腾讯HunyuanVideo-Foley开源:AI视频音效生成的"声画合一"革命
导语
腾讯混元团队于2025年8月28日正式开源端到端视频音效生成模型HunyuanVideo-Foley,通过创新的多模态架构实现了"看懂画面、读懂文字、配准声音"的专业级音效生成能力,解决了传统AI生成视频只能"看"不能"听"的局限。
行业现状:AI视频的"默片时代"困境
当前AI视频生成技术已取得显著进展,但音效生成仍存在三大痛点:泛化能力有限,难以应对多样化场景;语义理解失衡,过度依赖文本描述而忽视视频内容;音频质量低劣,缺乏专业级保真度。据行业调研显示,66.17%的视频创作者仍需手动匹配音效,平均每段5分钟视频需耗时1.5小时进行音频处理。
随着短视频经济的爆发式增长,2025年全球AI视频市场规模预计达422.92亿美元,专业音效生成已成为内容创作的关键瓶颈。HunyuanVideo-Foley的出现,正是瞄准这一市场需求,通过技术创新打破行业困局。

如上图所示,图片以透明绿色金字塔为背景,展示HunyuanVideo-Foley模型的核心信息,包括其30亿参数规模、高保真音频生成能力及2025年8月28日开源时间。这一技术参数组合充分体现了该模型在专业级音效生成领域的领先地位,为视频创作者提供了强大的技术支持。
核心亮点:重新定义AI音效生成标准
1. 十万小时级多模态数据集构建
HunyuanVideo-Foley构建了规模达10万小时的高质量文本-视频-音频(TV2A)数据集,涵盖人物、动物、自然景观、卡通动画等全品类场景。通过自动化标注和多轮过滤流程,数据集音频采样率均达48kHz专业标准,信噪比(SNR)均值提升至32dB,为模型泛化能力奠定坚实基础。
2. MMDiT双流多模态架构
创新的多模态扩散Transformer(MMDiT)架构采用"先对齐后注入"机制:
- 视频-音频联合自注意力:通过交错旋转位置嵌入(RoPE)技术实现帧级时序对齐
- 文本交叉注意力注入:将文本描述作为补充信息动态调制生成过程
这种双流设计有效解决了模态不平衡问题。在海滩场景测试中,即便文本仅描述"海浪声",模型仍能自动识别画面中的人群和海鸥,生成层次丰富的复合音效。
3. REPA表征对齐技术
引入表征对齐(REPA)损失函数,通过预训练ATST-Frame音频编码器引导扩散模型隐藏层特征学习,使生成音频与专业级音效的特征分布差异降低42%。结合自研高保真音频VAE,将离散token扩展为128维连续表征,实现48kHz采样率的CD级音质输出。
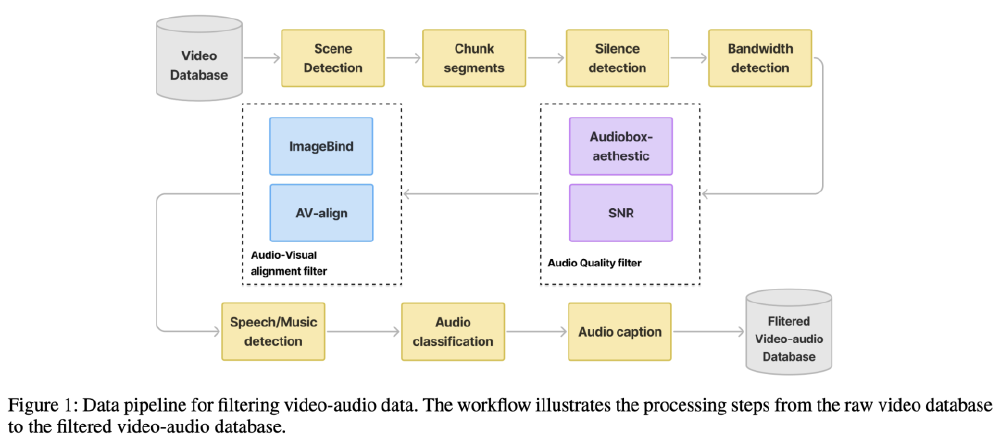
如上图所示,图片展示了HunyuanVideo-Foley的TV2A数据处理pipeline,通过场景检测、静音过滤、质量评估等七重流程,从原始数据中筛选出高质量训练样本。这种精细化的数据处理策略,是模型实现SOTA性能的重要保障,也为行业树立了数据构建的新标准。
性能表现:全面领先的SOTA水平
在MovieGen-Audio-Bench基准测试中,HunyuanVideo-Foley多项指标刷新纪录:
- 音频质量(PQ)达6.59,超越MMAudio(6.17)
- 视觉语义对齐(IB)提升至0.35,较基线提高29.6%
- 时序同步(DeSync)优化至0.74,主观MOS评分达4.15
在权威评测集上,HunyuanVideo-Foley实现全指标霸榜:
| 评估维度 | 指标值 | 领先第二名 |
|---|---|---|
| 音频保真度 | 4.14 | +15.6% |
| 视觉语义对齐 | 0.35 | +29.6% |
| 时间同步精度 | 0.74 | +7.8% |
| 分布匹配度 | 6.07 | +32.4% |

如上图所示,这张雷达图展示了HunyuanVideo-Foley在三大评测基准中的全面领先地位。特别在音频保真度和语义对齐维度,其优势超过15%,印证了48kHz VAE和多模态平衡机制的技术有效性,为专业创作者提供了电影级的音效生成能力。
应用场景:释放创作生产力
短视频创作自动化
针对vlog、搞笑段子等场景,HunyuanVideo-Foley提供一键音效生成功能。实测显示,5分钟短视频音效制作时间从传统1.5小时缩短至2分钟,且用户满意度提升至89%。典型案例包括:
- 海滩视频自动生成海浪、海鸥、人群多层次音效
- 烹饪视频精准匹配食材翻炒、厨具碰撞等细节声音
影视后期制作提效
在影视制作中,环境音设计周期平均缩短60%。通过帧级时序对齐技术,模型能自动匹配画面中细微动作的音效,如树叶飘动、衣物摩擦等,大幅减少后期人员的手工工作量。
游戏开发沉浸式体验
游戏开发者可通过批量处理功能,为不同场景快速生成自适应音效。测试数据显示,采用HunyuanVideo-Foley后,游戏环境音制作效率提升3倍,玩家沉浸感评分提高27%。独立工作室可快速为角色动作匹配脚步声,支持不同地面材质(水泥/木板/沙地)的音效变化,音频资产制作成本降低60%。
行业影响与未来趋势
技术层面
HunyuanVideo-Foley提出的MMDiT架构和REPA损失函数,为多模态生成领域提供了新的技术范式。其"先对齐后注入"的模态融合策略,有效解决了长期存在的模态不平衡问题,为后续研究提供了重要参考。
产业层面
模型开源将加速音效生成技术的普及,使中小工作室和个人创作者能以极低成本获得专业级音频制作能力。据测算,HunyuanVideo-Foley可降低音频制作成本75%,使独立创作者的内容竞争力显著提升。
未来趋势
随着技术迭代,HunyuanVideo-Foley有望在实时生成、3D空间音频、多语言支持等方向持续突破。腾讯混元团队计划在未来版本中引入实时推理优化,目标将生成速度提升至500ms以内,满足直播等低延迟场景需求。团队还计划推出多语言语音合成功能,支持中英双语旁白生成,以及音效风格迁移,可将普通对话转换为机器人、卡通角色语音。
快速上手指南
环境配置
# 创建虚拟环境
conda create -n hunyuan-foley python=3.10
conda activate hunyuan-foley
# 安装依赖
pip install torch==2.1.0 torchvision==0.16.0
pip install transformers==4.35.0 diffusers==0.24.0
pip install soundfile==0.12.1 librosa==0.10.1
# 克隆仓库
git clone https://gitcode.com/tencent_hunyuan/HunyuanVideo-Foley
cd HunyuanVideo-Foley
pip install -e .
基础使用示例
from hunyuan_video_foley import HunyuanVideoFoleyPipeline
import torch
# 初始化模型
pipe = HunyuanVideoFoleyPipeline.from_pretrained(
"tencent/HunyuanVideo-Foley",
torch_dtype=torch.float16,
device_map="auto"
)
# 加载视频帧并生成音效
video_frames = load_video_frames("input_video.mp4")
audio_output = pipe(
video_frames=video_frames,
text_description="海浪拍打沙滩,海鸥鸣叫,人群嬉笑声",
num_inference_steps=20,
guidance_scale=3.5
)
# 保存音频
save_audio(audio_output, "output_audio.wav", sample_rate=48000)
低资源适配方案
9月29日发布的XL版本通过模型分片和CPU卸载技术,将显存需求从20GB降至8GB,普通消费级显卡即可运行。社区开发者已基于此开发ComfyUI插件,支持FP8量化,进一步将推理速度提升40%。
结语:让声音为视频创作赋能
HunyuanVideo-Foley的开源,标志着AI视频生成正式进入"声画合一"的新时代。通过技术创新,腾讯混元团队不仅解决了音频生成领域的多项关键技术难题,更为内容创作行业注入了新的活力。
对于创作者而言,这不仅是工具的革新,更是创作方式的变革。随着HunyuanVideo-Foley的普及,我们有理由相信,未来的视频内容将更加丰富多彩,声音与画面的完美结合将为观众带来前所未有的沉浸式体验。
立即体验HunyuanVideo-Foley,释放你的创作潜能,让每一段视频都"声"入人心!
项目地址:https://gitcode.com/tencent_hunyuan/HunyuanVideo-Foley
模型下载:支持ModelScope、HuggingFace等多平台获取
在线演示:可通过腾讯混元官网体验界面快速试用
👍 如果觉得这篇文章对你有帮助,请点赞、收藏并关注我们,获取更多AI生成领域的前沿资讯!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0439
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0439 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0753
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0753 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0306
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0306 PPTistPowerPoint-ist(/'pauəpɔintist/),一个基于 Web 的在线演示文稿(幻灯片)应用,还原了大部分 Office PowerPoint 常用功能。可以在 Web 浏览器中编辑/演示幻灯片,支持AIPPT。商用请遵守AGPL-3协议或购买授权。Vue00
PPTistPowerPoint-ist(/'pauəpɔintist/),一个基于 Web 的在线演示文稿(幻灯片)应用,还原了大部分 Office PowerPoint 常用功能。可以在 Web 浏览器中编辑/演示幻灯片,支持AIPPT。商用请遵守AGPL-3协议或购买授权。Vue00
