推荐项目:ydiff——Lisp程序的结构比较利器
在编程的世界里,代码的比较和版本控制至关重要。今天,我们为你介绍一个专注于Lisp程序的革命性比较工具——ydiff。对于那些深谙Lisp优雅但又苦于代码差异分析的开发者来说,这绝对是一个不可多得的助手。
项目介绍
ydiff是一款高度智能化的结构比较工具,专门针对Lisp家族的语言设计。它的出现,旨在解决传统文本级差异比较的局限性,通过理解代码的结构而非仅仅对比字符,为程序员提供更精准、更直观的代码差异视图。
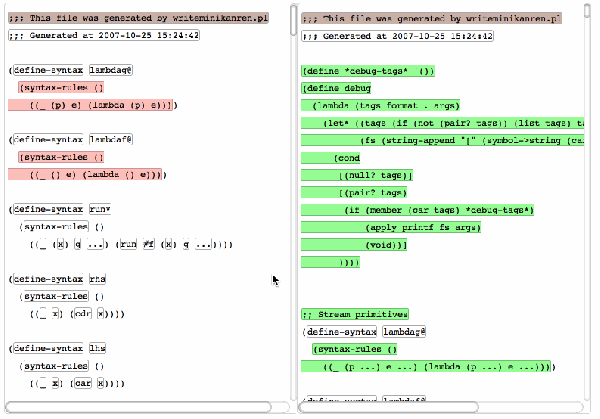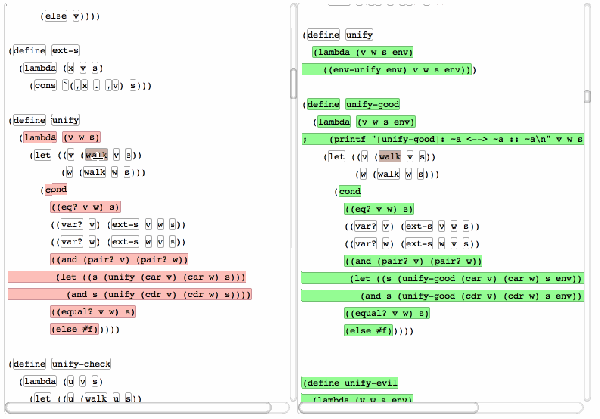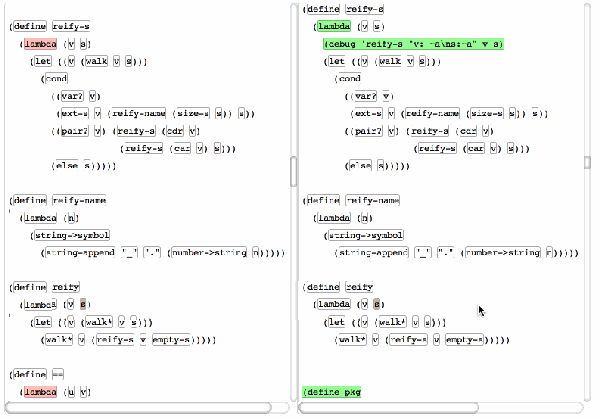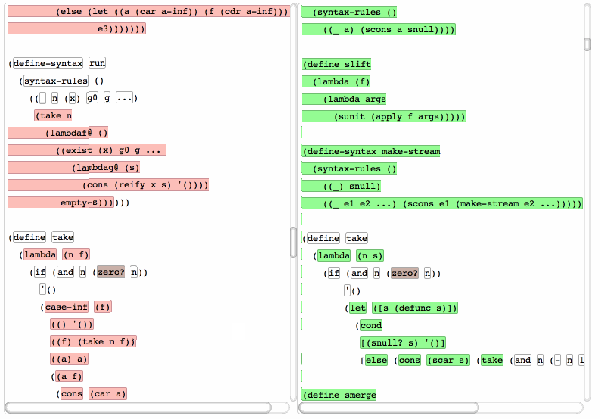
技术分析
ydiff的核心优势在于其语言感知能力和格式不敏感特性。它不仅仅是基于字符串进行比对,而是深入解析代码结构,从而避免了因类型不同而产生的误判。比如,“10000”这个数字不论是作为字符串还是整型,在ydiff眼中都能正确识别其本质。此外,即使你的代码经过了缩进调整或换行变化,ydiff也能无视这些“视觉噪音”,只关注实质性的变动。
该项目利用Racket语言实现,一种强大的函数式编程平台,确保了其解析和处理复杂结构数据的能力。尽管目前仅支持Lisp系列语言,但它展示了通过自定义解析器扩展到其他语言的可能性。
应用场景
ydiff的应用场景广泛,尤其适合软件开发过程中的代码审查、重构验证以及团队协作。无论是个人开发者在不同版本之间查找细微变更,还是团队成员间共享代码修改逻辑,ydiff都能提供巨大的帮助。尤其是对于那些频繁重构Lisp代码的项目而言,其对移动、重命名、重组代码片段的智能检测功能,极大提升了工作效率。
项目特点
- 语言感知: 深入理解代码结构,避免无效比较。
- 格式不敏感: 不受空白、换行影响,聚焦实际更改。
- 智能代码迁移检测: 精准追踪代码块的移动和变化。
- 人性化输出: 通过交互式HTML报告,让查看差异变得轻松高效。
- 易于部署: 基于Racket,简单构建后即可执行。
尽管安装和使用过程简洁明了,需要注意的是,为了保证可视化效果,需将必要的CSS和JavaScript文件放置于同一目录下,稍显不便,但这并不妨碍ydiff成为Lisp开发者手中的宝剑。
如果你正埋头于Lisp项目,或是寻找一款能够提升代码管理效率的工具,ydiff无疑是值得尝试的选择。它不仅简化了代码审查流程,更是提升了开发过程的愉悦感,是Lisp世界中的一股清流。
点击这里访问ydiff项目主页,开启你的高效代码旅程吧!
以上就是关于ydiff的推荐介绍,希望对你有所帮助。记得star和支持开源社区的优秀项目哦!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
热门内容推荐

最新内容推荐
