推荐开源项目:PyBasicBayes——贝叶斯推理的简约之美
在数据科学与机器学习的广阔天地中,贝叶斯方法以其独特的魅力占据了一席之地。今天,我们向大家介绍一个简洁而强大的Python库——PyBasicBayes,它为概率分布建模和贝叶斯推断带来了优雅的解决方案。
项目介绍
PyBasicBayes是一个专注于概率分布建模和贝叶斯推断的Python库。它包含了一系列抽象对象来实现基本的概率分布,并采用了诸如Gibbs采样、变分均场算法等核心贝叶斯推断技术。通过简洁的API设计,使得构建和操作复杂模型变得十分便捷。无论是进行学术研究还是解决实际问题,PyBasicBayes都是一个实用的工具箱。
技术剖析
PyBasicBayes的核心在于其对概率分布和模型操作的高度抽象化。通过abstractions.py文件定义了分布和模型应支持的操作接口,这些接口兼容多种算法需求,如Gibbs采样和变分推断。例如,使用Gaussian分布作为组件,结合Mixture模型,轻松实现高维空间中的混合模型建模。这一切都基于直观的代码结构,让即便是初学者也能快速掌握高级的贝叶斯分析技术。
应用场景
PyBasicBayes的应用范围广泛,尤其适合于数据分析、模式识别和复杂系统的行为研究。从简单的数据分析任务,如数据可视化和聚类,到复杂的不确定性量化和多假设测试,它都能发挥作用。特别是在那些需要理解和建模数据背后潜在结构的场景中,比如金融风险评估、文本分类和生物信息学,PyBasicBayes提供了灵活而强大的方法。
项目特点
- 易用性:通过高度封装的对象模型,即使是复杂的贝叶斯网络也能够以简洁的代码块实现。
- 灵活性:支持Gibbs采样与变分推断等多种后验推断算法,易于切换和实验,满足不同复杂度的需求。
- 教育友好:清晰的文档和示例代码(如
demo.py)使得它成为教学和自学贝叶斯统计的理想平台。 - 扩展性强:通过定义新类型的概率分布和模型接口,开发者可以轻松地扩展其功能,适应更多特定领域应用。
示例演示
考虑一个典型的混合模型拟合案例:通过PyBasicBayes,我们可以快速构建一个高斯混合模型,不仅能够生成数据,还能在观察到真实数据后进行高效的后验推断,利用Gibbs采样探索后验分布,再通过变分推断锁定最佳模型。这种混合算法策略使得在面对复杂分布时更加稳健,且通过直观的数据可视化(如混合模型的数据点和最佳模型图),让用户能直接看到模型的适应性和解释力。
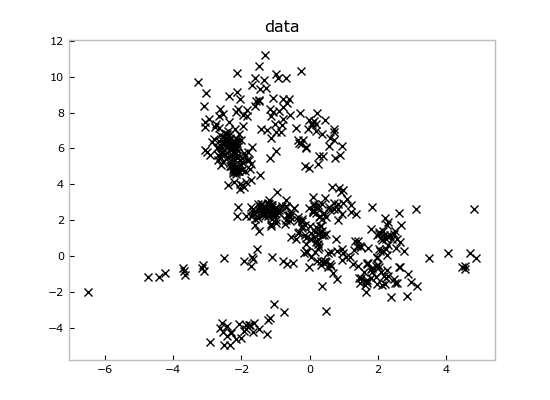
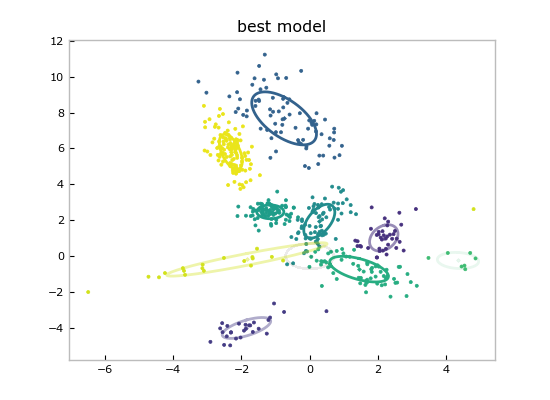
PyBasicBayes不仅提供了强大的数学工具,还是一扇通往贝叶斯思维世界的门扉。对于寻求深入理解数据背后故事的数据科学家或机器学习爱好者而言,这是一个值得关注的开源项目。
通过以上介绍,相信您已对PyBasicBayes有了初步了解。不论是进行科学研究还是工业应用,PyBasicBayes都能成为您的实用工具,带领您走进贝叶斯世界,探索数据的深层含义。欢迎尝试,开启您的贝叶斯之旅!
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust099
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust099- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 MiMo-V2.5-ProMiMo-V2.5-Pro作为旗舰模型,擅⻓处理复杂Agent任务,单次任务可完成近千次⼯具调⽤与⼗余轮上 下⽂压缩。Python00
MiMo-V2.5-ProMiMo-V2.5-Pro作为旗舰模型,擅⻓处理复杂Agent任务,单次任务可完成近千次⼯具调⽤与⼗余轮上 下⽂压缩。Python00 GLM-5.1GLM-5.1是智谱迄今最智能的旗舰模型,也是目前全球最强的开源模型。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。Jinja00
GLM-5.1GLM-5.1是智谱迄今最智能的旗舰模型,也是目前全球最强的开源模型。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。Jinja00 Kimi-K2.6Kimi K2.6 是一款开源的原生多模态智能体模型,在长程编码、编码驱动设计、主动自主执行以及群体任务编排等实用能力方面实现了显著提升。Python00
Kimi-K2.6Kimi K2.6 是一款开源的原生多模态智能体模型,在长程编码、编码驱动设计、主动自主执行以及群体任务编排等实用能力方面实现了显著提升。Python00 MiniMax-M2.7MiniMax-M2.7 是我们首个深度参与自身进化过程的模型。M2.7 具备构建复杂智能体应用框架的能力,能够借助智能体团队、复杂技能以及动态工具搜索,完成高度精细的生产力任务。Python00
MiniMax-M2.7MiniMax-M2.7 是我们首个深度参与自身进化过程的模型。M2.7 具备构建复杂智能体应用框架的能力,能够借助智能体团队、复杂技能以及动态工具搜索,完成高度精细的生产力任务。Python00
