利用梯度优化超参数:通过可逆学习的革命性方法
2024-05-22 20:55:16作者:钟日瑜
在这个数字化和智能化的时代,深度学习和机器学习算法在各个领域大放异彩。然而,这些算法的成功往往离不开一个关键步骤——调参。调参之难在于我们通常无法获取超参数的梯度信息。但今天,我们要向您推荐一个突破性的开源项目,它彻底改变了这一格局:Gradient-based Optimization of Hyperparameters through Reversible Learning。
1、项目介绍
该项目由Dougal Maclaurin、David Duvenaud和Ryan P. Adams合作开发,他们提出了一种创新的计算策略,能够精确地求取交叉验证性能关于所有超参数的梯度,即使是在涉及成千上万的超参数时。这个独特的框架允许我们优化复杂的参数,如步长和动量调度、权重初始化分布、丰富参数化的正则化方案,甚至神经网络架构。
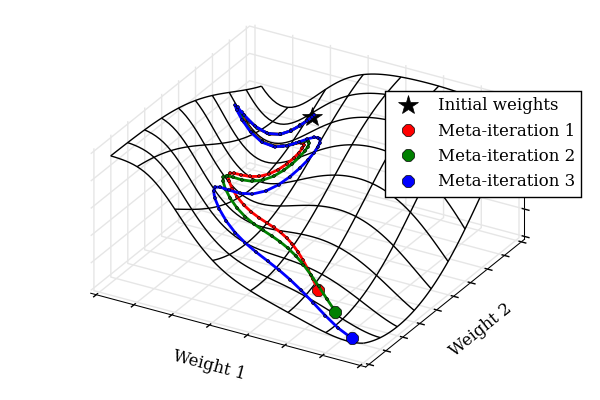 (图:不同超参数设置下的学习曲线)
(图:不同超参数设置下的学习曲线)
2、项目技术分析
该方法的核心是通过反向传播整个训练过程中的链式法则来计算梯度。作者们巧妙地利用了随机梯度下降法(SGD)与动量的可逆性质,实现了超参数的精确优化。这种技术不仅提供了对传统黑盒调参方法的替代,而且大大提高了优化效率和模型性能。
3、项目及技术应用场景
- 研究领域:对于任何需要超参数调优的研究项目,无论是神经网络设计还是其他机器学习模型,都能从这项技术中受益。
- 工业应用:在大数据处理、自然语言处理、计算机视觉等领域,它可以帮助工程师快速找到最优配置,提高模型的预测精度和运行效率。
- 教育教学:作为一项前沿技术,它也适用于教授自动微分和优化原理的教学实践。
4、项目特点
- 精准优化:能计算出超参数的梯度,实现精确的超参数调优。
- 广泛适用:不仅限于简单的超参数,也能处理复杂的学习规则和网络结构。
- 高效:通过反向传播动态,减少了试错和反复训练的时间成本。
- 开放源码:该项目采用MIT许可证,代码公开,易于集成到现有项目中。
要使用这个项目,您需要安装autograd,并确保其版本与hypergrad兼容。虽然目前版本有些许不匹配,但作者提供了解决方案,按照指南进行设置即可顺利运行实验。
如果您对项目有任何疑问或需要帮助,请直接联系作者邮箱(maclaurin@physics.harvard.edu)或(dduvenaud@seas.harvard.edu)。现在就加入这个革命性的调参之旅,让您的模型性能更上一层楼吧!
登录后查看全文
热门项目推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0195
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0195 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0124
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0124 MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00
MiMo-V2.5-Pro-FP4-DFlashMiMo-V2.5-Pro-FP4-DFlash 是驱动 MiMo-V2.5-Pro-UltraSpeed 的底层模型: FP4 量化骨干网络:对 MoE 专家采用 MXFP4 量化,同时保持模型其他部分的更高精度,在几乎无损质量的前提下,显著减小模型体积并降低内存带宽压力。 BF16 DFlash 草稿生成器:用于块扩散推测解码,每次前向传播可生成一整个块的 tokens,并让骨干网络一步完成验证。 两者协同作用,既降低了每参数的位宽,又减少了骨干网络前向传播的次数,而这两者正是万亿参数模型解码过程中的两大主要成本来源。Python00 JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00
JoyAI-EchoJoyAI-Echo,这是一个独立的、仅用于推理的版本,旨在实现分钟级多镜头音视频生成。它采用了经过蒸馏的DMD生成器、配对的跨模态记忆以及故事级别的一致性。其性能的核心在于,一个跨模态视听记忆库能够在长达五分钟的视频中保持角色外观和语音音色的一致性。同时,一个训练后处理流程将基于记忆的强化学习与分布匹配蒸馏相结合,实现了7.5倍的速度提升,显著增强了视觉质量和对齐效果。00 AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python05
AstrBot✨ 易上手的多平台 LLM 聊天机器人及开发框架 ✨ 平台支持 QQ、QQ频道、Telegram、微信、企微、飞书 | OpenAI、DeepSeek、Gemini、硅基流动、月之暗面、Ollama、OneAPI、Dify 等。附带 WebUI。Python05 handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07
handy-ollama动手学Ollama,CPU玩转大模型部署,在线阅读地址:https://datawhalechina.github.io/handy-ollama/Jupyter Notebook07

项目优选
收起
暂无描述
Dockerfile
766
5 K
本项目是CANN提供的transformer类大模型算子库,实现网络在NPU上加速计算。
C++
859
1.94 K
本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。
C++
687
1.35 K
Ascend Extension for PyTorch
Python
721
893
openEuler内核是openEuler操作系统的核心,既是系统性能与稳定性的基石,也是连接处理器、设备与服务的桥梁。
C
458
446
本项目是CANN提供的数学类基础计算算子库,实现网络在NPU上加速计算。
C++
1.08 K
1.11 K
本仓库是 Flutter SDK 与 Flutter Engine 的 OpenHarmony 适配版本,由 CPF-Flutter 团队维护。开发者可使用熟悉的 Flutter 技术栈开发 OpenHarmony 应用,3.35.7 及以后的适配版本可基于本仓库源码构建支持 OpenHarmony 的 Flutter Engine。
Dart
1.01 K
262
CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。
Python
1 K
620
openJiuwen agent-studio提供零码、低码可视化开发和工作流编排,模型、知识库、插件等各资源管理能力
TSX
2.99 K
637
华为昇腾面向大规模分布式训练的多模态大模型套件,支撑多模态生成、多模态理解。
Python
152
255