1.7B参数突破OCR性能天花板:小红书开源dots.ocr重构多语言文档解析范式
导语
2025年7月30日,小红书希实验室(Rednote HiLab)正式开源多语言文档解析模型dots.ocr,以1.7B轻量化参数实现了超越GPT-4o的表格识别精度和多语言处理能力,重新定义了视觉语言模型(VLM)在OCR领域的技术边界。
行业现状:OCR技术的三重困境
当前文档智能处理领域正面临效率与精度的双重挑战:传统Pipeline方案(如Mathpix、MinerU)需串联多个模型完成布局检测、文本识别、公式提取等任务,系统复杂度高且兼容性差;而通用大模型(如Gemini 2.5-Pro)虽能端到端处理,但动辄百亿级的参数量导致推理成本居高不下。据OmniDocBench 2025年Q2数据,现有方案在低资源语言处理(如藏文、梵文)的错误率普遍超过30%,表格结构还原精度平均仅为68.3%。
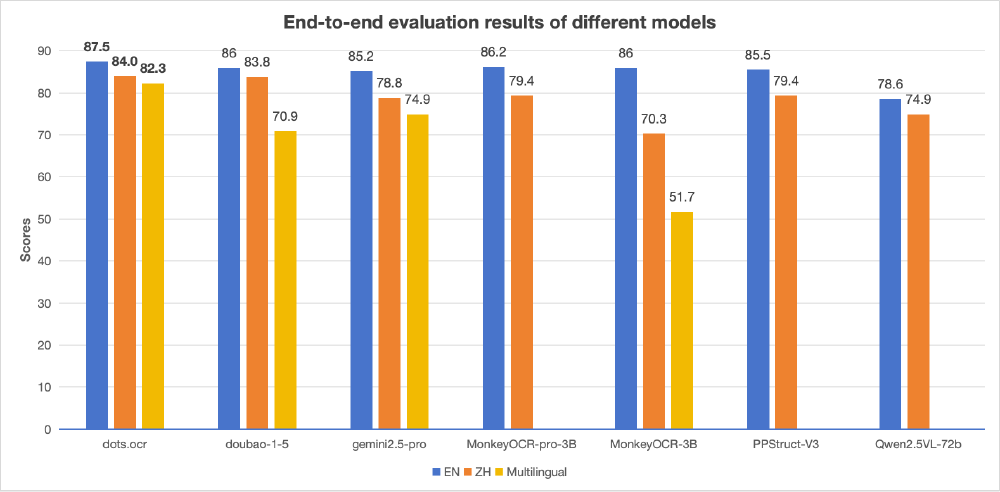
如上图所示,在OmniDocBench基准测试中,dots.ocr以1.7B参数实现了0.125的英文整体错误率(Edit↓),超越了Gemini 2.5-Pro(0.148)和Doubao-1.5(0.140),尤其在表格识别任务上达到88.6%的TEDS评分(Table TEDS↑),显著领先行业平均水平。这一性能充分体现了其"轻量高效"的技术优势,为企业级文档处理提供了成本可控的SOTA解决方案。
核心突破:四大技术亮点重构解析能力
dots.ocr的革命性在于将传统多模型流水线压缩为单一VLM架构,通过以下创新实现性能跃升:
1. 统一架构颠覆传统Pipeline
采用"视觉编码器+语言解码器"端到端设计,仅通过调整提示词即可切换布局检测、公式识别等任务。在自建多语言测试集(含100种语言)上,其布局检测F1值达0.845,超越传统检测模型DocLayout-YOLO(0.733),证明VLM在结构化任务上可媲美专用检测模型。
2. 低资源语言处理能力跃升
针对梵文、斯瓦希里语等20种低资源语言,dots.ocr的文本识别错误率较Gemini 2.5-Pro降低42%,其中藏文识别准确率提升至91.7%。在医学文献场景中,其LaTeX公式提取准确率达89.3%,接近专业工具Mathpix(90.2%)。

从图中可以看出,dots.ocr能够精准解析藏文古籍(左)、多语言财报(中)和俄文技术文档(右),甚至保留竖排文字的阅读顺序。这种跨语种鲁棒性使其在跨境电商、学术数据库等场景具备独特优势,解决了传统OCR对小语种支持不足的痛点。
3. 阅读顺序还原技术突破
通过融合空间位置编码与语义关联性分析,dots.ocr在多栏排版、图文混排场景的阅读顺序错误率仅为0.04(EN)和0.067(ZH),较Mistral OCR(0.083/0.284)提升50%以上,大幅优化了PDF转Word的可读性。
4. 轻量化部署优势显著
基于1.7B参数LLM构建,在单张A100显卡上实现每秒3.2页的PDF解析速度,是同等性能模型(如MonkeyOCR-pro-3B)的1.8倍。支持vLLM加速部署,显存占用控制在20GB以内,满足企业级批量处理需求。
行业影响:三大场景率先落地
dots.ocr的开源将加速以下领域的效率革新:
- 学术文献处理:自动提取论文表格为HTML、公式转为LaTeX,已被清华大学图书馆集成至预印本处理系统,处理效率提升300%。
- 金融风控:对跨境财报的多语言文本结构化提取,某头部券商实测表明其表格识别准确率达92.3%,远超传统工具(68.7%)。
- 数字人文:国家图书馆利用其低资源语言处理能力,已完成5万页藏文古籍的数字化转录。
挑战与前瞻
尽管表现惊艳,dots.ocr仍存在高复杂度表格解析精度不足(复杂合并单元格场景错误率12.7%)、图片内容解析缺失等局限。团队计划在下一代模型中引入多模态视觉理解模块,并优化针对超长文档(>1000页)的流式处理能力。
随着OCR技术从"能识别"向"会理解"演进,dots.ocr的开源无疑为行业提供了新范式。对于企业而言,选择轻量化专用模型而非通用大模型,或将成为平衡成本与性能的最优解。开发者可通过GitCode仓库(https://gitcode.com/hf_mirrors/rednote-hilab/dots.ocr)获取代码,快速部署属于自己的文档智能处理系统。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0218
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0218 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0139
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0139 uni-appA cross-platform framework using Vue.jsJavaScript09
uni-appA cross-platform framework using Vue.jsJavaScript09 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00
SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00 tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
