推荐项目:Jesth - 打造灵活的人读数据格式新时代
项目介绍
在众多配置文件和数据交换格式的丛林中,一个名为Jesth的新星脱颖而出,它不仅仅是另一种数据格式,而是定义了数据表述的全新维度。Jesth,发音为/dʒest/,意即“提取段落然后对其进行操作”,是Pyrustic Open Ecosystem的一部分,专为渴望自由解析格式和追求高度灵活性的开发者设计。这一项目通过其独特的设计理念,使得单一文档能够融合文本、配置、脚本乃至更多复杂结构,彻底打破常规格式如TOML,YAML,和JSON的界限。
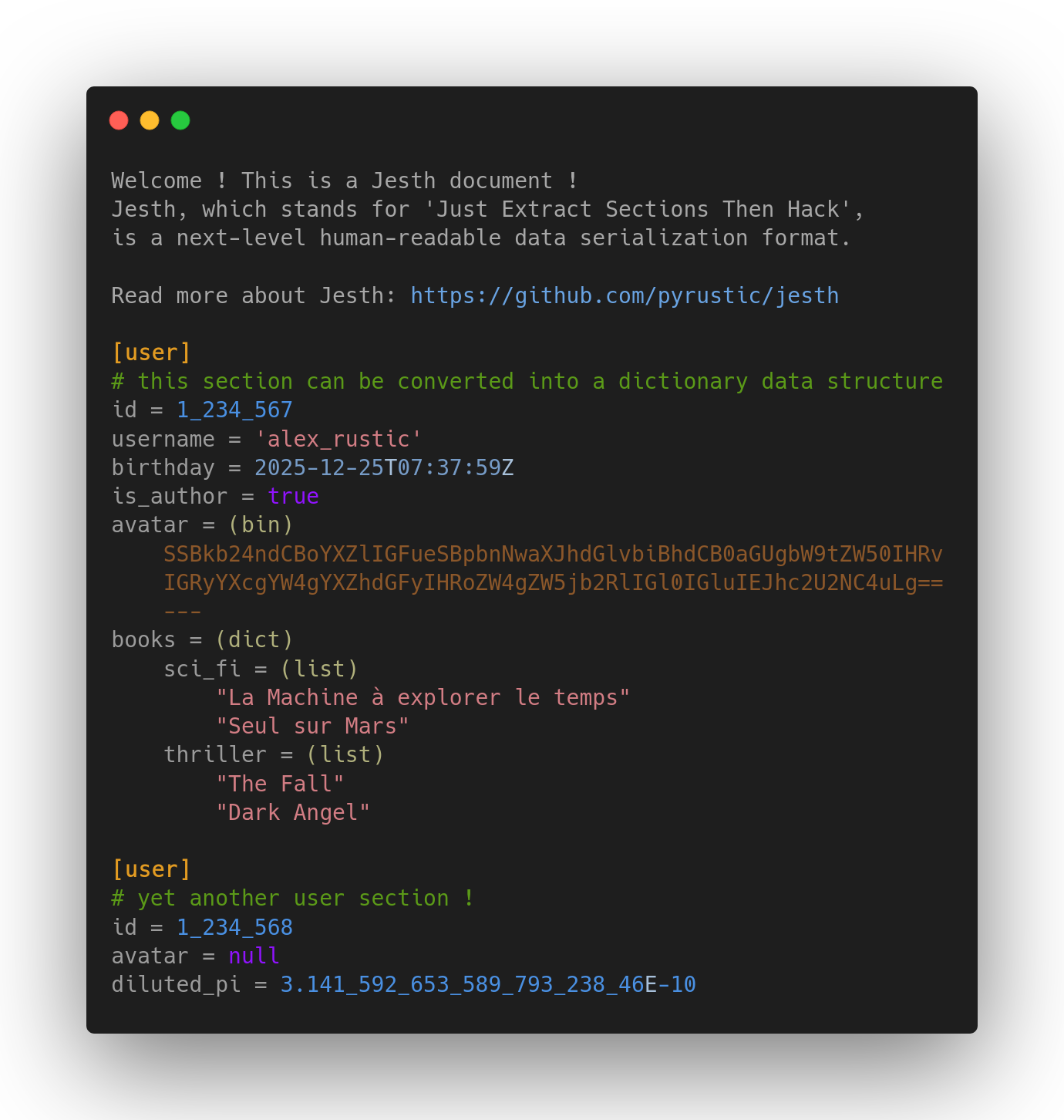 示例:Jesth文档,包含匿名顶部分区及两个“用户”分区
示例:Jesth文档,包含匿名顶部分区及两个“用户”分区
技术分析
Jesth的核心在于它的分段式处理思想,每个数据块都由【标题】和【正文】构成,这种设计鼓励程序员按需解释和处理数据,而非格式强制规定。这一点尤其体现在其对【字典段落】的支持上,不仅支持标准的数据类型,如字符串(单行或多行)、标量、日期时间、二进制数据等,还允许复杂的集合类型(嵌套字典和列表),且保持语法简洁明了。
在技术实现层面,Jesth的轻量化Python库提供了直观的API来加载和卸载这些字典段落,并可选择保留注释和空白,极大提升了代码的可读性和维护性。它利用Python的强大功能,结合自定义解析逻辑,实现了对数据结构的高效编码与解码。
应用场景
Jesth的应用边界几乎不受限制。从配置管理到AI聊天脚本编写,再到个人笔记整理,甚至作为特殊标记语言用于自动生成项目文档,它的高灵活性让其成为多种情境下的优选工具。例如,在共享数据存储和交互场景中,Jesth充当着关键角色,正如在Pyrustic的Shared项目中的应用展示。
项目特点
- 极致灵活性:允许用户自由定义各段落的意义和处理方式。
- 兼容性与易读性:借鉴TOML的简单和JSON的直接性,但更进一步,提供无限的预留词空间,如【[[END]]】标志,支持文档分割。
- 全面的字典段落支持:严格的语法确保数据整洁,同时也支持注释,非常适合需要清晰文档化的配置或脚本编写。
- API友好:无论是加载文档、获取或修改段落,还是渲染回文本,Jesth提供的API都是直观且强大的。
- 可定制化解析:处理不可转换段落时,提供异常控制和默认值设置,增加错误处理的灵活性。
随着Jesth触发的衍生项目Paradict和Braq的推出,其生态系统正在不断扩展,显示了该格式的强大适应力和创新潜力。对于寻求超越传统配置格式限制的开发者来说,Jesth无疑是一个值得深入探索的宝藏。
加入Jesth的使用者行列,体验一种全新的数据组织和交流方式,让你的项目受益于这份自由与强大。通过上述的技术概述和应用场景介绍,相信你已经感受到Jesth带来的革新魅力。接下来,不妨亲自尝试,探索Jesth如何助力你的编程旅程,开启灵活数据管理新篇章。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0218
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0218 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0139
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0139 uni-appA cross-platform framework using Vue.jsJavaScript09
uni-appA cross-platform framework using Vue.jsJavaScript09 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00
SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00 tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03

最新内容推荐
