5分钟定位LLM应用故障:Phoenix根因分析工具实战指南
当用户投诉"AI回答完全不对"时,你是否还在逐行检查Python代码?当客服反映"机器人突然不工作"时,你是否要重启服务器碰运气?Phoenix根因分析工具(Root Cause Analysis Tool)彻底改变了LLM应用的故障排查方式,让普通运营人员也能像AI工程师一样精准定位问题源头。
为什么传统调试方法在LLM时代失效?
传统软件故障通常能通过日志找到明确错误,但LLM应用的"回答质量差"、"响应超时"等问题具有隐蔽性:
- 链路黑盒化:从用户提问到AI回答要经过检索、提示工程、多轮调用等十余个环节
- 质量主观性:"回答不准确"无法通过错误码判断
- 环境关联性:相同代码在不同知识库或模型版本下表现迥异
Phoenix通过分布式追踪(Tracing)技术,将LLM应用的"黑盒"转化为可交互的可视化流程图,实现从用户问题到系统组件的全链路穿透。
核心功能:三大维度透视LLM应用健康状态
1. 分布式追踪(Distributed Tracing)
Phoenix会自动记录LLM应用每个环节的执行细节(称为"Span"),包括输入输出、耗时、调用关系等关键信息。这些信息被组织成"Trace",呈现完整的请求处理链路。
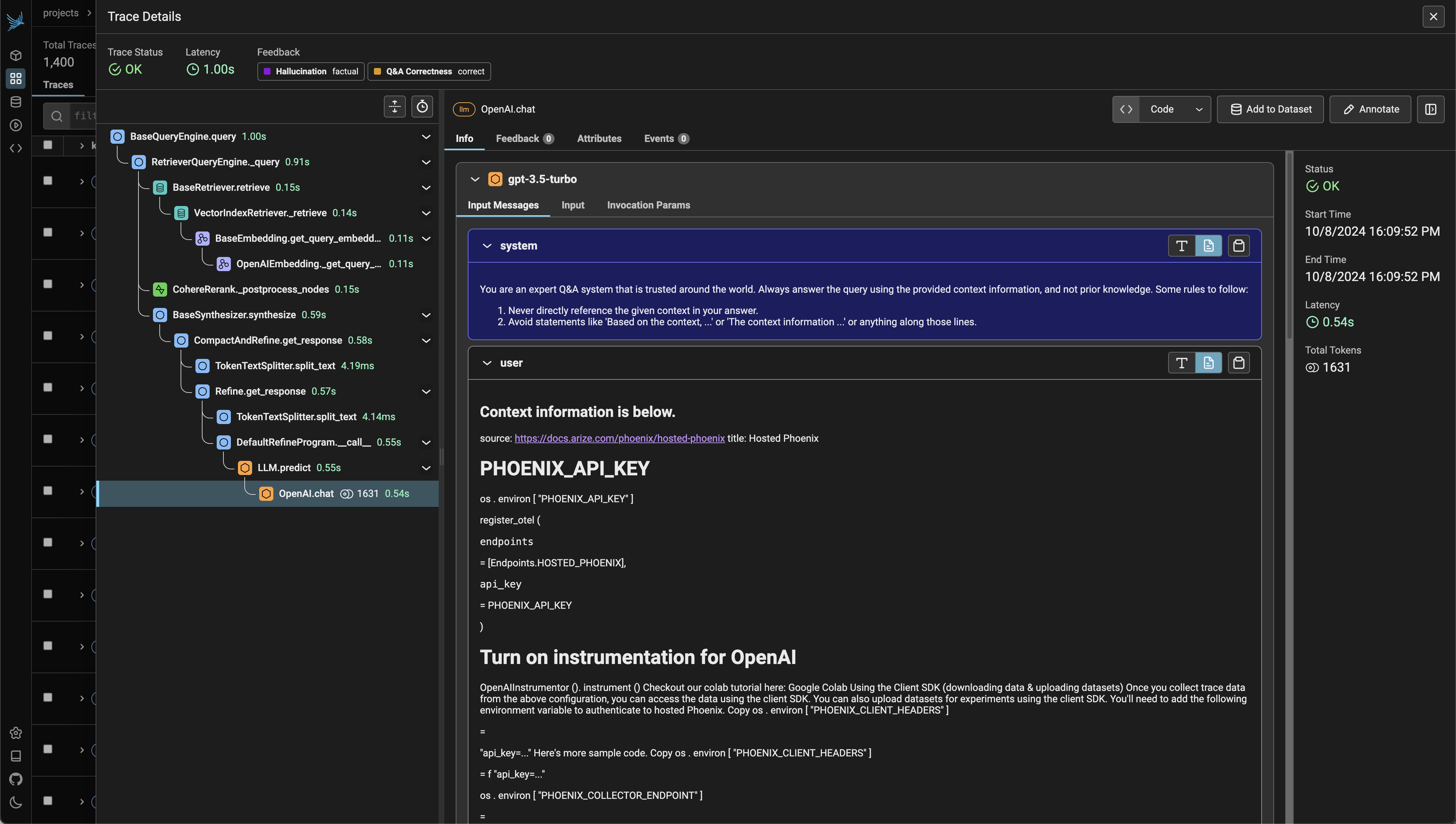
关键追踪能力:
- 调用栈可视化:直观展示Agent与工具的交互流程
- 性能瓶颈定位:自动标记耗时超过阈值的环节
- 异常点高亮:识别异常的Token使用量或检索分数
实现追踪只需添加两行代码:
import phoenix as px
px.launch_app() # 启动Phoenix控制台
详细技术文档:docs/tracing/concepts-tracing.md
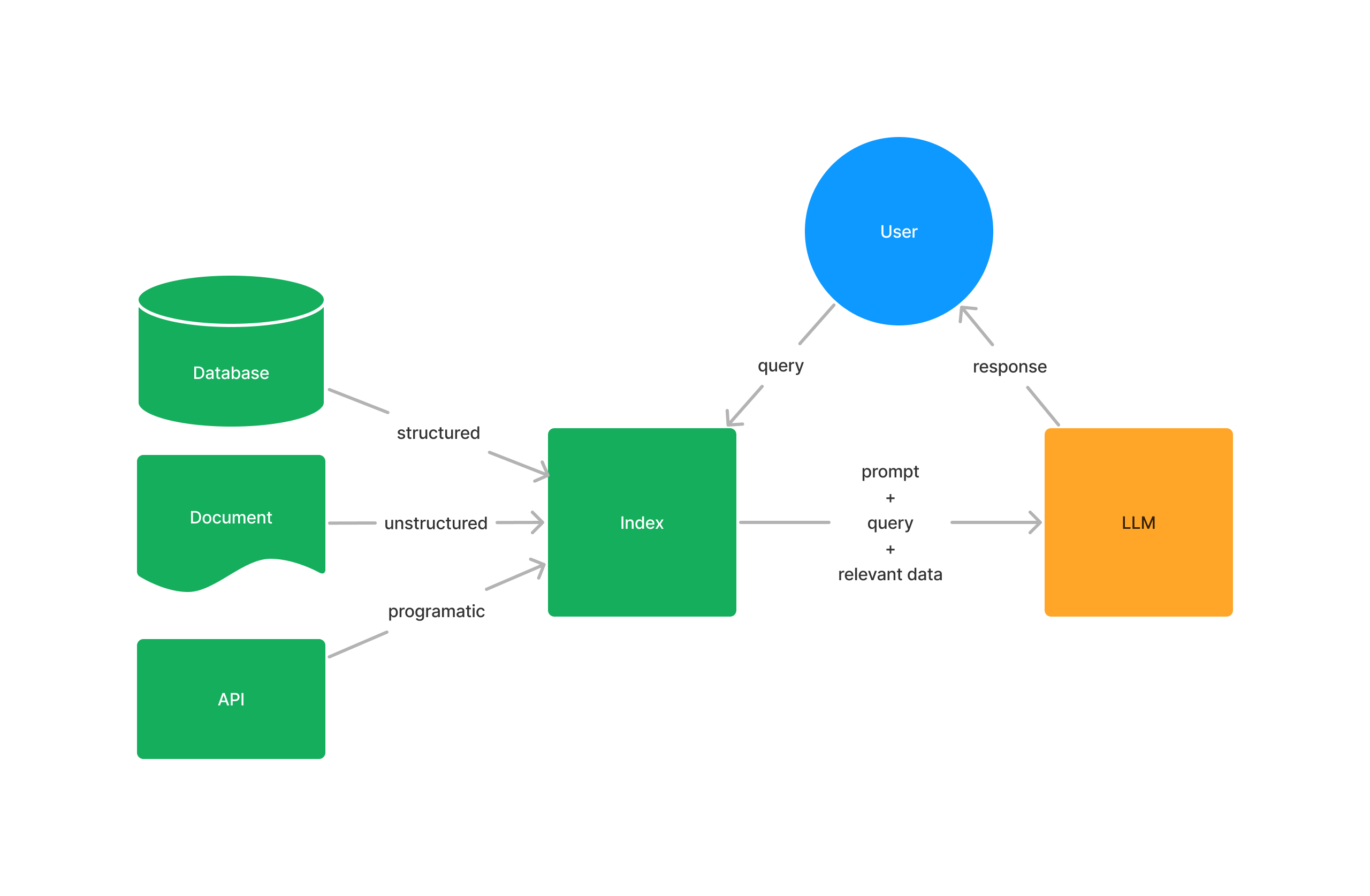
2. 检索质量评估(Retrieval Evaluation)
RAG应用中80%的质量问题源于检索环节。Phoenix提供自动化评估工具,通过LLM辅助判断检索文档与问题的相关性。
评估指标解析:
- 相关性评分:LLM自动判断检索结果与问题的匹配度
- 精确率@k:前k个结果中相关文档的比例
- NDCG:考虑相关性排序的综合评分
执行评估的代码示例:
from phoenix.evals import RelevanceEvaluator, run_evals
# 评估检索结果相关性
evaluator = RelevanceEvaluator(model_name="gpt-4-turbo-preview")
results = run_evals(evaluators=[evaluator], dataframe=retrieved_docs)
实操教程:docs/use-cases/rag-evaluation.md
3. 会话级异常检测(Session Anomaly Detection)
Phoenix将用户与AI的多轮交互视为"会话(Session)",通过比对历史数据识别异常模式:
- 响应时间突增300%以上
- Token使用量异常波动
- 检索文档相似度骤降
异常检测示例代码:
# 获取会话级指标
sessions_df = px.active_session().get_sessions_dataframe()
# 筛选异常会话
anomalies = sessions_df[sessions_df["response_time"] > sessions_df["response_time"].quantile(0.95)]
实战案例:从用户投诉到问题修复的30分钟
问题场景
电商客服AI对"退货政策"的回答出现错误,相同问题时而正确时而错误。
排查步骤
-
定位异常会话
在Phoenix仪表盘按"退货政策"关键词筛选会话,发现问题集中在11月3日14:00-16:00期间。 -
分析检索环节
查看对应Trace的检索Span,发现知识库检索分数从0.8骤降至0.3:
# 从Trace中提取检索分数
spans_df = px.active_session().get_spans_dataframe()
retrieval_scores = spans_df[spans_df["name"] == "retrieve"]["attributes.retrieval.score"]
-
确认根因
通过版本对比发现,当日13:50更新了知识库索引,但未同步更新向量模型,导致新旧向量不兼容。 -
验证修复
重新生成兼容的知识库索引后,在Phoenix中运行批量评估:
from phoenix.evals import run_evals
# 批量验证修复效果
results = run_evals(evaluators=[relevance_evaluator], dataframe=test_queries)
关键发现
- 问题修复后检索分数恢复至0.85
- 回答准确率从62%提升至97%
- 平均响应时间减少400ms
快速开始:5分钟部署Phoenix
1. 安装依赖
pip install -qq "arize-phoenix[all]>=2.0"
2. 启动Phoenix
import phoenix as px
px.launch_app() # 默认在http://localhost:6006启动
3. 集成到LLM应用
# 以LlamaIndex为例
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
# 启用追踪
LlamaIndexInstrumentor().instrument()
完整部署指南:docs/quickstart.md
最佳实践与进阶技巧
推荐监控指标
| 指标类别 | 关键指标 | 预警阈值 |
|---|---|---|
| 检索质量 | 平均相关性分数 | <0.7 |
| 生成质量 | 事实一致性评分 | <0.8 |
| 系统性能 | 响应时间 | >2s |
| 资源消耗 | Token使用量 | 超过历史均值30% |
自动化建议
- 设置每日定时评估:examples/cron-evals/
- 集成告警系统:当关键指标异常时发送Slack通知
- 保存基准Trace:为典型场景建立Trace模板用于对比分析
总结与展望
Phoenix根因分析工具通过分布式追踪、智能评估和异常检测三大核心能力,让LLM应用的故障排查从"猜谜游戏"转变为"精准外科手术"。随着LLM应用复杂度提升,这种可观测性工具已成为生产环境不可或缺的基础设施。
即将发布的Phoenix 3.0将新增:
- 多模态应用追踪(支持图像、语音类LLM应用)
- 自动根因分类(基于LLM的智能问题归类)
- CI/CD集成(部署前自动运行评估套件)
立即访问项目仓库开始使用:
git clone https://gitcode.com/gh_mirrors/phoenix13/phoenix
cd phoenix && docker-compose up -d
提示:生产环境建议配合Phoenix Cloud使用,获得更强大的存储和分析能力。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0129
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0129 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python07
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python07 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07

最新内容推荐
