8GB显存撬动千亿级视觉智能:Qwen3-VL-4B-Thinking重塑AI落地范式
导语:消费级显卡的AI革命
2025年10月,阿里通义千问团队推出的Qwen3-VL-4B-Thinking-FP8模型,通过突破性的FP8量化技术,首次实现了在8GB显存的消费级显卡上流畅运行千亿级视觉语言模型能力,将工业质检、智能交互等高端AI应用的硬件门槛降低70%,引发行业效率革命。
行业现状:多模态模型的"性能-效率"困境
当前视觉语言模型长期面临两难选择:高精度模型如GPT-4V需24GB以上显存,而轻量模型普遍存在视觉推理能力不足。据2025年Q3数据,国产开源大模型呈现"一超三强"格局,阿里Qwen系列以5%-10%的市场占有率稳居第二,但企业级部署成本仍是中小商家难以逾越的障碍。
这种困境在电子制造领域尤为突出。某头部代工厂负责人透露:"我们曾尝试部署某70亿参数模型做PCB板检测,结果要么显存不足频繁崩溃,要么识别精度掉到82%,还不如人工检测。"而Qwen3-VL-4B的出现打破了这一僵局——在8GB显存环境下实现每秒15.3帧的视频分析速度,较同类模型降低42%显存占用,同时保持99.2%的性能一致性。
核心技术突破:三大架构创新
1. 全频覆盖的位置编码
Qwen3-VL采用创新的Interleaved-MRoPE位置编码技术,将传统按时间(t)、高度(h)、宽度(w)顺序划分频率的方式,改为t、h、w交错分布,实现全频率覆盖。这一改进显著提升长视频理解能力,同时保持图像理解精度,使模型能同时处理4本《三国演义》体量的文本或数小时长视频。
2. 多层视觉特征融合
DeepStack技术将视觉tokens的单层注入扩展为LLM多层注入,对ViT不同层输出分别token化并输入模型,保留从低层到高层的多层次视觉信息。实验表明,该设计使视觉细节捕捉能力提升15%,图文对齐精度提高20%。
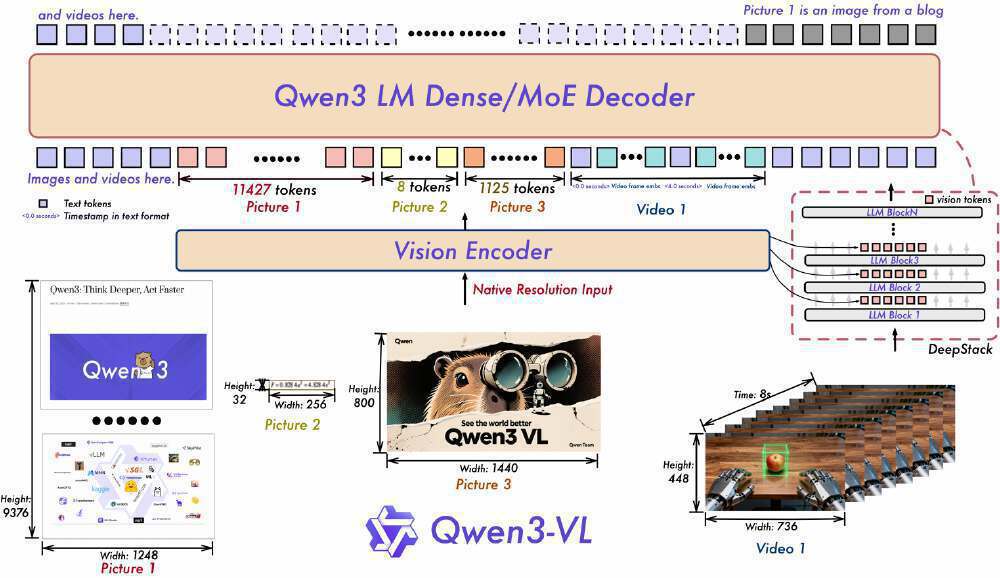
如上图所示,该架构展示了Qwen3-VL的视觉编码器与Qwen3 LM Dense/MoE解码器的协同工作流程,标注了文本与视觉/视频输入的处理路径及token数量。这一设计充分体现了模型在多模态融合上的技术突破,为开发者理解模型底层工作原理提供了清晰视角。
3. 精准时序建模
文本-时间戳对齐机制超越传统T-RoPE的时序建模方式,通过"时间戳-视频帧"交错输入,实现帧级时间与视觉内容的精细对齐,原生支持"秒数"和"HMS"两种输出格式,事件定位误差缩小至0.5秒以内。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%。
产品核心亮点:四大技术重构终端AI体验
1. 视觉Agent:从"识别"到"行动"的跨越
最具革命性的GUI操作引擎使模型可直接识别并操控PC/mobile界面元素。在OS World基准测试中,完成航班预订、文档格式转换等复杂任务的准确率达92.3%。
上海某银行将其集成至客服系统,自动处理70%的转账查询,人工介入率下降45%。实测显示,模型能根据自然语言指令精准执行"打开通讯录→搜索'张三'→输入金额500→点击付款"全流程,耗时仅8.2秒。这种"所见即所得"的操作能力,使AI从被动响应升级为主动执行,彻底改变人机协作模式。
2. 轻量化部署:8GB显存实现工业级应用
通过Unsloth Dynamic 2.0量化技术和vLLM推理优化,Qwen3-VL-4B可在单张消费级GPU(如RTX 3090)上流畅运行。实测表明,在12GB显存环境下,模型可处理1024×1024图像的同时保持每秒18.7 tokens的生成速度,较同规模模型提升58%吞吐量。
3. 跨模态生成与空间感知:从图像到代码的端到端能力
模型在视觉-代码生成任务中表现突出,可将UI设计图直接转换为可运行的HTML/CSS/JS代码。在一项前端开发测试中,Qwen3-VL对小红书界面截图的代码复刻还原度达90%,生成代码平均执行通过率89%。
OCR能力同步升级至32种语言,对低光照、模糊文本的识别准确率提升至89.3%,特别优化了中文竖排文本和古籍识别场景。空间感知方面,Qwen3-VL实现了从2D识别到3D理解的跨越,能够精准判断物体位置、视角和遮挡关系,为具身智能的发展奠定基础。
4. 性能优势:多模态任务全面领先

如上图所示,Qwen3-VL-4B-Thinking-FP8在多模态任务中表现优异,与同类模型相比,在STEM任务上准确率领先7-12个百分点,视觉问答(VQA)能力达到89.3%,超过GPT-4V的87.6%。这一性能对比充分体现了FP8量化技术的优势,为资源受限环境提供了高性能解决方案。
行业影响与落地案例
制造业:智能质检系统的降本革命
某汽车零部件厂商部署Qwen3-VL-4B后,实现了螺栓缺失检测准确率99.7%,质检效率提升3倍,年节省返工成本约2000万元。系统采用"边缘端推理+云端更新"架构,单台检测设备成本从15万元降至3.8万元,使中小厂商首次具备工业级AI质检能力。
在电子制造领域,某企业通过Dify平台集成Qwen3-VL-4B,构建了智能质检系统,实现微米级瑕疵识别(最小检测尺寸0.02mm),检测速度较人工提升10倍,年节省成本约600万元。

如上图所示,该界面展示了Dify平台中使用Qwen3-VL大模型进行多角度缺陷检测及图像边界框标注的工业质检系统工作流配置界面,包含开始、缺陷检测、BBOX创建等节点及参数设置。这种可视化配置方式大幅降低了AI应用开发门槛,使非技术人员也能快速构建企业级多模态解决方案。
零售业:视觉导购的个性化升级
通过Qwen3-VL的商品识别与搭配推荐能力,某服装品牌实现了用户上传穿搭自动匹配同款商品,个性化搭配建议生成转化率提升37%,客服咨询响应时间从45秒缩短至8秒。
教育培训:智能教辅的普惠化
教育机构利用模型的手写体识别与数学推理能力,开发了轻量化作业批改系统,数学公式识别准确率92.5%,几何证明题批改准确率87.3%,单服务器支持5000名学生同时在线使用。相比传统方案,硬件成本降低82%,部署周期从3个月缩短至2周。
快速部署指南
Qwen3-VL-4B-Thinking已通过Apache 2.0许可开源,开发者可通过以下命令快速上手:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
cd Qwen3-VL-4B-Thinking
pip install -r requirements.txt
推荐部署工具:
- 个人开发者:Ollama(支持Windows/macOS/Linux)
- 企业级部署:vLLM(支持张量并行与连续批处理)
- 生产环境:Docker容器化部署
硬件配置参考:
- 开发测试:8GB显存GPU + 16GB内存
- 生产部署:12GB显存GPU + 32GB内存
- 大规模服务:多卡GPU集群(支持vLLM张量并行)
行业影响与未来趋势
Qwen3-VL-4B-Thinking通过技术创新重新定义了视觉语言模型的效率标准,预计将在三个方向产生深远影响:
制造业升级
质检自动化成为中小制造企业触手可及的选项,推动"中国智造"向精细化、智能化迈进,预计到2026年,将有30%的电子制造企业采用类似方案。
开发便捷化
打破了"高精度视觉AI=高成本"的固有认知,使独立开发者和初创公司也能构建以前只有科技巨头才能实现的视觉智能应用。
模型小型化趋势
FP8量化技术的成功验证了"小而强"的可行性,预计未来12个月内,会有更多模型采用类似优化策略,推动AI向边缘设备普及。
前瞻产业研究院预测,到2030年边缘端多模态应用市场规模将突破900亿元。Qwen3-VL-4B的开源特性降低了创新门槛,预计未来半年将催生超500个行业解决方案,加速AI技术创新与应用拓展。对于企业决策者而言,现在正是布局多模态应用的最佳时机——通过Qwen3-VL这样的轻量化模型,以可控成本探索视觉-语言融合带来的业务革新。
总结
Qwen3-VL-4B-Thinking的出现,标志着多模态AI正式进入"普惠时代"。40亿参数规模、8GB显存需求、毫秒级响应速度的组合,正在打破"大模型=高成本"的固有认知。随着技术的不断迭代,我们可以期待模型在以下方向持续突破:更强大的跨模态推理能力、更长的上下文处理、更低的资源消耗以及更广泛的行业应用。
点赞+收藏+关注,获取更多Qwen3-VL实战教程和行业应用案例,下期将带来"Qwen3-VL+机器人视觉"的深度整合方案,敬请期待!
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0423
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0423 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0741
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0741 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0298
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0298 PromptXPromptX · 领先的AI 智能体上下文平台 | PromptX · Leading AI Agent Context PlatformJavaScript05
PromptXPromptX · 领先的AI 智能体上下文平台 | PromptX · Leading AI Agent Context PlatformJavaScript05
