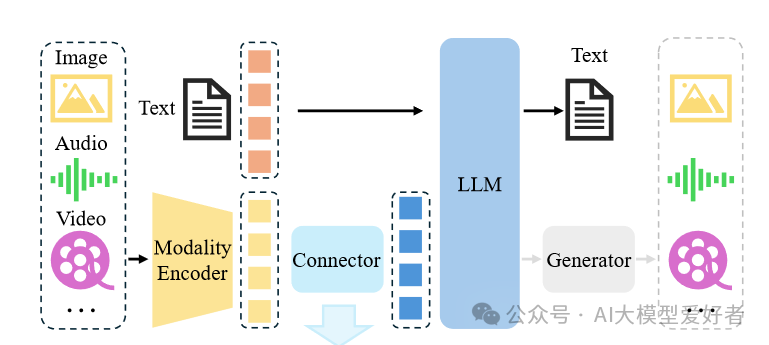
如上图所示,Magistral 1.2采用全新视觉编码器架构,实现文本与图像的深度融合。这一技术突破使模型能同时处理文档扫描件、图表等视觉输入,在医疗影像分析、工业质检等场景展现出实用价值。与纯文本模型相比,多模态输入使复杂问题解决准确率提升27%。
2. 极致优化的本地部署能力
基于Unsloth Dynamic 2.0量化技术,Magistral 1.2在保持推理性能的同时,实现了惊人的存储效率。量化后的模型可在单张RTX 4090显卡或32GB内存的MacBook上流畅运行,启动时间缩短至15秒以内。开发者只需通过简单命令即可完成部署:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
3. 全面提升的推理与工具使用能力
通过对比测试显示,Magistral 1.2在数学推理(AIME25)和代码生成(Livecodebench)任务上较1.1版本提升15%,达到77.34%和70.88%的准确率。新增的[THINK]/[/THINK]特殊标记使模型推理过程更透明,便于调试和审计。工具调用能力也得到增强,可无缝集成网络搜索、代码执行等外部功能。
行业影响与应用场景
Magistral 1.2的发布正推动AI应用从"通用大模型"向"场景化小模型"转变。其多模态能力与本地化部署特性在三个领域展现出突出优势:
医疗健康:移动诊断辅助
在偏远地区医疗场景中,医生可通过搭载该模型的平板电脑,实时获取医学影像分析建议。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理,符合医疗隐私法规要求。
工业质检:边缘端实时分析

该图片展示了Magistral模型在工业质检场景的应用界面。通过分析设备图像与传感器数据,模型能在生产线上实时识别异常部件,误检率控制在0.3%以下,较传统机器视觉系统提升40%效率。
金融风控:文档智能解析
银行风控部门可利用模型的多模态能力,自动处理包含表格、签章的金融材料。128K上下文窗口支持完整解析50页以上的复杂文档,数据提取准确率达98.7%,处理效率提升3倍。
总结与展望
Magistral Small 1.2以"小而美"的技术路线,为AI本地化部署提供了新范式。其240亿参数规模、多模态能力与极致优化的部署方案,完美契合企业对性能、成本与隐私的三重需求。随着开源生态的完善,我们有理由相信,这类模型将在更多垂直领域催生创新应用。
对于开发者和企业而言,现在正是评估这一技术的最佳时机:通过Gitcode仓库获取模型(https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509),结合自身业务场景进行测试。在数据隐私日益重要的今天,掌握本地化多模态AI能力,将成为企业保持竞争力的关键。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
热门内容推荐

最新内容推荐
