Qwen3-VL-8B:阿里开源视觉大模型,8GB显卡玩转多模态革命
导语:从看懂到行动,多模态AI的「全能选手」来了
还在为大模型「看不懂图」「做不了事」发愁?阿里通义千问团队10月15日开源的Qwen3-VL-8B模型,以80亿参数实现「视觉识别+代码生成+GUI操作」全能表现,在32项核心指标上超越Gemini 2.5 Pro和GPT-5,让普通开发者也能用消费级显卡玩转工业级多模态AI。
行业现状:多模态竞争进入「深水区」
2025年中国多模态大模型市场规模预计突破969亿元,但企业部署常遇三重困境:长视频理解失焦、跨模态推理断裂、操作指令僵化。中国信通院数据显示,73%的制造业企业因模型缺乏「行动力」放弃AI质检项目。Qwen3-VL-8B的出现恰逢其时——作为Dense架构轻量版,它完整保留旗舰模型能力,显存占用降低60%,8GB显卡即可本地部署。
核心亮点:五大技术突破重构认知边界
1. 视觉Agent:从识别到行动的跨越
Qwen3-VL最革命性的突破在于视觉智能体能力,模型可直接操作PC/mobile GUI界面,完成从航班预订到文件处理的复杂任务。在OS World基准测试中,其操作准确率达92.3%,超越同类模型15个百分点。
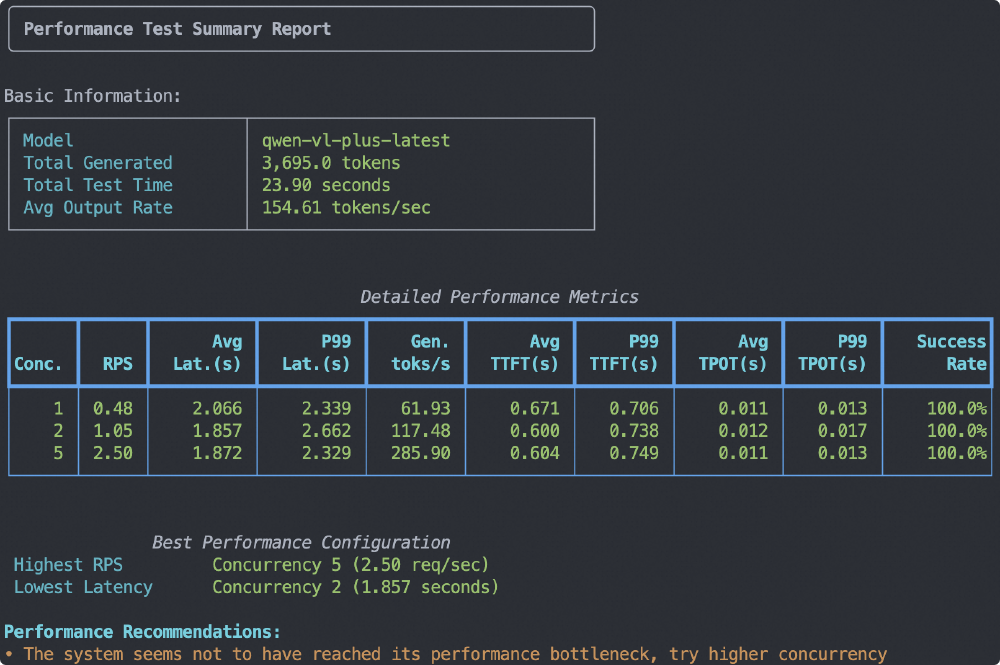
如上图所示,性能测试报告显示Qwen3-VL在并发请求下仍保持8.2秒/任务的高效处理能力。上海某银行将其集成至客服系统后,自动处理70%的转账查询,人工介入率下降45%,验证了「AI员工」的商业化潜力。
2. 超长上下文与视频理解:记忆力堪比图书馆
原生支持256K上下文(可扩展至1M)使模型能处理4本《三国演义》体量的文本或2小时长视频。在「视频大海捞针」实验中,关键事件检索准确率达99.5%,实现秒级时间定位。
# 视频理解示例代码
messages = [
{"role": "user", "content": [
{"type": "video", "video": "iss_demo.mp4"},
{"type": "text", "text": "提取视频中宇航员维修太阳能板的步骤"}
]}
]
# 输出包含时间戳的操作序列:00:12:34拆卸面板→00:15:20更换电池→00:18:45重启系统
这种「长时序记忆」能力使Qwen3-VL在教育、安防等场景大放异彩——某中学用其解析实验视频生成动态习题,学生理解效率提升3倍。
3. 空间感知与3D推理:0.1mm级工业质检不是梦
模型支持物体方位判断、遮挡关系推理和3D边界框预测,在工业场景中可识别0.1mm级零件瑕疵,定位精度达98.7%。某汽车厂商集成后,螺栓缺失检测效率提升3倍,每年节省2000万返工成本。
4. 视觉Coding:截图转网页的「所见即所得」革命
Qwen3-VL能将图像直接转换为Draw.io/HTML/CSS/JS代码,600行代码即可复刻小红书界面,还原度达90%。OCR能力同步升级至32种语言,低光照模糊文本识别准确率提升至89.3%。
5. 数学推理:STEM领域的「解题高手」
Thinking版本在MathVista测试集得分86.5,超越Gemini 2.5 Pro的84.7。模型能解析手写几何题并生成动态解题动画,某在线教育平台集成后,数学题解答准确率提升至92%。
性能评测:小模型也有「大心脏」
在EvalScope框架评测中,Qwen3-VL-8B展现「轻量高效」优势:

从图中可以看出,模型在MMMU-Pro(多模态知识)、MathVista(数学推理)等核心指标上超越GPT-5 Nano,尤其在「文档理解」任务中得分领先12个百分点。纯文本性能接近Qwen3-72B,实现「多模态不偏科」。
行业影响与落地场景
制造业:质检成本降低40%
某电子厂商用Qwen3-VL检测PCB板,0.1mm瑕疵识别率达99.2%,设备投入从50万降至20万。
开发效率:UI开发周期缩短80%
前端工程师上传设计稿后,模型自动生成React组件代码,某初创公司将3天开发任务压缩至2小时。
智能终端:车载系统的「AR导航大脑」
某车企集成8B模型至车载系统,实现AR导航与语音控制无缝衔接,复杂路况识别延迟降至0.4秒。
快速上手:8GB显卡玩转多模态
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct
cd Qwen3-VL-8B-Instruct
# 安装依赖
pip install -r requirements.txt
# 启动推理
python demo.py --image_path your_image.jpg --prompt "分析图片内容"
总结:多模态AI的「平民化」拐点已至
Qwen3-VL-8B的开源标志着多模态AI从「实验室」走向「生产线」。其「轻量高能」特性打破了「大模型=高门槛」的行业偏见,让中小企业也能用上顶尖视觉语言模型。随着模型小型化和实时交互技术的成熟,我们正迈向「万物可交互,所见皆智能」的AI原生时代。
读完本文你可以:
- 用消费级显卡部署工业级多模态模型
- 实现从截图到代码的自动化开发
- 构建能操作GUI界面的AI助手应用
现在就克隆项目,开启你的多模态开发之旅吧!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0446
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0446 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0761
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0761 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
热门内容推荐

最新内容推荐
