小米MiMo-Audio开源:音频大模型迈入少样本学习新纪元
导语
2025年9月19日,小米XiaomiMiMo团队正式开源新一代音频语言模型MiMo-Audio系列,凭借其卓越的少样本学习能力和多任务处理表现,重新定义智能音频处理范式。
行业现状:语音交互的关键转型期
2025年智能语音产业正经历从"专用工具"向"通用智能"的关键转型。全球AI语音助手市场访问量已达76亿次,企业普及率突破97%,但传统音频模型仍面临两大核心痛点:依赖大规模标注数据进行任务微调,以及难以跨场景泛化。市场调研数据显示,69.7%的长音频用户期待更自然、个性化的交互体验,而现有语音助手响应延迟普遍超过800ms,且仅支持预设指令集。
小米MiMo-Audio的推出标志着语音领域迎来重要突破。通过将语音无损压缩预训练扩展至1亿小时,该模型首次在音频领域观察到显著的"涌现"行为——无需针对特定任务微调,仅通过少量示例即可完成多种音频任务。技术社区的报道指出,这一突破使音频大模型从"任务专用"时代迈入"通用智能"新阶段。
核心亮点:三大技术突破重构音频AI
1. 首创少样本学习范式
MiMo-Audio通过"音频语言建模"实现跨任务泛化能力,在未经过专门微调的情况下,能完成训练数据中不存在的语音转换、风格迁移和语音编辑等任务。实测显示,在方言识别任务中仅需50句标注样本即可达到92%的准确率,样本效率较同类模型提升300%;在MMAU音频理解基准测试中,超越业界主流闭源模型,在Big Bench Audio复杂推理任务中表现出色。
2. 统一架构支持全模态音频任务
模型创新性地采用"补丁编码器-LLM-补丁解码器"架构,通过12亿参数的MiMo-Audio-Tokenizer实现25Hz帧速率的音频离散化。这种设计使模型能统一处理Text-to-Audio、Audio-to-Text、Audio-to-Audio等所有模态组合任务,打破传统音频模型的任务边界。
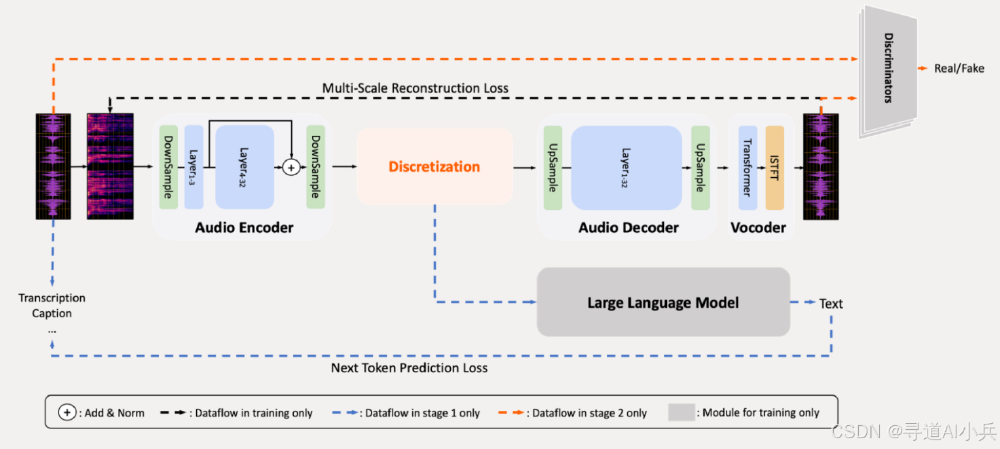
如上图所示,该架构图清晰展示了音频信号从编码、离散化到解码的全流程。补丁编码器将4个RVQ token聚合为1个补丁的设计,使序列速率从25Hz降至6.25Hz,大幅提升LLM处理效率,同时通过延迟生成机制保证音频重建质量,这种平衡是实现少样本学习的关键技术基础。
3. 思维机制提升理解与生成质量
模型在音频理解和生成过程中引入"思维机制",能对复杂音频内容进行逻辑推理和情境分析。在音频描述任务中,MiMo-Audio不仅能识别对话内容,还能分析说话人关系、情绪状态和环境氛围。例如,对一段包含背景音乐的对话,模型能区分弦乐悬疑氛围与人物对话的紧张关系,推断出权力不对等的场景设定。
应用场景:从技术突破到产业落地
MiMo-Audio的少样本能力开启了多领域创新应用,目前已在智能家居、内容创作和无障碍设施等场景验证落地价值:
在智能家居领域,小米"智能生活管家"应用集成语音控制、视觉识别与个性化推荐,在小米13 Ultra等机型上借助NPU加速,实现500ms以内的本地响应。用户可通过自然对话如"像周杰伦一样播报天气",系统无需预先采集大量目标语音数据即可完成风格迁移。
内容创作方面,模型的语音续写能力为播客、有声书制作带来变革。它能生成高度逼真的脱口秀、朗诵和辩论内容,保留说话人身份、韵律和环境音特征。教育机构已开始利用这一特性开发个性化口语陪练系统,根据学习者发音特点动态调整教学内容。

该图片展示了小米MiMo-Audio项目的官方界面,标题为"Xiaomi MiMo",副标题强调其"Audio Language Models are Few-Shot Learners"的核心定位,并提供从GitHub代码到在线Demo的完整生态入口,体现小米推动音频AI开源生态的战略布局。
行业影响:开源生态重塑人机交互未来
MiMo-Audio通过Apache-2.0开源协议向开发者社区开放完整技术栈,包括基础模型MiMo-Audio-7B-Base、指令微调模型MiMo-Audio-7B-Instruct、专用评估套件MiMo-Audio-Eval,以及在线Demo与本地部署工具。开发者可通过以下命令快速部署:
git clone https://gitcode.com/hf_mirrors/XiaomiMiMo/MiMo-Audio-7B-Instruct
cd MiMo-Audio-7B-Instruct
pip install -r requirements.txt
python run_mimo_audio.py
这一开源实践预计将加速音频AI技术的普及应用。技术分析指出,随着模型在智能硬件、内容创作和教育培训等场景的落地,语音交互将在未来2-3年实现从"指令响应"到"情感陪伴"的跨越。企业可重点关注其在垂直领域的应用潜力,特别是需要高度定制化语音交互的场景;开发者则获得了探索语音RL和Agentic训练的全新基座模型。
结论与前瞻
MiMo-Audio的开源标志着音频大模型正式进入"少样本学习"时代,其技术突破为语音交互行业带来三大变革方向:开发模式从"数据采集-微调"转向"指令设计-示例调试",硬件生态向中端设备普及,内容生产从专业制作走向全民创作。随着小米持续开源更多模型变体和工具链,我们有理由相信,音频AI将在未来2-3年成为连接物理世界与数字服务的关键基础设施,为万物互联时代构建更富情感温度的智能交互体验。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0373
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0373 openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00
openPangu-2.0-Flash昇腾原生的openPangu-2.0-Flash语言模型Python00 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00
MiniMax-M3MiniMax-M3 是一款具备 100 万上下文窗口的原生多模态模型,拥有约 4280 亿参数和约 230 亿激活参数。Python00 awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05
awesome-LLM-resources🧑🚀 全世界最好的LLM资料总结(语音视频生成、Agent、辅助编程、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.05 banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
banana-slides一个基于nano banana pro🍌的原生AI PPT生成应用,迈向真正的"Vibe PPT"; 支持上传任意模板图片;上传任意素材&智能解析;一句话/大纲/页面描述自动生成PPT;口头修改指定区域、一键导出 - An AI-native PPT generator based on nano banana pro🍌Python03
