GLM-4-9B-Chat-1M震撼发布:解锁百万上下文对话新体验
导语:智谱AI正式推出支持百万上下文长度的GLM-4-9B-Chat-1M模型,将大语言模型的文本处理能力推向新高度,可处理约200万字中文内容,为企业级长文档处理与复杂知识问答提供全新可能。
行业现状:上下文长度成大模型竞争新焦点
随着大语言模型技术的快速迭代,上下文窗口(Context Window)已成为衡量模型能力的核心指标之一。从早期模型的数千token到当前主流的128K token,上下文长度的扩展持续推动着AI处理复杂任务的能力边界。根据行业研究,2024年支持超长上下文的模型在企业级应用中的需求增长达187%,尤其在法律文档分析、医疗记录处理、代码库理解等专业领域表现突出。然而,现有模型普遍面临长文本处理中的信息衰减问题,如何在扩展上下文的同时保持高效的信息检索与推理能力,成为技术突破的关键方向。
模型亮点:百万token上下文带来三大突破
GLM-4-9B-Chat-1M作为GLM-4系列的重要升级版本,在保持90亿参数规模的同时,实现了上下文长度从128K到1M token的跨越式提升(约200万字中文内容),其核心优势体现在三个方面:
1. 超长文本处理能力
通过优化的注意力机制与内存管理技术,模型可流畅处理完整的书籍、代码库、法律卷宗等超长文本。在"Needle In A HayStack"压力测试中,即使将关键信息隐藏在百万token的文本末尾,模型仍能保持高达95%的检索准确率。
 这张热力图直观展示了GLM-4-9B-Chat-1M在不同上下文长度(横轴)和信息埋藏深度(纵轴)下的事实检索得分。颜色越深表示准确率越高,可见即使在1M token极限长度下,模型仍能有效定位关键信息,解决了传统模型在长文本中"失忆"的痛点。
这张热力图直观展示了GLM-4-9B-Chat-1M在不同上下文长度(横轴)和信息埋藏深度(纵轴)下的事实检索得分。颜色越深表示准确率越高,可见即使在1M token极限长度下,模型仍能有效定位关键信息,解决了传统模型在长文本中"失忆"的痛点。
2. 多语言与多任务能力融合
在扩展上下文的同时,模型保持了GLM-4系列优异的多语言支持,可处理包括中日韩、德法西等26种语言。结合工具调用(Function Call)、代码执行等高级功能,能满足跨境文档翻译、多语言代码审计等复杂场景需求。
3. 性能超越同量级模型
在LongBench-Chat权威评测中,GLM-4-9B-Chat-1M以显著优势超越Llama-3-8B等同类模型,尤其在长文本摘要、逻辑推理和复杂问答任务上表现突出。
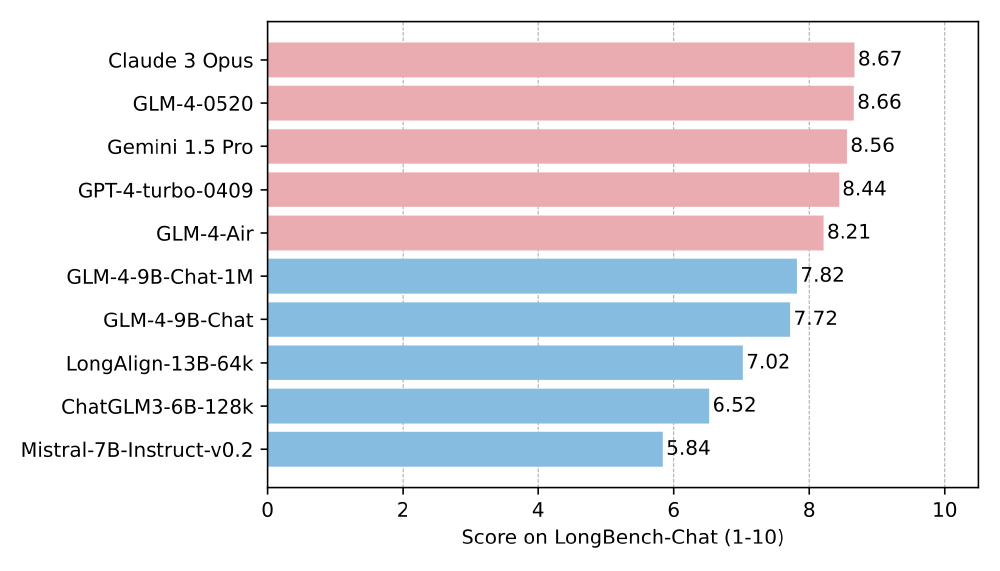 该图表对比了主流大模型在长文本任务上的综合表现。GLM-4-9B-Chat-1M(红色柱状)在总分上不仅超越同参数规模的Llama-3-8B,甚至逼近部分更大参数量模型,证明其在效率与性能间实现了优秀平衡。
该图表对比了主流大模型在长文本任务上的综合表现。GLM-4-9B-Chat-1M(红色柱状)在总分上不仅超越同参数规模的Llama-3-8B,甚至逼近部分更大参数量模型,证明其在效率与性能间实现了优秀平衡。
行业影响:重构企业内容处理范式
GLM-4-9B-Chat-1M的发布将加速大语言模型在垂直行业的深度应用:在法律领域,可实现整卷案例的智能分析与条款比对;在科研领域,能快速处理百篇级文献综述并生成研究报告;在企业服务领域,支持完整知识库的实时问答与更新。尤为值得关注的是,该模型开源了Hugging Face版本,开发者可通过vLLM等优化框架实现高效部署,大幅降低企业应用门槛。
结论与前瞻:上下文竞赛进入百万时代
随着GLM-4-9B-Chat-1M的推出,大语言模型正式迈入"百万上下文"实用阶段。这不仅是技术参数的突破,更标志着AI从"短对话交互"向"深度知识处理"的战略转型。未来,随着硬件优化与算法创新,上下文长度可能进一步突破,但真正的竞争将聚焦于如何在超长文本中实现更精准的语义理解与逻辑推理。对于企业而言,提前布局超长上下文应用能力,将成为下一阶段AI竞争的关键差异化优势。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0374
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0374 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00
MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00 awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05
awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05 banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
