如何快速下载Stable Diffusion模型?SD-WebUI模型下载器中文版完整指南
SD-WebUI模型下载器中文版是一款专为Stable Diffusion用户打造的高效模型管理工具,能够帮助新手和普通用户轻松解决模型下载慢、安装复杂的问题,让AI绘图创作更顺畅。
为什么选择这款模型下载神器?
对于Stable Diffusion爱好者来说,找到合适的模型并顺利下载往往是创作的第一步,也是最容易遇到障碍的环节。这款中文下载器通过优化资源链接和简化操作流程,将原本需要专业知识的配置过程变得像日常上网一样简单。无论是Checkpoint、LoRA还是VAE模型,都能通过直观的界面一键获取,让你专注于创意本身而非技术难题。
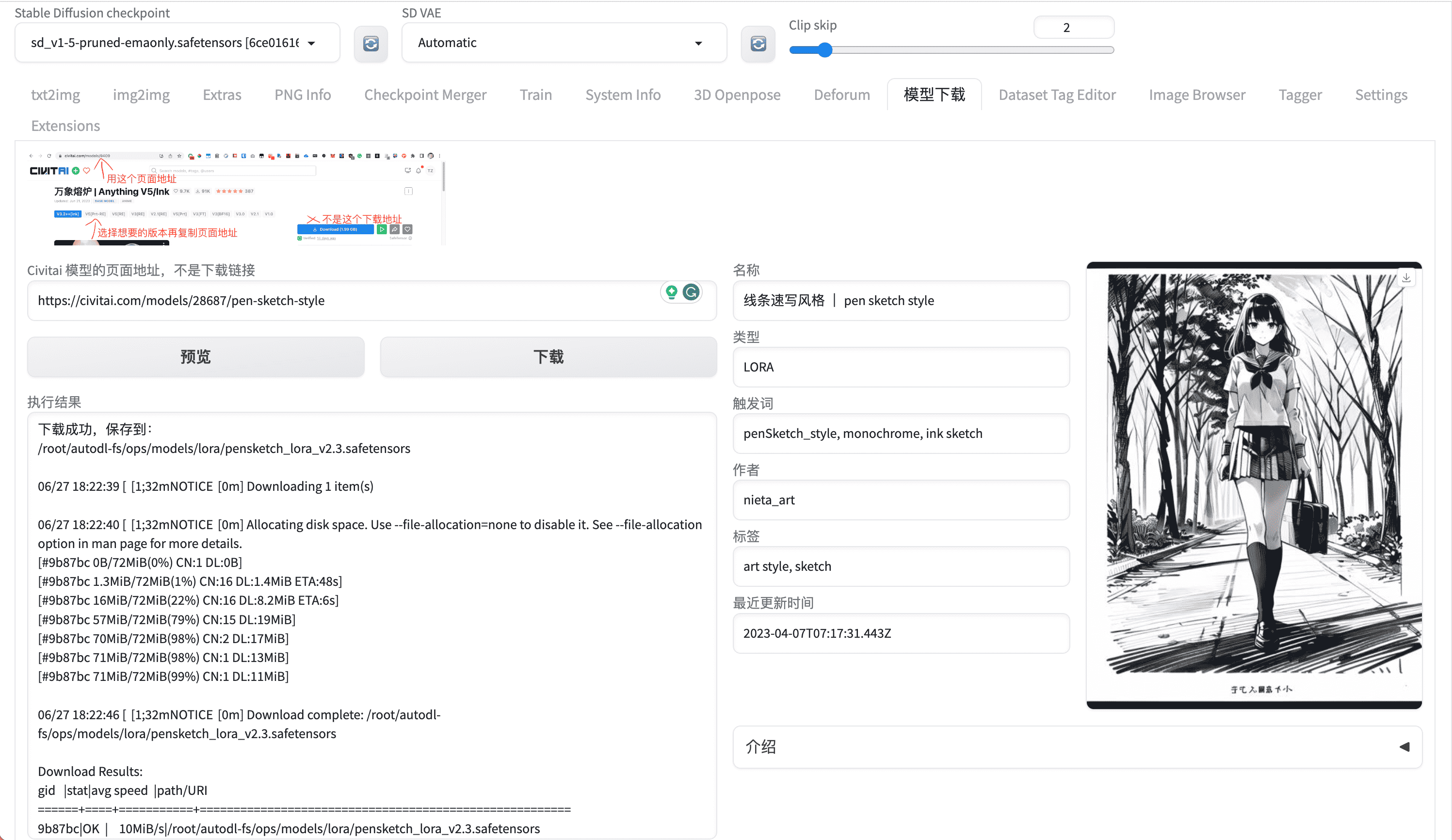 SD-WebUI模型下载器中文版直观的操作界面,让模型管理一目了然
SD-WebUI模型下载器中文版直观的操作界面,让模型管理一目了然
3分钟快速上手安装步骤
环境准备要求
在开始安装前,请确保你的电脑已安装:
- Python 3.7及以上版本
- Git版本控制工具
这些基础软件是运行下载器的必要条件,如果你还没有安装,可以在Python官网和Git官网找到详细的安装教程。
一键安装流程
- 打开终端或命令提示符,输入以下命令克隆项目仓库:
git clone https://gitcode.com/gh_mirrors/sd/sd-webui-model-downloader-cn - 进入项目目录:
cd sd-webui-model-downloader-cn - 安装依赖包:
pip install -r requirements.txt
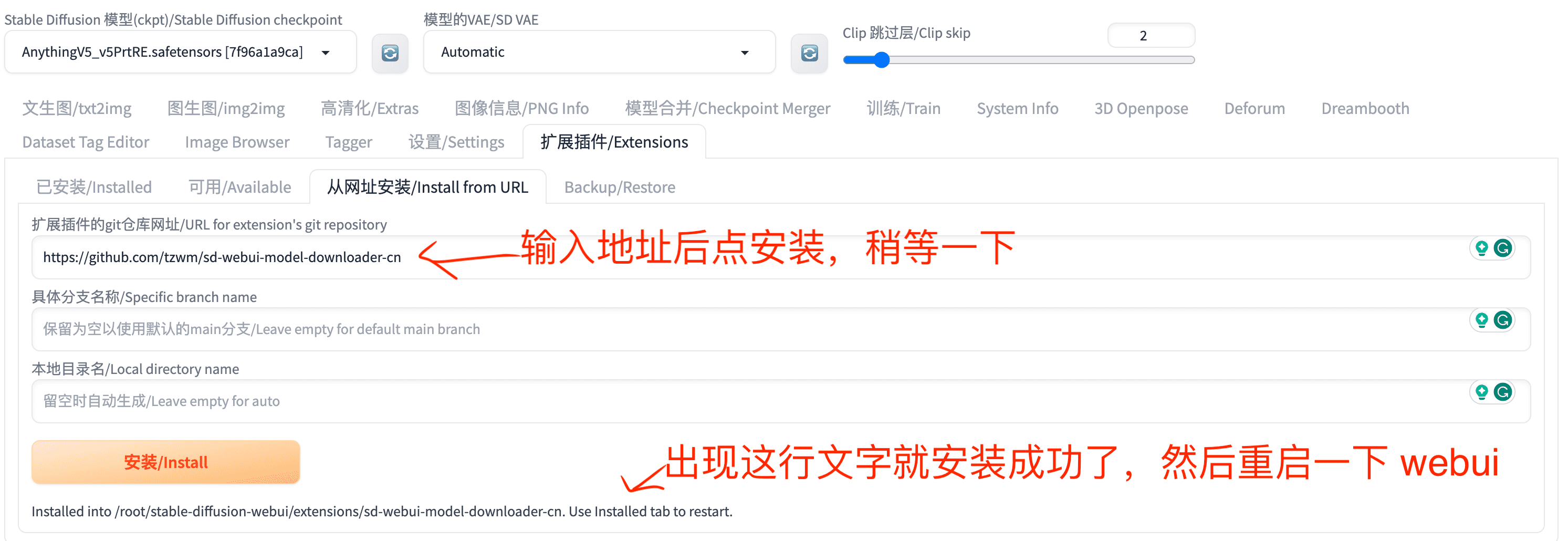 清晰的安装步骤指引,即使是电脑新手也能轻松完成
清晰的安装步骤指引,即使是电脑新手也能轻松完成
实用功能与使用技巧
如何添加自定义模型源
很多用户不知道其实可以添加自己常用的模型仓库链接。在软件设置界面中,找到"模型源管理"选项,点击"添加新源",输入仓库名称和地址即可。这个功能让你能够集中管理所有常用的模型资源,无需在多个网站间切换。
批量下载与自动分类
下载多个模型时,只需勾选需要的模型文件,点击"批量下载"按钮,软件会自动将不同类型的模型保存到对应的文件夹中。比如Checkpoint模型会存放在models/Stable-diffusion目录,LoRA模型则会保存到models/Lora目录,省去手动整理的麻烦。
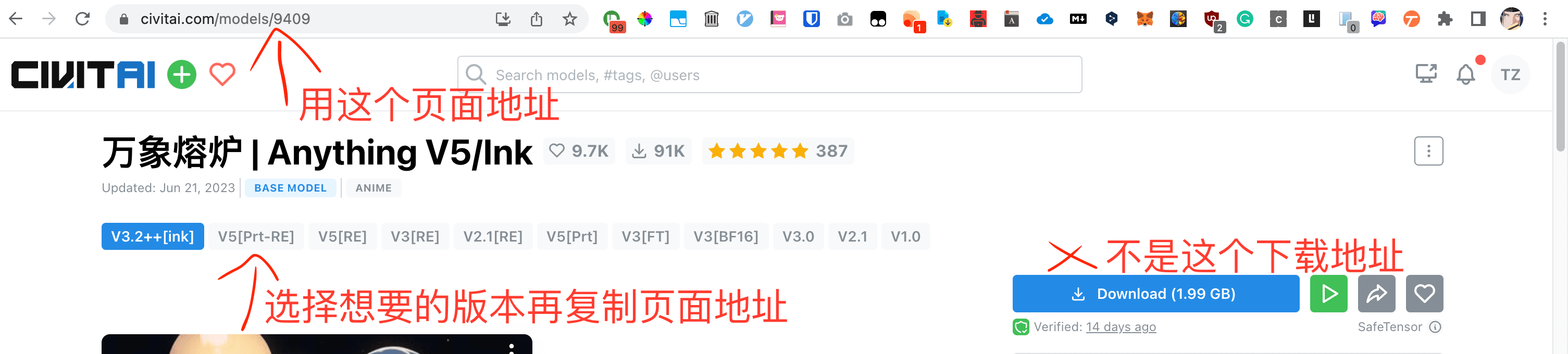 设置模型下载路径时的贴心提示,帮助你规范管理模型文件
设置模型下载路径时的贴心提示,帮助你规范管理模型文件
常见问题解决方法
下载速度慢怎么办?
如果遇到下载速度不理想的情况,可以尝试切换不同的模型源。软件内置了多个国内加速节点,在下载设置中选择"自动选择最快节点",系统会根据你的网络状况智能优化下载线路。
模型安装后不显示如何处理?
这种情况通常是模型存放路径不正确导致的。请检查下载设置中的"模型保存目录"是否与SD-WebUI的模型文件夹一致。正确的路径应该是你的SD-WebUI安装目录下的models文件夹,确保这一点后重启WebUI即可看到已安装的模型。
官方文档与资源
项目的详细使用说明和更新日志可以在docs目录中找到,其中包含了更多高级功能的使用技巧和常见问题解答。如果你在使用过程中遇到任何问题,也可以查看scripts目录下的源码文件获取技术细节,但对于普通用户来说,通过图形界面已经能满足大部分需求。
这款免费的模型下载工具不仅简化了Stable Diffusion的使用门槛,还通过持续的更新迭代不断提升用户体验。无论你是AI绘画新手还是有一定经验的创作者,都能从中获得更高效、更愉悦的模型管理体验,让每一次创作都从轻松获取模型开始。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0199
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0199 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0130
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0130 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python08
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python08 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
热门内容推荐

最新内容推荐
