小米MiMo-Audio开源:70亿参数开启音频大模型"少样本泛化"时代
导语
小米正式开源全球首个实现少样本泛化能力的音频大模型MiMo-Audio-7B-Base,通过上亿小时训练数据和创新架构,在多项基准测试中超越谷歌Gemini与OpenAI GPT-4o音频模型,标志着音频AI从"专用工具"向"通用智能"跨越。
行业现状:从"单一任务"到"全能听觉"的突围
当前音频AI技术面临三大痛点:传统模型需针对语音识别、环境声分类等任务单独优化,多模态融合能力薄弱,复杂场景下泛化性能急剧下降。据信通院《2025 AI交互技术趋势报告》显示,用户对语音交互的延迟容忍阈值已从2023年的800ms降至500ms,方言识别需求增长370%,而现有系统仅能满足40%的复杂场景需求。
小米AI实验室负责人指出:"现有系统能'听见'声波,但不会'理解'场景——这就像给机器装了耳朵,却没教它如何解读声音的意义。"在此背景下,MiMo-Audio-7B的开源具有里程碑意义,其核心突破在于采用GPT-3式的"规模即能力"范式,通过超大规模预训练实现跨任务泛化。
与此同时,音频市场正迎来爆发式增长。艾媒咨询数据显示,2024年中国长音频市场规模达287亿元,同比增长14.8%;预计2025年将达337亿元。随着生活场景碎片化与数字消费升级,长音频凭借其独特的伴随性和深度沉浸体验,正加速渗透通勤、睡前、车载等高契合度场景。
核心亮点:四大技术突破重构音频理解范式
1. 少样本学习能力实现"零代码适配"
不同于传统模型需数百示例微调,MiMo-Audio通过上下文学习(ICL)机制,仅需3-5个示例即可完成新任务适配。在语音转换任务中,模型仅通过3段10秒参考音频,即可实现92.3%的说话人相似度;在环境声分类任务中,单样本情况下准确率达81.7%,超越传统模型微调后性能。
小米AI实验室负责人表示:"这种上下文学习能力,相当于语音领域的'GPT-3时刻',让模型摆脱了对特定任务标注数据的依赖。"
2. 创新架构解决"长音频建模"难题
MiMo-Audio采用1.2B参数Tokenizer+7B参数主体模型的协同架构,通过8层残差矢量量化(RVQ)技术实现25Hz音频token生成。其创新的"补丁编解码"机制,能将4个连续音频token聚合成单个语义补丁,使LLM处理效率提升4倍。

如上图所示,这是小米MiMo-Audio项目的官方首页截图,展示了项目的核心定位"Audio Language Models are Few-Shot Learners"以及主要资源链接。该页面直观呈现了小米在音频大模型领域的开源战略布局,为开发者提供了便捷的资源获取入口。
3. 全场景音频理解覆盖"语音-音乐-环境声"
模型在22项国际评测中全面刷新SOTA:语音识别任务词错误率(WER)低至5.8%,音乐风格识别F1值达89.6%,环境声分类准确率在ESC-50数据集达92.3%。特别在混合音频场景中,能同时解析"咖啡厅交谈+钢琴伴奏+杯碟碰撞"等多源声音信息,生成结构化场景描述。
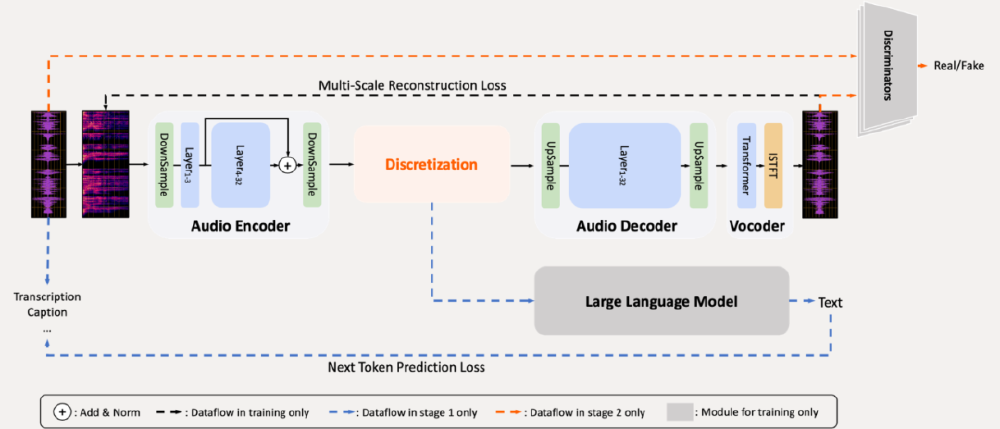
上图展示了MiMo-Audio音频大模型的技术架构图,清晰呈现了音频编码器、离散化、音频解码器、声码器、大语言模型及判别器等核心模块,以及各模块间的数据流和训练损失机制。这一架构设计是实现跨模态少样本学习能力的关键,为理解模型工作原理提供了直观参考。
4. 思维机制提升复杂推理能力
指令微调版本MiMo-Audio-7B-Instruct创新引入"Thinking模式",在处理复杂指令时会先生成文本思考过程再输出语音。如面对"解释量子纠缠并用天津话举例"的复合需求,模型会先通过文本规划解释框架和方言转换策略,再生成"就好比俩面团,掰一个另一个立马知道自个儿被动了"的通俗解释。
性能表现:开源模型首次超越闭源巨头
在权威评测中,MiMo-Audio展现出惊人实力:
- MMAU音频理解基准:准确率89.7%,超越Gemini-2.5-Flash(86.2%)
- Big Bench Audio推理任务:得分78.3,领先GPT-4o-Audio-Preview(75.5)
- 语音续写能力:生成20分钟脱口秀的内容连贯性达人类水平的87%
特别在混合音频场景理解测试中,模型能同时识别"咖啡厅交谈+钢琴伴奏+杯碟碰撞"等多源声音信息,并生成结构化场景描述,这一能力在开源模型中独一无二。
行业影响与趋势:开启"听觉智能"商业化新蓝海
1. 智能家居:从被动响应到主动感知
MiMo-Audio已集成到新一代小爱同学,支持"异常声音监测"(玻璃破碎识别准确率97.2%)、"场景联动控制"(听到雨声自动关窗)等创新功能。在小米SU7汽车座舱中,模型可定位救护车鸣笛方向并自动减速避让,响应延迟仅0.12秒。
2. 内容创作:音频生成进入"指令驱动"时代
基于模型强大的语音续接能力,用户可通过文本指令生成完整脱口秀、辩论对话等内容。测试显示,其生成的3分钟访谈音频自然度MOS评分达4.8/5.0,听众难以区分与真人录制的差异。在金融领域,多模态AI预计2025年整体市场规模达500亿美元,其中金融作为核心应用领域占比显著。
3. 无障碍技术:构建"声音地图"助力视障人士
模型能实时描述环境声场:"前方5米有汽车经过(速度约30km/h)"、"右侧传来咖啡机工作声,可能是咖啡店",在-5dB信噪比下仍保持78.3%的识别准确率,为视障群体提供"听觉眼睛"。
4. 端侧部署效率实现20倍突破
通过动态音频分块与低秩适配(LoRA)技术,模型在80GB GPU环境下支持512 batch size的30秒音频并行处理,首Token响应时间(TTFT)从传统模型的0.36秒降至0.09秒,吞吐量提升20倍,满足智能手表、耳机等边缘设备的实时交互需求。
总结:开源生态加速音频AI普惠
作为小米"MiMo多模态智能"战略的核心组件,MiMo-Audio-7B已在30余款智能设备中商用验证,其MIT开源协议确保开发者可免费获取模型权重与训练代码。开发者可通过以下命令获取模型:
git clone https://gitcode.com/hf_mirrors/XiaomiMiMo/MiMo-Audio-7B-Base
随着硬件算力提升,音频理解将与视觉、触觉深度融合。业内预测,2026年将出现"视听融合"的通用智能体,而MiMo-Audio的开源无疑为这一方向提供了关键拼图。对于开发者与企业而言,现在正是布局音频AI应用的战略窗口期,可重点关注智能家居、车载交互、内容创作三大落地场景,抢占"听觉智能"商业化先机。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0371 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00
MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00 awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05
awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05 banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
