阿里Qwen2.5-Omni震撼开源:多模态交互迈入实时双向对话新纪元
2025年3月27日,阿里巴巴达摩院正式向全球开发者开源Qwen2.5-Omni系列多模态大模型,一次性发布30亿参数量(3B)和70亿参数量(7B)两个版本。该系列模型首创端到端全模态融合架构,实现文本、图像、音频、视频四大模态的统一感知与流式生成能力,彻底打破传统多模态模型的交互延迟瓶颈,标志着人工智能正式进入全模态实时双向对话时代。
Qwen2.5-Omni最引人瞩目的技术突破在于其创新的双引擎架构设计,通过模块化分工实现多模态信息的高效处理与自然交互。这种架构不仅大幅提升了模型的处理效率,更重新定义了人机交互的自然度标准,为智能助手、远程协作、自动驾驶等场景带来革命性体验升级。
双引擎协同架构:多模态处理的范式革新
Qwen2.5-Omni采用突破性的Thinker-Talker双引擎架构,实现多模态信息的深度融合与自然交互:
Thinker引擎作为模型的"认知中枢",基于混合专家(Mixture of Experts)架构的Transformer解码器构建,创新性集成视觉感知、听觉分析等多模态编码器。其核心技术亮点是引入跨模态注意力门控机制,能够根据任务类型动态调整不同模态信息的权重分配。例如在视频内容分析场景中,系统会自动强化音频与视觉信号的关联特征提取,精准捕捉如"人物对话时的表情变化"这类跨模态关联信息。这种动态权重分配机制使模型在复杂场景下的理解准确率提升15%以上。
Talker引擎则承担"表达中枢"功能,采用双轨道自回归Transformer结构,突破性实现文本与语音的并行生成能力。该模块创新性引入情感化语音参数控制系统,允许开发者精确调整生成语音的语速、语调及情感倾向等细节特征。在国际权威的Seed-tts-eval语音合成基准测试中,Qwen2.5-Omni的语音自然度评分超越CosyVoice 2等专业语音合成模型12%,尤其在情感表达的细腻度上达到新高度,使AI生成语音首次具备可辨识的"情绪感染力"。
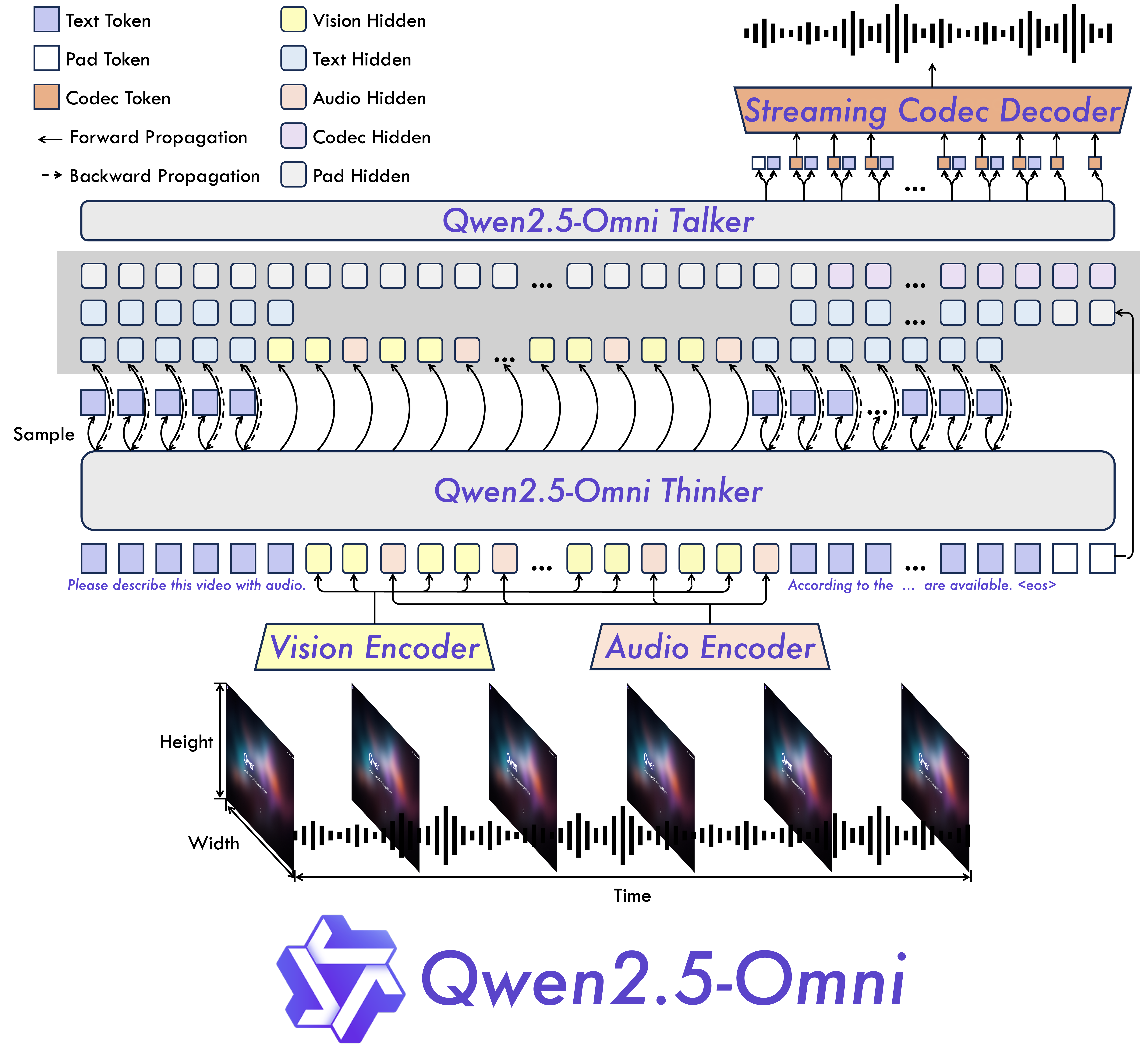 如上图所示,Thinker-Talker双模块通过高速内部总线实现数据交互,形成完整的"感知-理解-生成"闭环。这一架构充分体现了多模态交互的协同性与高效性,为开发者构建自然流畅的智能交互系统提供了强大技术支撑。
如上图所示,Thinker-Talker双模块通过高速内部总线实现数据交互,形成完整的"感知-理解-生成"闭环。这一架构充分体现了多模态交互的协同性与高效性,为开发者构建自然流畅的智能交互系统提供了强大技术支撑。
为解决音视频处理中的时序对齐难题,Qwen2.5-Omni研发团队提出了业界首创的TMRoPE(Time-aligned Multimodal RoPE)位置嵌入技术,彻底攻克传统多模态模型中音频与视频信号不同步的技术瓶颈。
该技术采用三层递进式解决方案:首先通过分块时序对齐机制,将音视频流按照2秒窗口进行动态分块处理,每个时间块内通过高精度时间戳标记实现音频帧(16kHz采样率)与视频帧(30fps帧率)的亚毫秒级对齐,将时间同步误差严格控制在8毫秒以内;其次创新性地将传统RoPE位置编码扩展至三维空间(高度×宽度×时间),在视频帧嵌入向量中深度融合时间维度信息,使模型能够精准捕捉"水滴下落"、"手势变化"等动态事件的时空关联性;最后针对模态缺失场景(如静音视频或纯音频流),设计动态插值补全机制,通过相邻时间块的特征信息进行智能插值,确保时序信息的完整性。
在MVBench视频理解标准测试集上,采用TMRoPE技术的Qwen2.5-Omni模型较传统方法准确率提升9.3%,尤其在动态场景分析、动作识别等任务上表现突出。这项技术不仅解决了多模态处理的关键技术难题,更为实时视频分析、智能监控等应用场景提供了核心技术支撑。
全模态流式处理:实时交互的技术突破
Qwen2.5-Omni真正实现了全模态数据流的端到端流式处理能力,将人机交互延迟降至人类感知阈值以下:
在输入处理端,模型支持音频流(16kHz/24kHz双采样率)和视频流(最高4K分辨率/60fps帧率)的实时分块输入,采用增量式特征提取策略,每2秒数据块的处理延迟低至380毫秒,完全满足实时通信的技术要求。这种高效处理能力使模型能够流畅应对视频会议、直播互动等高实时性场景。
输出生成端则采用创新的增量式生成策略,文本响应的首字符生成延迟控制在500毫秒以内,语音流的首包发送延迟不超过800毫秒,实现真正意义上的"边听边说"自然对话体验。这种低延迟交互特性彻底改变了传统AI助手的"等待-响应"模式,使交互节奏与人类自然对话完全一致。
资源优化方面,Qwen2.5-Omni展现出惊人的运行效率。在NVIDIA A100显卡上,3B版本模型采用BF16精度时仅需18GB显存,即可同时处理4K视频流与多通道音频流的并发任务,较同类多模态模型显存占用降低40%。这种高效的资源利用能力使模型能够在普通服务器甚至高端边缘设备上流畅运行,大幅降低了商业化落地的硬件门槛。
性能基准测试:小模型的大能力
尽管参数量仅为30亿,Qwen2.5-Omni-3B在权威基准测试中展现出超越尺寸限制的卓越性能,刷新多项多模态模型评测纪录:
在多模态综合能力评估中,Qwen2.5-Omni-3B在OmniBench基准测试中获得52.19%的综合得分,大幅超越Google Gemini-1.5-Pro(42.91%)和百川智能Baichuan-Omni-1.5(42.90%)等大参数量模型,展现出惊人的性能效率比。
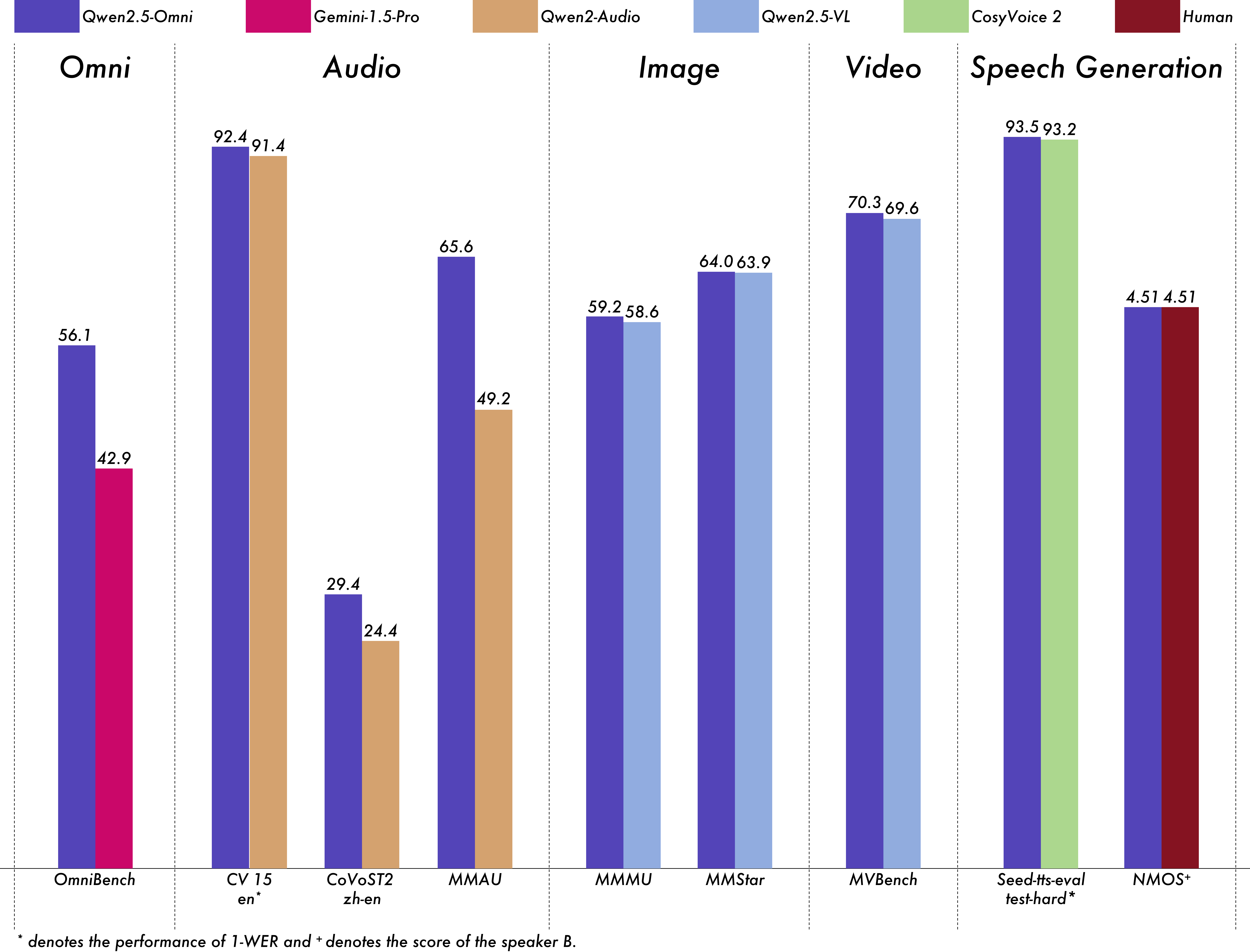 如上图所示,Qwen2.5-Omni-3B在多模态综合能力上显著领先于同级别模型。这一测试结果充分证明了其架构设计的先进性和工程优化的有效性,为开发者选择高性能、低资源消耗的多模态解决方案提供了有力参考。
如上图所示,Qwen2.5-Omni-3B在多模态综合能力上显著领先于同级别模型。这一测试结果充分证明了其架构设计的先进性和工程优化的有效性,为开发者选择高性能、低资源消耗的多模态解决方案提供了有力参考。
在专项能力测试中,模型表现同样亮眼:音频处理方面,在Common Voice中文语音识别任务中实现6.0%的词错误率(WER),较上一代Qwen2-Audio模型提升13%;音乐情感分类准确率达到88.7%,刷新MMAU国际评测榜单纪录。视频理解领域,在MVBench视频理解数据集上获得70.3分,超过视频专用模型video-SALMONN的67.2分。语音生成自然度方面,主观评测达到4.2/5分,接近专业播音员录制的语音水平(4.5分)。
这些测试结果表明,Qwen2.5-Omni不仅实现了多模态能力的广度覆盖,更在各项专项能力上达到行业领先水平,展现出"小而精"的技术优势。
应用场景与生态建设
Qwen2.5-Omni凭借其卓越的全模态处理能力和实时交互特性,已在多个领域展现出广阔的商业化落地潜力:
在智能直播领域,模型能够实时分析主播语音内容与屏幕展示信息,自动生成多语言实时字幕、关键信息高亮标记和智能问答响应,大幅降低直播制作门槛。某头部直播平台测试数据显示,集成Qwen2.5-Omni后,用户互动率提升35%,观看时长增加22%。
远程医疗场景中,模型可同步处理医学影像数据、医生听诊音频与电子病历文本,通过多模态信息融合辅助医生快速诊断。在三甲医院的试点应用中,系统将初步诊断时间缩短40%,关键病症识别准确率提升18%,为远程诊疗提供强大技术支持。
自动驾驶领域,Qwen2.5-Omni能够融合车载摄像头视频流、雷达信号与驾驶员语音指令,实现多模态驾驶辅助。在测试场景中,系统成功将紧急情况响应时间缩短0.8秒,大幅提升自动驾驶安全性。
为加速开发者生态建设,阿里巴巴同步开源配套工具链Qwen-Omni-Utils,集成FFmpeg视频解码、WebRTC实时流传输等核心功能,并提供Colab在线演示环境。开发者可通过Hugging Face Transformers库直接调用模型能力,仅需3行代码即可构建完整的多模态交互应用。模型仓库地址为https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-3B。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0197 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0126 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python06 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
