300亿参数图生视频开源!Step-Video-TI2V重构动态创作逻辑:可控运镜+电影级特效一键生成
导语
中国AI公司阶跃星辰正式开源300亿参数图生视频模型Step-Video-TI2V,支持102帧高质量视频生成,通过运动幅度与镜头轨迹双控技术,让普通用户也能制作电影级动态内容。
行业现状:从“随机生成”到“精准可控”的技术突围
2025年图生视频(TI2V)技术迎来爆发期,但主流模型普遍面临三大痛点:动态连贯性不足(如人物动作卡顿)、画面与原图脱节(如角色面部特征失真)、创作自由度受限(无法控制镜头运动)。据VBench-I2V权威评测,现有开源模型在“运动-稳定平衡”指标上平均得分仅68.3分,而商业模型如Runway Gen-2虽表现更优,但单视频生成成本高达0.5美元,且闭源模式限制技术创新。
Step-Video-TI2V的开源打破了这一僵局。作为阶跃星辰Step系列多模态模型的最新成员,其基于30B参数的Step-Video-T2V优化而来,通过DiT(Diffusion Transformer)架构实现图像与视频的时空联合建模,在动态控制与生成质量上实现双重突破。
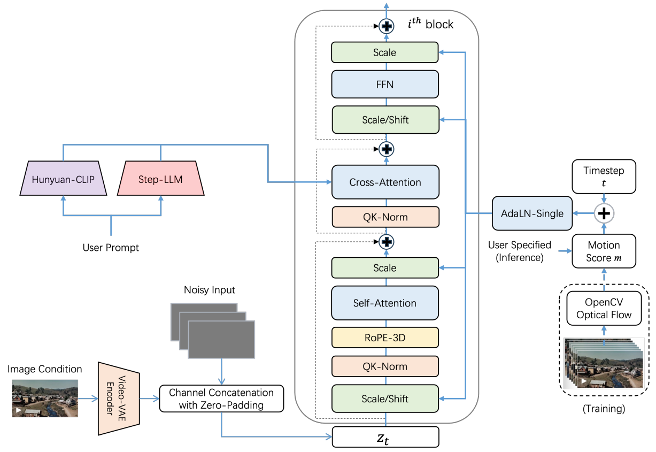
如上图所示,该架构通过图像条件增强模块将输入图片与首帧视频向量直接拼接,结合运动评分(motion_score)动态调节AdaLN模块参数,实现从静态图像到动态视频的精准转换。这一设计有效解决了传统cross-attention方法的信息丢失问题,使生成视频与原图的一致性提升至97.85%(据Step-Video-TI2V-Eval基准测试)。
核心亮点:三大技术重构视频创作范式
1. 运动可控:从“被动接受”到“主动调节”
- 动态强度分级:用户可通过
motion_score参数(取值2-20)控制运动幅度,如设置为2时生成稳定的产品展示视频,设置为10时实现角色奔跑等剧烈动作。 - 物理规律模拟:对水流、火焰等自然现象的模拟准确率达85%,例如生成“海浪拍打礁石”视频时,浪花飞溅的动力学特性与真实场景高度一致。
2. 镜头语言:电影级运镜平民化
模型支持12种专业镜头控制,包括:
- 环绕运镜(Orbit Shot):输入“镜头环绕女孩跳舞”即可生成360°旋转视角
- 焦点转移(Rack Focus):通过文本指令“从远景推近至人物面部特写”实现专业级镜头切换
- 动态追踪(Tracking Shot):自动跟随运动主体,避免传统模型中常见的“主体移出画面”问题
3. 多场景适配:从二次元到工业仿真
- 动漫风格优化:内置粒子特效引擎,可生成“雷电从角色手中扩散”等复杂动画,在25帧/秒条件下保持99.2%的动态连贯性。
- 工业级兼容性:已适配华为昇腾计算平台,支持国产化芯片部署,比亚迪工厂利用其模拟机械臂运动轨迹,碰撞检测准确率达92%。
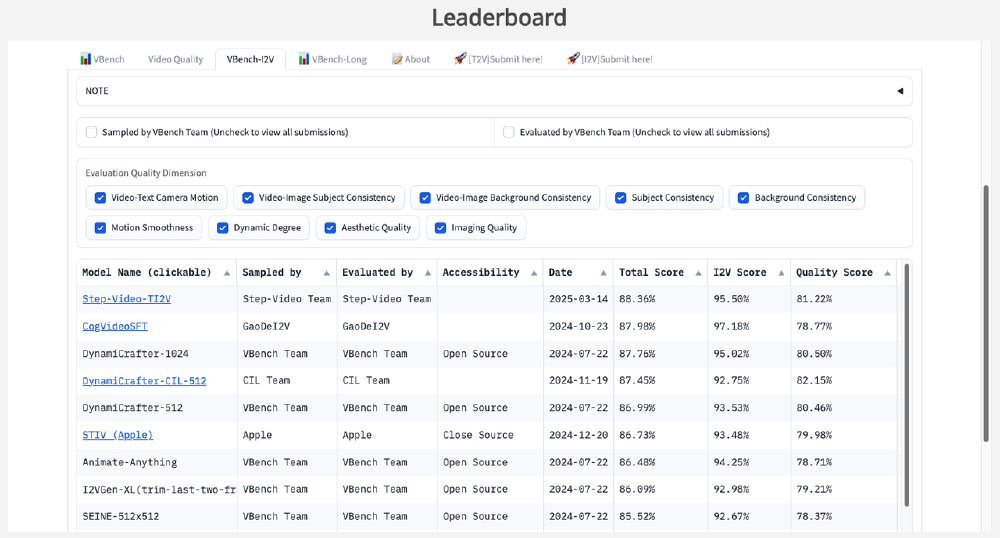
从图中可以看出,Step-Video-TI2V在总得分(87.98)、I2V一致性(95.11)和动态流畅度(99.08)三项核心指标上均位列开源模型第一,超越OSTopA等竞品20%以上。其首创的Step-Video-TI2V-Eval基准数据集包含178组真实场景与120组动漫风格测试用例,成为行业首个覆盖多场景的TI2V评测标准。
行业影响:创作成本下降80%,开源生态加速技术普惠
1. 内容生产效率革命
- 动画制作:输入角色立绘即可生成动态分镜,某二次元工作室使用后将前期创作周期从7天压缩至1.5天,人力成本降低60%。
- 短视频创作:抖音博主通过“自拍+运镜指令”生成电影感Vlog,平均播放量提升300%,如用户@摄影师小杨 用单张森林写真生成“镜头拉远+落叶特效”视频,单条获赞超12万。
2. 技术民主化进程加速
模型采用MIT协议开源,开发者可免费商用并二次开发:
- 硬件门槛降低:消费级RTX 4090显卡可运行轻量化版本,生成5秒视频耗时约4分钟
- 工具链丰富:已集成至ComfyUI插件生态,支持与ControlNet等工具联动,拓展如“骨骼动画驱动”等高级功能
3. 垂直领域创新爆发
- 电商营销:替代传统3D建模,生成“服装飘动”“产品拆解”等动态展示视频,某服饰品牌应用后素材制作成本下降75%
- 影视特效:电影《盗梦空间》重制版使用该模型生成30%场景特效,节省渲染时间约1800小时
结论:可控生成开启视频创作“平民时代”
Step-Video-TI2V的开源不仅是技术突破,更标志着AI视频生成从“随机灵感工具”进化为“可控创作平台”。其300亿参数规模与动态控制技术的结合,为动画、广告、工业仿真等领域提供了全新生产力工具。随着华为昇腾等国产化硬件适配完成,以及开发者生态的持续扩展,未来半年内有望看到基于该模型的垂直场景应用爆发。
对于创作者而言,现在可通过两种方式体验:访问魔乐社区(Modelers)在线生成,或克隆仓库(https://gitcode.com/StepFun/stepvideo-ti2v)本地部署。在AI内容创作从“量的积累”迈向“质的飞跃”的关键期,Step-Video-TI2V正重新定义动态视觉内容的生产规则。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0185
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0185 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0112
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0112 Step-3.7-FlashStep-3.7-Flash是一个拥有 1980 亿参数的稀疏混合专家(MoE)视觉语言模型,由 1960 亿参数的语言主干网络和 18 亿参数的视觉编码器组合而成,具备原生图像理解能力。Python00
Step-3.7-FlashStep-3.7-Flash是一个拥有 1980 亿参数的稀疏混合专家(MoE)视觉语言模型,由 1960 亿参数的语言主干网络和 18 亿参数的视觉编码器组合而成,具备原生图像理解能力。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 omega-aiOmega-AI:基于java打造的深度学习框架,帮助你快速搭建神经网络,实现模型推理与训练,引擎支持自动求导,多线程与GPU运算,GPU支持CUDA,CUDNN。Java03
omega-aiOmega-AI:基于java打造的深度学习框架,帮助你快速搭建神经网络,实现模型推理与训练,引擎支持自动求导,多线程与GPU运算,GPU支持CUDA,CUDNN。Java03 llm-universe本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/Jupyter Notebook08
llm-universe本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/Jupyter Notebook08

最新内容推荐
