Forte:将优秀软件工程实践引入机器学习解决方案
项目介绍
Forte 是一个以数据为中心的框架,旨在为复杂的机器学习工作流程提供工程化的解决方案。Forte 允许从业者以可组合和模块化的方式构建机器学习组件。在其背后,Forte 引入了 DataPack,这是一种用于非结构化数据的标准化数据结构,将良好的软件工程实践(如可重用性、可扩展性和灵活性)融入到机器学习解决方案中。
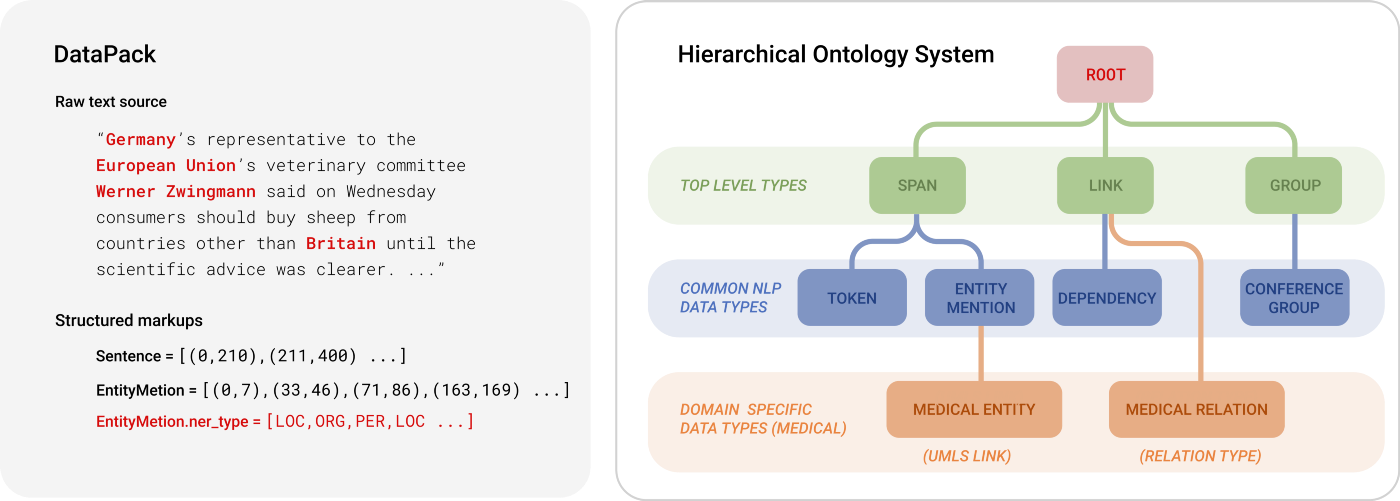
DataPack 是机器学习工作流程中的标准数据包,可以表示源数据(如文本、音频、图像)和附加标记(如实体提及、边界框)。它由一个名为“Ontology”的可定制数据模式驱动,允许领域专家轻松地将他们的知识注入到机器学习工程过程中。
项目技术分析
Forte 的核心技术在于其数据结构 DataPack 和 Ontology 模式。DataPack 提供了一种标准化的方式来表示和处理非结构化数据,使得不同组件之间的数据交换变得简单和一致。Ontology 模式则允许用户根据特定领域的需求自定义数据结构,从而实现高度的灵活性和可扩展性。
Forte 还支持多种外部库和工具的集成,如 SpaCy、NLTK 等,通过这些集成,用户可以轻松地将现有的工具和模型整合到 Forte 的工作流程中。此外,Forte 提供了丰富的组件和模块,涵盖了数据增强、信息检索、音频处理等多个领域,满足了不同应用场景的需求。
项目及技术应用场景
Forte 适用于需要复杂数据处理和机器学习工作流程的场景。例如:
- 自然语言处理(NLP):Forte 可以用于构建文本分析、情感分析、命名实体识别等 NLP 任务的管道。
- 音频处理:通过 Forte 的音频支持模块,用户可以构建音频分类、语音识别等应用。
- 信息检索:Forte 的信息检索模块可以帮助用户构建高效的搜索和推荐系统。
- 数据增强:Forte 的数据增强模块可以用于生成更多的训练数据,提高模型的泛化能力。
项目特点
- 模块化设计:Forte 的组件设计使得用户可以轻松地组合和重用不同的模块,从而快速构建复杂的机器学习工作流程。
- 可扩展性:通过 Ontology 模式,用户可以根据自己的需求自定义数据结构,实现高度的可扩展性。
- 集成支持:Forte 支持与多种外部库和工具的集成,使得用户可以利用现有的资源和模型。
- 标准化数据结构:DataPack 提供了一种标准化的数据结构,简化了数据处理和组件之间的数据交换。
总结
Forte 是一个强大的数据中心框架,它将优秀的软件工程实践引入到机器学习解决方案中,使得复杂的机器学习工作流程变得更加简单和高效。无论你是 NLP 专家、音频处理工程师,还是信息检索爱好者,Forte 都能为你提供一个灵活、可扩展的平台,帮助你快速构建和部署机器学习应用。
立即访问 Forte 的 GitHub 页面 开始你的机器学习工程之旅吧!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust099
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust099- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 MiMo-V2.5-ProMiMo-V2.5-Pro作为旗舰模型,擅⻓处理复杂Agent任务,单次任务可完成近千次⼯具调⽤与⼗余轮上 下⽂压缩。Python00
MiMo-V2.5-ProMiMo-V2.5-Pro作为旗舰模型,擅⻓处理复杂Agent任务,单次任务可完成近千次⼯具调⽤与⼗余轮上 下⽂压缩。Python00 GLM-5.1GLM-5.1是智谱迄今最智能的旗舰模型,也是目前全球最强的开源模型。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。Jinja00
GLM-5.1GLM-5.1是智谱迄今最智能的旗舰模型,也是目前全球最强的开源模型。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。Jinja00 Kimi-K2.6Kimi K2.6 是一款开源的原生多模态智能体模型,在长程编码、编码驱动设计、主动自主执行以及群体任务编排等实用能力方面实现了显著提升。Python00
Kimi-K2.6Kimi K2.6 是一款开源的原生多模态智能体模型,在长程编码、编码驱动设计、主动自主执行以及群体任务编排等实用能力方面实现了显著提升。Python00 MiniMax-M2.7MiniMax-M2.7 是我们首个深度参与自身进化过程的模型。M2.7 具备构建复杂智能体应用框架的能力,能够借助智能体团队、复杂技能以及动态工具搜索,完成高度精细的生产力任务。Python00
MiniMax-M2.7MiniMax-M2.7 是我们首个深度参与自身进化过程的模型。M2.7 具备构建复杂智能体应用框架的能力,能够借助智能体团队、复杂技能以及动态工具搜索,完成高度精细的生产力任务。Python00
热门内容推荐

最新内容推荐
