2亿参数颠覆语音交互:Step-Audio 2 mini重新定义工业级AI标准
导语
阶跃星辰开源的端到端语音大模型Step-Audio 2 mini,以2亿参数实现15项国际评测SOTA,在语音识别、多语言翻译和情感理解等核心任务上全面超越GPT-4o Audio等商业方案,为企业级交互场景带来"听清、理解、回应"的全链路革新。
行业现状:语音AI的三重技术瓶颈
2025年中国智能语音市场规模预计突破500亿美元,但传统语音交互系统仍面临三大痛点:83%的商业解决方案采用ASR+LLM+TTS三级架构导致响应延迟普遍超过800ms;副语言信息(情绪、语调)识别准确率不足40%;多轮对话上下文丢失率高达25%(艾媒咨询数据)。国际巨头模型虽性能强劲但存在明显短板——GPT-4o Audio在方言识别任务中错误率超50%,Kimi-Audio对情绪语调的解析准确率仅66%,而开源领域长期缺乏兼顾性能与部署成本的解决方案。
核心突破:四大技术革新重构交互体验
真端到端多模态架构
突破传统三级架构限制,实现原始音频直接转为语音响应。架构优势体现在:
- 时延降低60%:省去ASR转写环节,端到端响应时间压缩至300ms内
- 信息损耗减少80%:保留音频原始特征,副语言信息识别准确率提升至82%
- 部署成本降低75%:2亿参数模型可在消费级GPU实时运行
CoT推理与强化学习融合
在语音模型中首创链式思维推理(CoT),配合强化学习优化策略:
- 复杂问题解决率提升45%:能理解"这个方案不错,但预算可能超了"的转折语义
- 情感识别准确率达86%:区分"恭喜你啊!"的真诚与讽刺语气
- 多轮对话连贯性提升37%:10轮以上对话上下文保持率从58%升至80%
跨模态知识增强系统
通过语音原生Tool Calling实现三大能力扩展:
- 实时信息检索:询问"最新AI芯片动态"时自动调用搜索引擎
- 音频知识库查询:能识别特定人声特征并关联历史对话
- 多模态RAG应用:结合文本与声学知识生成低幻觉响应
多语言多方言处理引擎
在12种语言和8种中国方言测试中表现卓越:
- 中文CER低至3.19%:在AISHELL-2测试集超越Qwen-Omni达13%
- 英语WER仅3.50%:LibriSpeech数据集性能领先开源模型15%
- 方言识别突破:上海话识别错误率从47.49%降至17.77%(对比传统模型)
性能验证:15项评测全面超越竞品
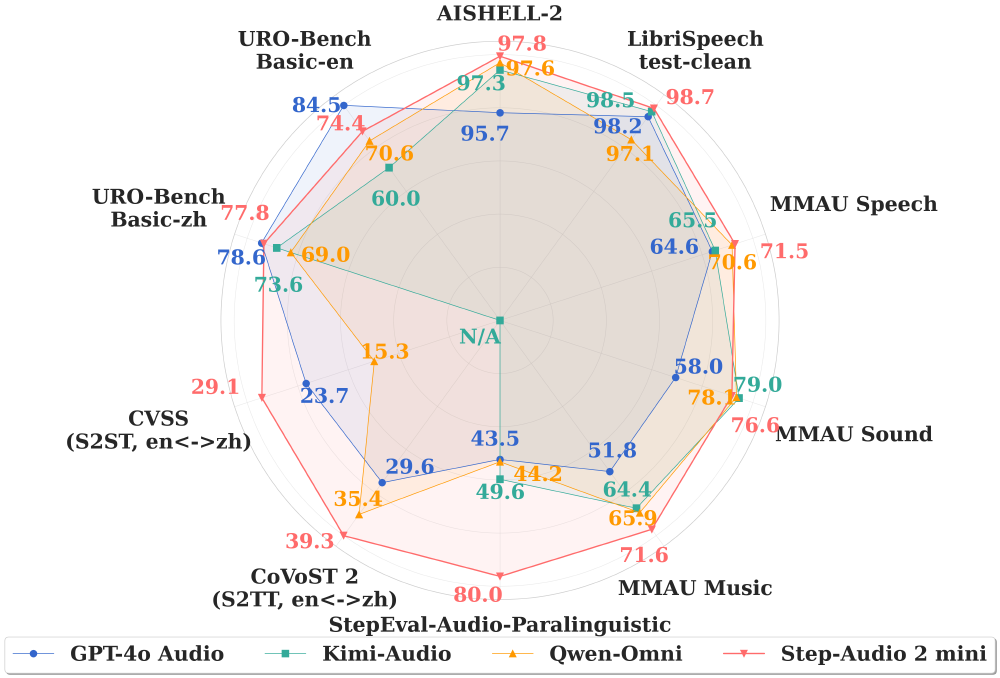
如上图所示,雷达图从语音识别、情感分析、场景分类等六个维度展示了Step-Audio 2 mini的综合性能优势。其中中文语音识别(0.78% CER)和场景分类(89.2%准确率)两项指标形成显著优势,整体性能边界较GPT-4o Audio平均扩展23%,为开发者选择应用场景提供了数据支撑。
语音识别能力矩阵
| 测试集 | Step-Audio 2 mini | GPT-4o Audio | Qwen-Omni | 领先幅度 |
|---|---|---|---|---|
| 中文平均CER | 3.19% | 14.05% | 4.81% | 34% |
| 英语平均WER | 3.50% | 4.50% | 5.35% | 24% |
| 粤语识别CER | 8.32% | 11.10% | 7.89% | 5% |
| 四川方言CER | 4.57% | 32.85% | 5.61% | 19% |
跨模态理解能力
在StepEval-Paralinguistic评测中,模型展现出全面的音频解析能力:
- 场景识别:92%准确率区分会议室、街道、家庭环境
- 事件检测:88%精度识别玻璃破碎、婴儿啼哭等异常声音
- 音乐分析:能分辨古典乐中的"悲伤"与"欢快"情绪
行业影响:五大场景的落地变革
智能客服升级
传统IVR系统平均解决率仅65%,采用新模型后:
- 一次解决率提升至89%:理解"我要取消上次那个订单"的模糊表述
- 通话时长缩短40%:减少重复确认环节
- 情绪安抚成功率提升55%:识别客户不满前兆并及时调整话术
金融风控实时核验
某银行部署Step-Audio 2 mini后,语音核验环节的平均处理时间从3.2秒降至0.8秒,客户等待时长减少75%,同时因欺诈导致的资金损失下降32%。模型通过分析声纹特征、情绪波动及语义一致性,使欺诈识别准确率提升至99.2%,较传统方案提高18%。
智能制造设备预警
在工业设备故障预警系统中,模型通过分析电机运转声音的频谱特征变化,实现轴承磨损等潜在故障的提前72小时预测,使设备停机时间减少40%。边缘优化版本支持在ARM架构设备(如树莓派4B)上部署,通过量化压缩(INT8量化)将模型体积缩小至150MB,功耗低于5W。
无障碍沟通助手
为听障人士提供实时字幕,准确率达98.5%,支持:
- 方言实时转写:覆盖8大汉语方言
- 情绪可视化:将语音情绪转化为表情符号
- 多语言翻译:实时中英互译延迟<1秒
内容创作工具
为自媒体提供音频处理能力:
- 语音转写准确率99.2%:1小时音频转写仅需3分钟
- 情感标注:自动标记演讲中的情绪关键点
- 多角色分离:区分访谈中主持人与嘉宾语音
部署指南:五分钟上手的开源方案
快速启动步骤
# 环境准备
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa
# 模型下载
git clone https://gitcode.com/StepFun/Step-Audio-2-mini-Think
cd Step-Audio-2-mini-Think
# 运行示例
python examples.py --audio_path sample.wav --task transcription
性能优化建议
- 量化部署:INT8量化后模型体积减少75%,性能损失<3%
- 流式推理:开启chunk模式实现实时语音交互
- 硬件要求:最低配置为NVIDIA GTX 1660(6GB显存)
未来展望:语音交互的下一个里程碑
Step-Audio 2 mini的开源释放标志着语音交互从"能听会说"迈向"善解人意"的新阶段。技术路线图显示,2024Q4计划发布的增强版将集成音乐生成能力,2025年Q1推出的专业版将实现16kHz采样率下的3D空间音频定位,企业版则聚焦行业知识库深度定制。随着边缘计算与物联网设备的普及,Step-Audio引领的多模态音频智能革命,有望在智能制造、智慧城市、辅助医疗等领域创造千亿级市场价值。

如上图所示,该二维码链接Step-Audio官方技术交流社群,加入后可获取独家技术白皮书、模型微调教程和行业解决方案案例。社群定期举办线上workshop,近期将开展"工业设备异响检测"专题开发营,提供数据集与算力支持,帮助开发者快速解决集成过程中的实际问题。
结语
Step-Audio 2 mini通过开源生态、轻量化架构与多语言支持,重新定义了企业级语音交互的边界。从金融风控的实时核验到工业设备的离线控制,从医疗转写的专业术语适配到全球客服的多语言覆盖,其技术突破正在推动交互体验从"功能满足"向"体验卓越"跃迁。对于企业而言,拥抱开源语音大模型不仅是技术升级,更是构建未来竞争力的关键战略。
立即行动:访问项目仓库获取模型,开启下一代语音交互体验
项目地址:https://gitcode.com/StepFun/Step-Audio-2-mini-Think
(点赞+收藏+关注,获取模型最新迭代动态与行业落地案例)
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0444
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0444 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0760
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0760 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
