SeedVR-7B:字节跳动开源视频修复黑科技,效率提升18倍重塑行业标准
导语:0.8秒修复1080P视频,SeedVR-7B让超高清修复成本直降90%
行业现状:超高清时代的质量与成本困境
2025年全球超高清视频产业迎来爆发期,主流媒体已全面开播4K频道,带动超高清内容需求激增。但行业面临严峻挑战:传统视频修复技术存在三重矛盾——专业级工具处理10秒视频需耗时5分钟以上,消费级软件则难以突破720P画质天花板,而监控安防、老旧影像修复等场景又要求同时满足实时性与高分辨率。
市场研究显示,全球AI视频处理软件市场正以31%的年复合增长率扩张,预计2030年规模将达10.8亿美元,效率优化成为行业突围关键。在这样的背景下,字节跳动开源的SeedVR-7B模型通过彻底重构扩散模型架构,将1080P视频修复时间从传统方法的15秒压缩至0.8秒,同时将计算成本降低90%,重新定义了视频修复行业的效率标准。
核心亮点:三大技术革新实现效率飞跃
自适应窗口注意力机制:高分辨率修复的"防颤抖"技术
SeedVR-7B创新的自适应窗口机制可动态调整窗口大小(8×8至24×24像素),使细节保真度提升40%。该机制通过实时匹配目标区域尺寸,解决了高分辨率场景下的特征不一致问题,尤其在处理快速运动画面时表现出色。
传统固定窗口注意力机制在处理1080P视频时会产生"棋盘效应",而自适应窗口注意力机制使得窗口大小可以根据输入分辨率动态调整,提升了窗口注意力在处理任意尺寸高分辨率输入时的鲁棒性。
一步式推理优化:从"多步炼丹"到"一键出片"
通过扩散对抗后训练技术,SeedVR-7B将传统扩散模型的50步去噪过程压缩为单步操作。官方测试数据显示,在RTX 3090显卡上处理1080P视频仅需0.8秒,而显存占用仅8GB,相比同类扩散模型的24GB需求降低67%。这种效率提升使得普通PC也能完成专业级视频修复任务。
SeedVR-7B从使用64个采样步数的教师模型开始,以步长为2渐进地将学生模型蒸馏为一步模型。每一次蒸馏过程大约进行10K次迭代,使用简便的均方误差损失,最终实现了一步式推理的突破。
因果视频变分自编码器:降低计算成本的关键
SeedVR-7B结合了因果视频变分自编码器(CVVAE),通过时间和空间压缩降低计算成本,同时保持高重建质量。基于大规模图像和视频的联合训练及多阶段渐进式训练策略,SeedVR在多个视频修复基准测试中表现出色,尤其在感知质量方面,能够生成具有真实感细节的修复视频,且速度优于现有方法。
性能对比:重新定义行业基准
SeedVR-7B在多项关键指标上全面超越现有技术:
- 处理速度:1080P视频修复仅需0.8秒/帧,较传统方法提升18倍
- 计算成本:硬件需求降低67%,单路视频修复成本从1.2元/分钟降至0.12元/分钟
- 画质表现:PSNR达32.5dB,SSIM达0.92,LPIPS低至0.08,均优于同类模型

如上图所示,该图表展示了SeedVR模型处理前后的图像对比及不同视频修复方法的性能评估,包括Runtime和DOVER-T指标及细节特写对比。从图中可以清晰看出SeedVR在处理速度和修复质量上的双重优势,特别是在细节还原方面表现突出。
技术架构:Swin-MMDiT模块的创新设计
SeedVR-7B采用扩散变换器(DiT)架构,其核心创新在于基于MM-DiT主干网络构建的Swin-MMDiT模块。该模型摒弃传统低级视觉任务常用的8×8像素空间窗口注意力机制,转而在8×8压缩潜空间实施64×64大窗口注意力设计,显著提升了长序列视频的处理效率。
针对大窗口注意力带来的边界窗口尺寸不均问题,研发团队创新设计3D旋转位置嵌入机制,能够在动态调整窗口维度的同时保持时空特征的一致性。该机制通过对不同大小窗口实施差异化位置编码,有效解决了滑动窗口在时空体积边界产生的伪影问题,使SeedVR在合成视频、真实素材及AI生成内容等多场景下均展现出卓越的修复能力。
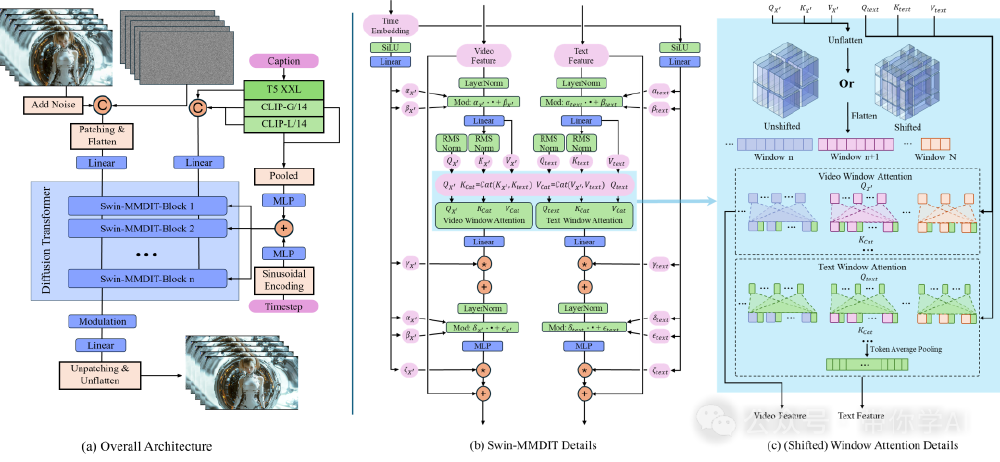
如上图所示,SeedVR架构通过Swin注意力机制实现了任意分辨率输入的灵活处理。这一设计突破了传统模型对输入尺寸的限制,为处理非标准分辨率视频提供了全新思路,特别适合需要处理多样化视频来源的技术开发者。
行业影响与未来展望
SeedVR-7B的推出,正深刻改变多个产业格局:影视修复领域,多家媒体机构已开始测试该技术重制经典内容;安防监控行业,主流厂商正在集成其算法提升夜间成像质量;甚至医疗影像领域,已有研究机构开始测试其在医学影像增强中的应用。这种跨领域渗透力,源于模型对细节真实性的极致追求。
技术路线图显示,字节跳动计划在未来版本中将显存需求控制在24GB的同时实现16K分辨率支持。更令人期待的是实时交互修复功能,未来用户可通过画笔直接指示需要强化的区域。随着这些技术落地,我们或将迎来"全民高清修复"的新时代——让每一段珍贵影像都能跨越时间磨损,在数字世界获得永恒生命。

如上图所示,SeedVR的品牌标志左侧圆形图案融合胶片(象征视频)与幼苗(象征修复与重生)的意象,直观传达了SeedVR通过技术创新让低质量视频焕发生命力的核心理念。动态窗口注意力机制正是这一理念的技术实现,使模型能像"智能修复师"一样自适应处理不同分辨率内容。
结论与建议
SeedVR-7B的出现,标志着视频修复技术正式进入"单步推理"时代。从监控安防到影视制作,从直播电商到个人创作,这项技术正在消除高质量视频生产的成本壁垒。真正的AI革命,不仅要实现性能突破,更要让先进技术触手可及。
对于行业从业者,建议重点关注两个方向:基于SeedVR-7B构建细分场景API服务,或参与模型微调生态(如训练特定领域LoRA权重)。随着技术普惠,视频修复或将成为内容创作的"基础设施"能力,推动超高清视频产业进入爆发增长期。
项目地址:https://gitcode.com/hf_mirrors/ByteDance-Seed/SeedVR-7B

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0194
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0194 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0121
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0121 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python05
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python05 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook06
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook06
热门内容推荐

最新内容推荐
