将WordPress导出转换为Markdown的利器
在数字化内容创作的世界中,越来越多的人选择使用静态站点生成器来托管他们的博客和网站,如Gatsby、Hugo和Jekyll等。但如何将现有的WordPress内容顺利迁移到这些平台?这就引出了我们的主角——wordpress-export-to-markdown。
这是一个强大的脚本,能将WordPress的XML导出文件直接转化为适合静态站点生成器的Markdown文件。不仅如此,它还能保留所有的图像,并处理嵌入的内容,如YouTube视频、Twitter推文或CodePen代码片段,使迁移过程变得简单快捷。
快速上手
要开始使用这个工具,你只需要:
- 安装Node.js v12.14或更高版本。
- 获取你的WordPress导出文件(确保选择了“全部内容”以保存图片和/或页面)。
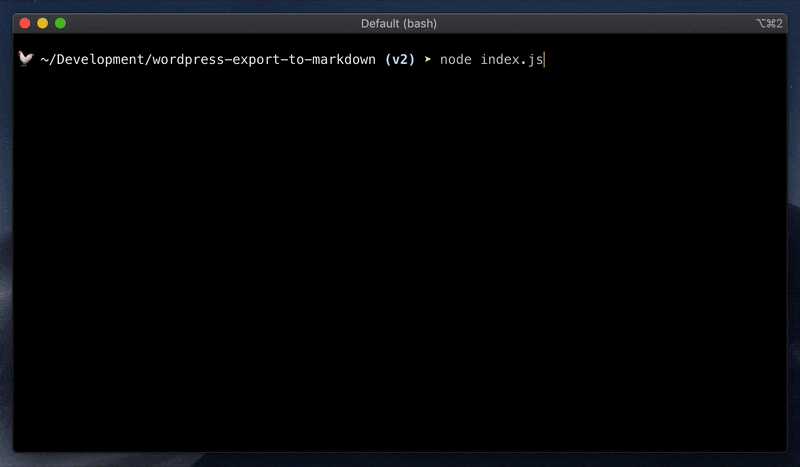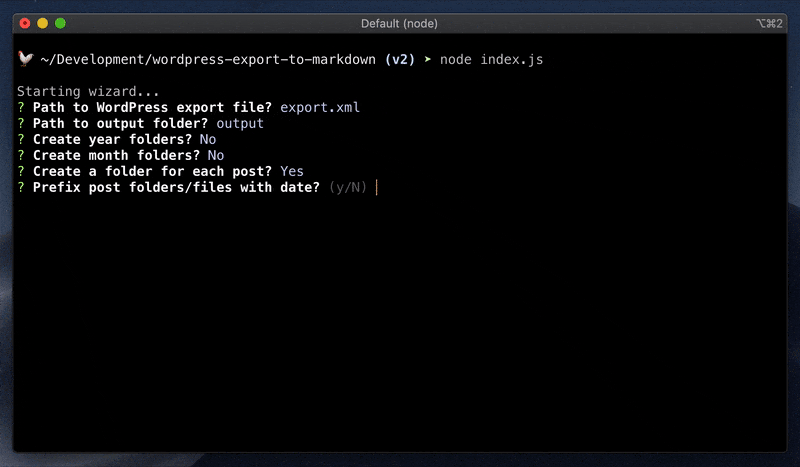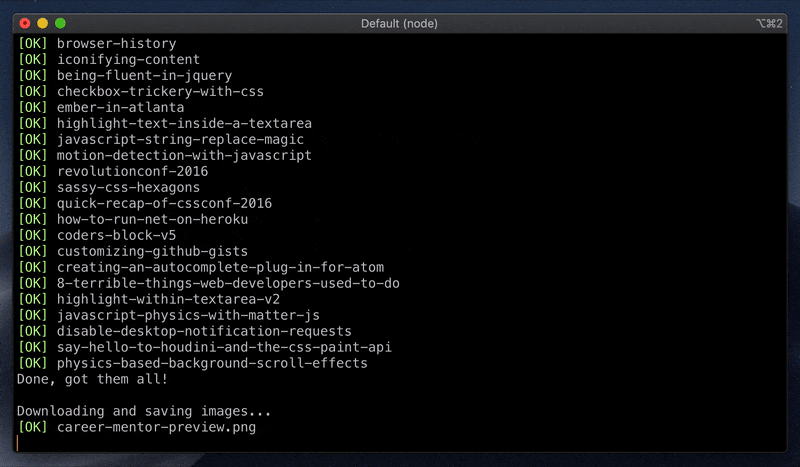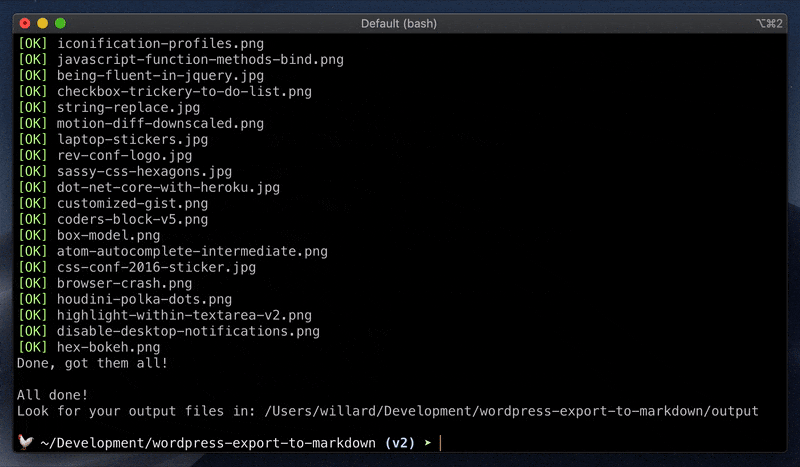
然后,在命令行里,你可以通过以下方式运行:
npx wordpress-export-to-markdown
或者克隆项目后再运行(这样重复运行更快,还可以自定义代码)。克隆后在终端转到包目录并执行:
npm install && node index.js
无论是哪种方式,它都会启动一个向导,引导你完成设置。
命令行选项
如果想在命令行中设置选项,你可以这样做:
npx wordpress-export-to-markdown --post-folders=false --prefix-date=true
或者在本地克隆的副本中运行:
node index.js --post-folders=false --prefix-date=true
向导会询问未指定的选项,如果你想完全跳过向导并使用默认值,可以添加--wizard=false。
可选参数
-
使用向导?(
--wizard)- 类型:布尔型
- 默认:
true - 启用后,脚本会提示你每个选项。禁用则直接使用默认值。
-
WordPress导出文件路径?(
--input)- 类型:文件路径
- 默认:
export.xml - 指定WordPress导出文件的位置。
-
输出文件夹路径?(
--output)- 类型:文件夹路径
- 默认:
output - 指定Markdown和图片文件的保存位置。若不存在,将为你创建。
-
创建年份文件夹?(
--year-folders)- 类型:布尔型
- 默认:
false - 是否按年份组织输出文件。
-
创建月份文件夹?(
--month-folders)- 类型:布尔型
- 默认:
false - 是否按月份组织输出文件。通常与
--year-folders结合使用。
-
为每篇文章创建文件夹?(
--post-folders)- 类型:布尔型
- 默认:
true - 设置是否以帖子的slug为名创建文件夹,以及Markdown文件名为
index.md。
-
在帖子文件名前加上日期?(
--prefix-date)- 类型:布尔型
- 默认:
false - 是否在帖子slug前加上发布日期。
-
保存附加到帖子的图片?(
--save-attached-images)- 类型:布尔型
- 默认:
true - 是否下载并保存与帖子关联的图片。
-
保存从文章内容中抓取的图片?(
--save-scraped-images)- 类型:布尔型
- 默认:
true - 是否下载并保存从
<img>标签中提取的图片。
-
包括自定义类型和页面?(
--include-other-types)- 类型:布尔型
- 默认:
false - 如果设为
true,将包含自定义类型和其他类型的帖子。
高级设置
在settings.js中,你可以调整一些高级设置,比如限制图片下载速度,或自定义前端元数据中的日期格式。这需要在本地运行脚本来启用这些设置。
总的来说,wordpress-export-to-markdown是一个强大且灵活的工具,可以帮助你轻松地将WordPress站点平滑过渡到各种静态站点生成器。无论你是希望简化维护,还是为了追求更高的性能,这个项目都值得尝试。现在就开始你的Markdown之旅吧!
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0151
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0151- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0111
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0111
