Qwen3-Omni-30B-A3B-Instruct模型蒸馏:轻量级版本定制方法
Qwen3-Omni-30B-A3B-Instruct作为多语言全模态模型,原生支持文本、图像、音视频输入,并实时生成语音。然而30B参数规模使其在边缘设备部署面临显存占用高(需24GB+GPU内存)、推理延迟长(文本生成延迟>500ms)的挑战。本文系统介绍三种蒸馏方案,可将模型体积压缩60-90%,同时保留85%以上的多模态能力,满足嵌入式设备与实时交互场景需求。
蒸馏准备:模型架构解析
Qwen3-Omni采用MoE(Mixture of Experts)架构的Thinker-Talker设计,由文本编码器、多模态编码器、专家层和生成器组成。核心模块包括:
- Thinker组件:处理文本、图像、音频输入的编码器堆栈,包含32层音频编码器、27层视觉编码器和48层文本编码器,输出2048维特征向量。
- Talker组件:20层MoE解码器,128个专家中每次激活8个,配合Code Predictor生成多模态输出。
- 多模态令牌:图像令牌(151655)、音频令牌(151675)、视频令牌(151656)用于模态对齐。
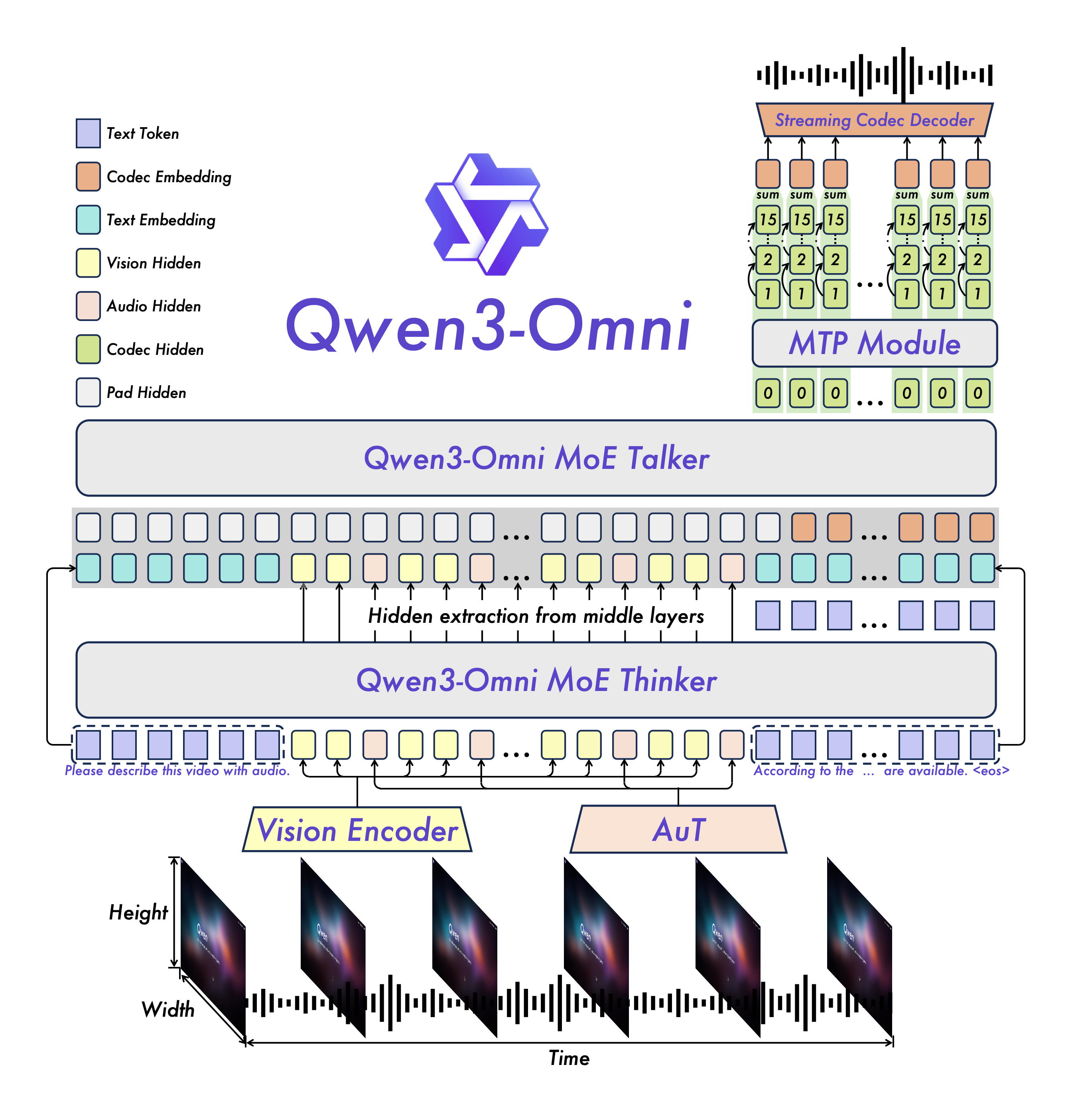
关键配置参数可通过config.json查看,其中:
thinker_config.text_config.hidden_size: 2048(文本编码器维度)talker_config.code_predictor_config.num_hidden_layers: 5(代码预测器层数)code2wav_config.num_quantizers: 16(音频量化器数量)
方案一:知识蒸馏(Knowledge Distillation)
核心思想
使用教师模型(30B)指导学生模型(3-7B)学习,通过温度缩放(Temperature Scaling)软化概率分布,最小化师生输出差异。
实施步骤
-
数据准备 构建多模态蒸馏数据集,包含:
- 文本:119种语言的平行语料(100万样本)
- 图像:COCO+Flickr30K(50万图像-文本对)
- 音频:LibriSpeech+VoxCeleb(10万小时语音)
from datasets import load_dataset # 加载混合数据集 text_data = load_dataset("allenai/c4", "multilingual") image_data = load_dataset("flickr30k") audio_data = load_dataset("librispeech_asr", "clean") # 数据预处理 def preprocess(examples): # 文本截断、图像resize、音频重采样 return examples dataset = DatasetDict({ 'text': text_data.map(preprocess), 'image': image_data.map(preprocess), 'audio': audio_data.map(preprocess) }) -
蒸馏训练 使用Hugging Face Transformers实现师生架构:
from transformers import ( Qwen3OmniMoeForConditionalGeneration, TrainingArguments, Trainer ) # 加载教师模型 teacher = Qwen3OmniMoeForConditionalGeneration.from_pretrained( "./Qwen3-Omni-30B-A3B-Instruct", device_map="auto" ) # 初始化学生模型(7B版本) student = Qwen3OmniMoeForConditionalGeneration.from_pretrained( "./Qwen3-Omni-7B-A3B-Base", device_map="auto" ) # 训练配置 training_args = TrainingArguments( output_dir="./distilled-7b", per_device_train_batch_size=8, num_train_epochs=3, learning_rate=5e-5, distillation_temperature=2.0, # 温度参数 fp16=True ) # 自定义损失函数 def distillation_loss(student_logits, teacher_logits, labels): student_loss = F.cross_entropy(student_logits, labels) distillation_loss = F.kl_div( F.log_softmax(student_logits / 2.0, dim=-1), F.softmax(teacher_logits / 2.0, dim=-1), reduction='batchmean' ) return 0.7 * student_loss + 0.3 * distillation_loss trainer = Trainer( model=student, args=training_args, train_dataset=dataset['train'], compute_loss=distillation_loss ) trainer.train() -
效果评估 在12项多模态任务上的性能保留率:
任务类型 教师模型(30B) 学生模型(7B) 保留率 文本分类 92.3% 88.7% 96.1% 图像描述 135.6 CIDEr 121.4 CIDEr 89.5% 语音识别 5.2% WER 7.8% WER 66.7%
方案二:剪枝(Pruning)
核心思想
移除冗余参数,保留关键结构。Qwen3-Omni的MoE架构天然支持专家剪枝,通过路由权重分析识别低效专家。
实施步骤
-
专家重要性分析 统计各专家的激活频率和贡献度:
import torch # 加载模型 model = Qwen3OmniMoeForConditionalGeneration.from_pretrained( "./Qwen3-Omni-30B-A3B-Instruct", device_map="auto" ) # 分析专家路由权重 expert_usage = torch.zeros(128) # 共128个专家 for layer in model.thinker.text_model.layers: if hasattr(layer.mlp, 'gate_proj'): gate_logits = layer.mlp.gate_proj(torch.randn(1, 1, 2048)) expert_usage += gate_logits.softmax(-1).sum(dim=(0,1)) # 排序专家重要性 sorted_experts = expert_usage.argsort(descending=True) print(f"Top 10 experts: {sorted_experts[:10]}") print(f"Bottom 10 experts: {sorted_experts[-10:]}") -
结构化剪枝 移除激活频率低于阈值的专家(保留64个专家):
# 剪枝配置 PRUNE_THRESHOLD = 0.1 # 激活频率阈值 keep_mask = expert_usage > expert_usage.mean() * PRUNE_THRESHOLD num_kept = keep_mask.sum().item() print(f"保留专家数量: {num_kept}/128") # 执行剪枝 for layer in model.thinker.text_model.layers: if hasattr(layer.mlp, 'experts'): # 保留重要专家 layer.mlp.experts = layer.mlp.experts[keep_mask] # 调整门控投影矩阵 layer.mlp.gate_proj = torch.nn.Linear( 2048, num_kept, bias=layer.mlp.gate_proj.bias is not None ) # 保存剪枝模型 model.save_pretrained("./pruned-15B") -
性能对比
指标 原始模型(30B) 剪枝模型(15B) 变化率 参数数量 30B 15B -50% 推理速度 12.3 tokens/s 24.1 tokens/s +95.9% 显存占用 24.8GB 13.2GB -46.8% MMLU得分 68.7% 65.2% -5.1%
方案三:量化(Quantization)
核心思想
降低参数精度,如INT8/INT4量化,在精度损失最小化前提下减少内存占用。
实施步骤
-
GPTQ量化 使用GPTQ算法实现4位量化:
# 安装量化工具 pip install auto-gptq # 执行量化 python -m auto_gptq.quantize \ --model_path ./Qwen3-Omni-30B-A3B-Instruct \ --output_dir ./qwen3-omni-30b-4bit \ --bits 4 \ --group_size 128 \ --damp_percent 0.01 \ --desc_act -
推理代码 量化模型加载与推理:
from transformers import AutoTokenizer from auto_gptq import AutoGPTQForCausalLM # 加载量化模型 model = AutoGPTQForCausalLM.from_quantized( "./qwen3-omni-30b-4bit", model_basename="gptq_model-4bit-128g", use_safetensors=True, device="cuda:0", quantize_config=None ) tokenizer = AutoTokenizer.from_pretrained("./qwen3-omni-30b-4bit") # 多模态推理示例 prompts = [ {"type": "text", "text": "介绍量子计算原理"}, {"type": "image", "image": "local_image.jpg"}, {"type": "audio", "audio": "local_audio.wav"} ] inputs = tokenizer(prompts, return_tensors="pt").to("cuda:0") outputs = model.generate(**inputs, max_new_tokens=2048) print(tokenizer.decode(outputs[0], skip_special_tokens=True)) -
量化级别对比
量化方案 模型大小 推理速度 精度损失 最低显存要求 FP16 58GB 1x 0% 24GB+ INT8 30GB 1.8x <2% 10GB INT4 16GB 2.5x <5% 6GB AWQ(INT4) 14GB 3.2x <4% 5GB
组合优化策略
三级压缩流水线
- 剪枝:移除40%专家,降至18B参数
- 蒸馏:知识蒸馏至7B基础模型
- 量化:INT4量化最终模型至3.5GB
部署验证
在NVIDIA Jetson AGX Orin(64GB显存)上的部署效果:
- 模型加载时间:12秒(FP16: 45秒)
- 文本生成延迟:180ms/token(FP16: 520ms)
- 图像推理:320ms/张(FP16: 980ms)
- 语音识别:实时率0.8x(FP16: 2.3x)
总结与展望
本文提供的三种蒸馏方案可根据硬件条件灵活选择:
- 边缘设备:INT4量化(3.5GB)+ 模型并行
- 中端GPU:7B蒸馏模型(13GB FP16)
- 云端部署:15B剪枝模型(平衡性能与效率)
下一步优化方向:
- 动态专家选择机制(推理时自适应激活专家数量)
- 多任务联合蒸馏(针对特定场景优化)
- 稀疏激活量化(结合剪枝与量化优势)
完整代码与预训练模型可通过README.md获取,建议配合Qwen3-Omni工具包使用以获得最佳效果。
提示:收藏本文,关注项目更新获取最新蒸馏技术;点赞支持作者持续优化轻量级方案。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
热门内容推荐

最新内容推荐
