GLNet:超高清图像高效内存分割解决方案
在当今的数据驱动世界中,处理高分辨率图像的分割任务变得越来越重要,特别是在城市规划、医疗影像分析等领域。然而,这样的任务对算法效率,特别是GPU内存提出了严峻挑战。这就是我们引入**GLNet(Global-Local Networks)**的原因——一个为超高清图像进行高效内存管理且高质量分割的深度学习框架。
项目简介
GLNet是一种创新的深度学习模型,专为处理高达3000万像素的超高清图像而设计,其训练只需要一块1080Ti显卡,并且在推理阶段所需的GPU内存不到2GB。不仅如此,GLNet还在保持高效的同时,提供了与现有模型相比更为出色的分割性能。
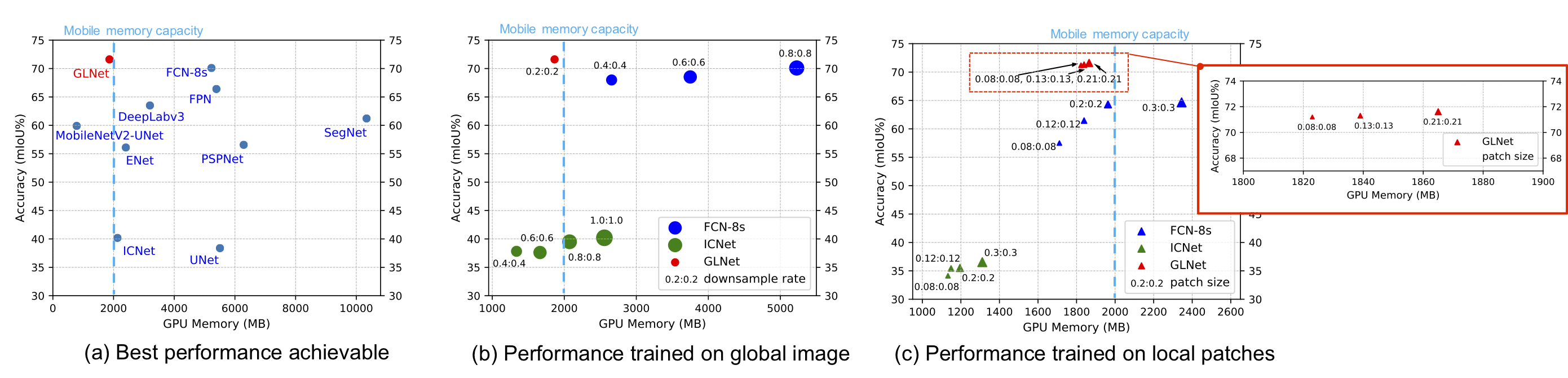
上图展示了GLNet在准确度和内存使用之间的平衡表现。通过集成全局和局部信息的紧凑方式,GLNet实现了在确保精度的同时,显著减少内存消耗。
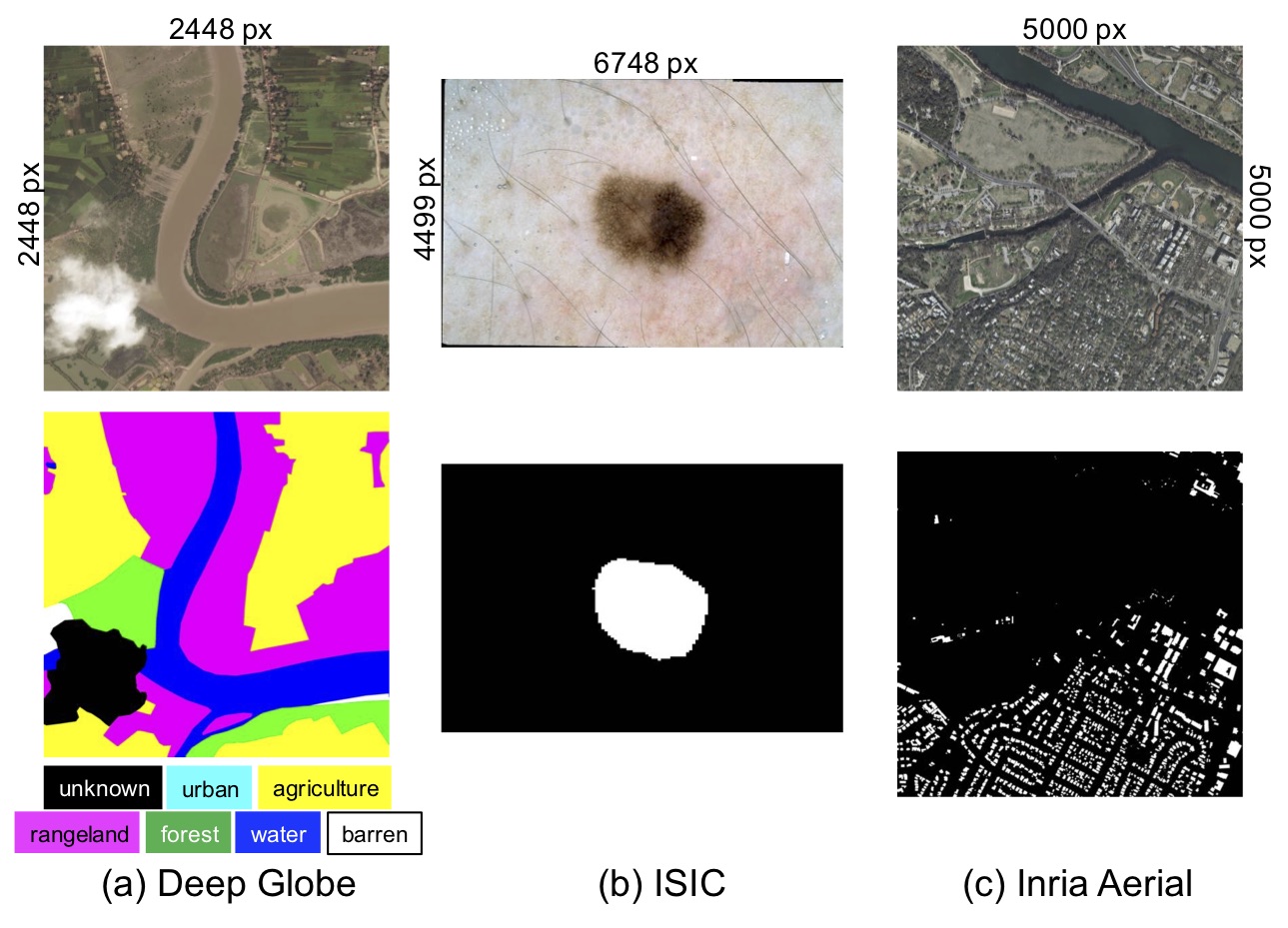
GLNet已在多个超高清数据集上进行了测试,包括DeepGlobe、ISIC和Inria Aerial,展示了其在各种场景中的广泛应用潜力。
技术分析
GLNet的核心是全球-局部分支的设计,其中,全局分支处理下采样的图像,局部分支则处理经过裁剪的部分。通过深度特征图共享和特征图正则化,这两个分支协同工作,形成了一种完整的基于补丁的全局-局部深层协作模式。
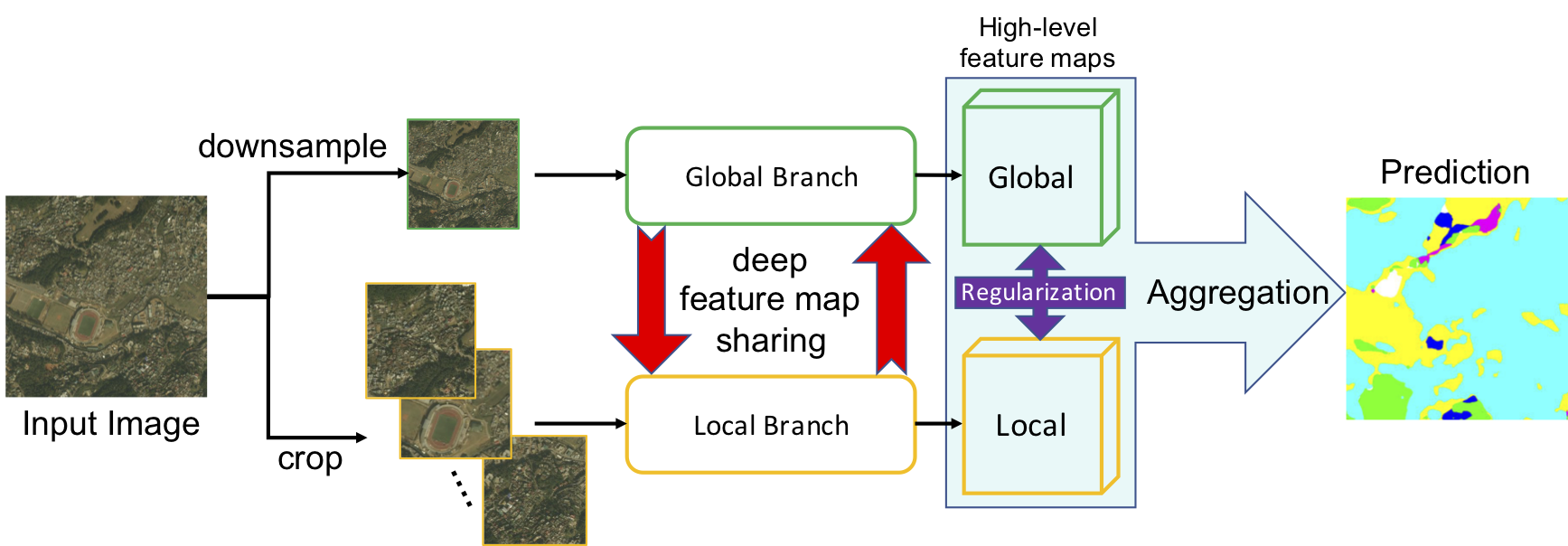
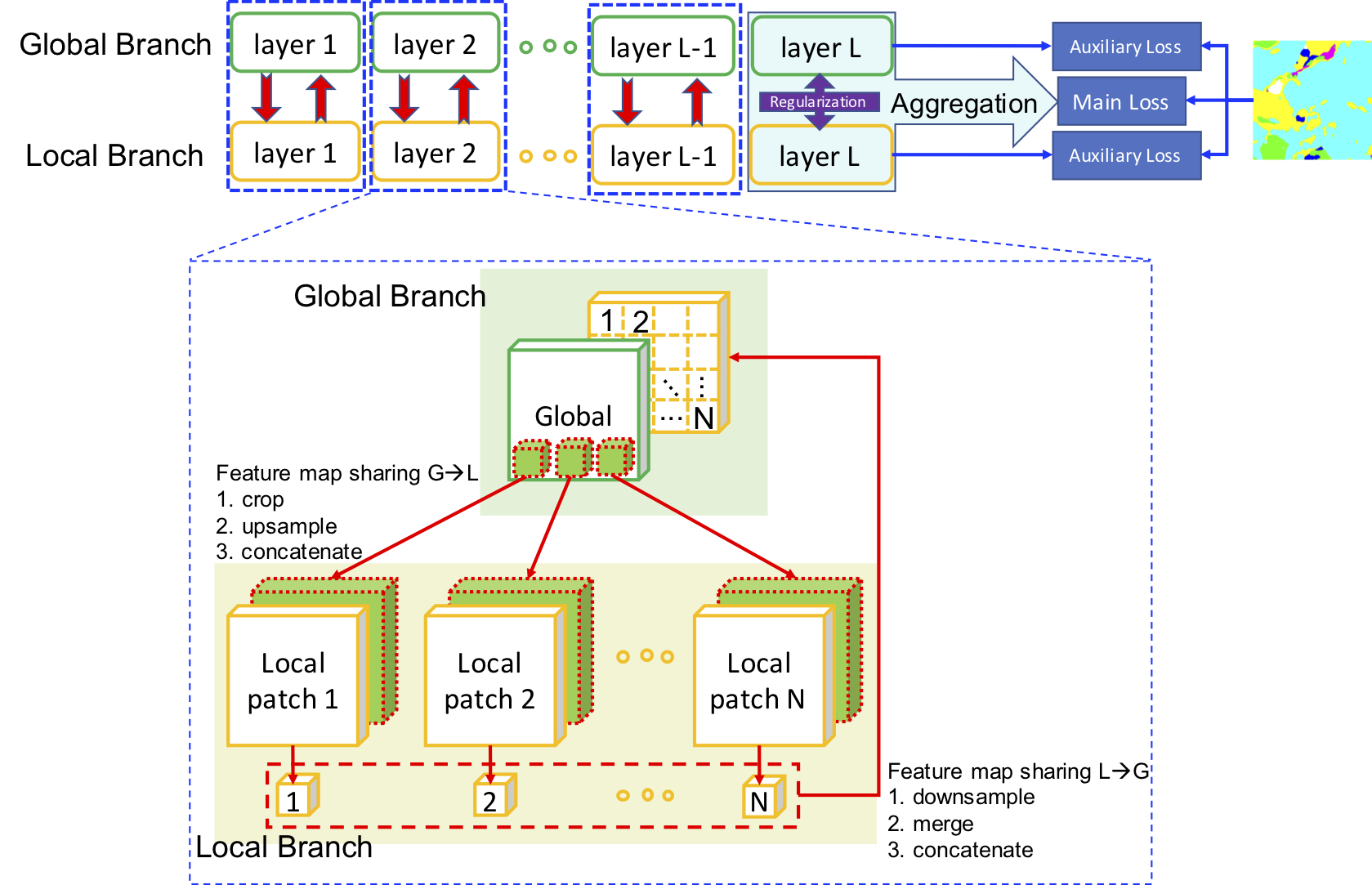
应用场景
GLNet不仅适用于城市规划中的遥感图像解析,还可应用于医学成像的病灶检测,以及任何需要处理高分辨率图像以获取精细区域信息的场合。例如,在智能交通系统中,它可以用于精确识别道路设施;在医疗领域,它可帮助医生更准确地定位皮肤病变。
项目特点
- 内存效率:仅需1080Ti即可进行训练,推理时GPU内存占用低于2GB。
- 高质量分割:即便在高分辨率图像上,也展现出优越的分割性能。
- 全球-局部融合:结合全局视野和局部细节,提供全面的信息捕捉。
- 易于使用:兼容Python 3.5以上版本,依赖项明确,提供详细的训练和评估脚本。
如果你正在寻找一种能够在有限资源条件下处理超高清图像分割问题的方法,GLNet是一个不容错过的选择。现在就加入并体验它的强大功能吧!
引用
如果你在研究中使用了这个代码库,请引用以下论文:
@inproceedings{chen2019GLNET,
title={Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images},
author={Chen, Wuyang and Jiang, Ziyu and Wang, Zhangyang and Cui, Kexin and Qian, Xiaoning},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2019}
}
最后,我们要感谢Andrew Jiang教授和Junru Wu在实验上的帮助。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
