bpftime:用户态eBPF运行时,加速Uprobe与Syscall Hook
项目介绍
bpftime 是一个功能全面、高性能的用户态eBPF运行时,专为在用户空间中运行eBPF程序而设计。它提供了快速的用户态Uprobe和Syscall Hook功能,能够在不重启或手动重新编译的情况下,安全高效地挂钩和过滤进程的所有系统调用。bpftime 的核心优势在于其用户态Uprobe的性能,相比内核态Uprobe,速度提升了10倍!
项目技术分析
bpftime 的核心技术包括:
- 二进制重写基础的Uprobe和Syscall Hook:通过二进制重写技术,
bpftime能够在用户空间中运行eBPF程序,并将其附加到Uprobes和Syscall跟踪点上。无需手动插桩或重启,即可实现函数的跟踪和执行路径的修改。 - 高性能:用户态Uprobe的开销比内核态Uprobe低10倍,用户态内存的读写速度也优于内核态eBPF。
- 进程间eBPF映射:在共享用户态内存中实现eBPF映射,用于汇总聚合或控制平面通信。
- 兼容性:支持使用现有的eBPF工具链(如clang、libbpf和bpftrace)开发用户态eBPF应用程序,无需任何修改。支持CO-RE(Compile Once, Run Everywhere)通过BTF,并提供用户态
ufunc访问。 - 多JIT支持:支持llvmbpf,这是一个由LLVM驱动的高速JIT/AOT编译器,或使用
ubpf JIT和INTERPRETER。虚拟机可以构建为独立的库,类似于ubpf。 - 与内核eBPF协同运行:可以从内核加载用户态eBPF程序,并使用内核eBPF映射与内核eBPF程序(如kprobes和网络过滤器)协同工作。
项目及技术应用场景
bpftime 适用于多种应用场景,包括但不限于:
- 性能监控与调优:通过用户态Uprobe和Syscall Hook,实时监控应用程序的性能瓶颈,无需重启或重新编译。
- 安全审计:安全地挂钩和过滤进程的所有系统调用,用于安全审计和入侵检测。
- 动态插桩:在不重启进程的情况下,动态注入eBPF程序,实现函数的跟踪和行为修改。
- 网络过滤与加速:与内核eBPF协同工作,实现高效的网络过滤和加速。
项目特点
- 高性能:用户态Uprobe的性能比内核态Uprobe高10倍,用户态内存的读写速度也更快。
- 无需重启:无需手动插桩或重启,即可实现函数的跟踪和执行路径的修改。
- 兼容性强:支持现有的eBPF工具链,无需任何修改。
- 多JIT支持:支持多种JIT编译器,包括LLVM和ubpf。
- 与内核eBPF协同:可以与内核eBPF协同工作,实现更强大的功能。
快速开始
使用bpftime,您可以使用熟悉的工具(如clang和libbpf)构建eBPF应用程序,并在用户空间中执行它们。例如,malloc eBPF程序通过uprobe跟踪malloc调用,并使用哈希映射聚合计数。
您可以参考eunomia.dev/bpftime/documents/build-and-test了解如何构建项目,或使用GitHub packages中的容器镜像。
要开始使用,您可以构建并运行基于libbpf的eBPF程序,通过bpftime CLI启动:
make -C example/malloc # 构建eBPF程序示例
bpftime load ./example/malloc/malloc
在另一个shell中,使用eBPF运行目标程序:
$ bpftime start ./example/malloc/victim
Hello malloc!
malloc called from pid 250215
continue malloc...
malloc called from pid 250215
您还可以动态附加eBPF程序到正在运行的进程:
$ ./example/malloc/victim & echo $! # 进程ID为101771
[1] 101771
101771
continue malloc...
continue malloc...
然后附加到它:
$ sudo bpftime attach 101771 # 您可能需要以root权限运行make install
Inject: "/root/.bpftime/libbpftime-agent.so"
Successfully injected. ID: 1
您可以看到原始程序的输出:
$ bpftime load ./example/malloc/malloc
...
12:44:35
pid=247299 malloc calls: 10
pid=247322 malloc calls: 10
或者,您也可以直接在内核eBPF中运行我们的示例eBPF程序,以查看类似的输出。这可以作为bpftime如何与内核eBPF兼容工作的示例。
$ sudo example/malloc/malloc
15:38:05
pid=30415 malloc calls: 1079
pid=30393 malloc calls: 203
pid=29882 malloc calls: 1076
pid=34809 malloc calls: 8
更多详细信息,请参阅eunomia.dev/bpftime/documents/usage。
示例与用例
bpftime 目前正在积极开发中,尚未推荐用于生产环境。请参阅我们的路线图了解详情。我们非常欢迎您的反馈和建议!请随时打开一个issue或联系我们。
更多示例和详细信息,请参考eunomia.dev/bpftime/documents/examples/网页。
示例包括:
- 最小示例的eBPF程序。
- eBPF
Uprobe/USDT跟踪和syscall跟踪:- sslsniff 用于跟踪SSL/TLS未加密数据。
- opensnoop 用于跟踪文件打开系统调用。
- 更多bcc/libbpf-tools。
- 使用bpftrace命令或脚本运行。
- 错误注入:使用
bpf_override_return更改函数行为。 - 将eBPF LLVM JIT/AOT虚拟机用作独立库。
- 用户态XDP eBPF与DPDK。
深入了解
工作原理
bpftime 支持两种模式:
仅在用户空间运行
左侧:原始内核eBPF | 右侧:bpftime
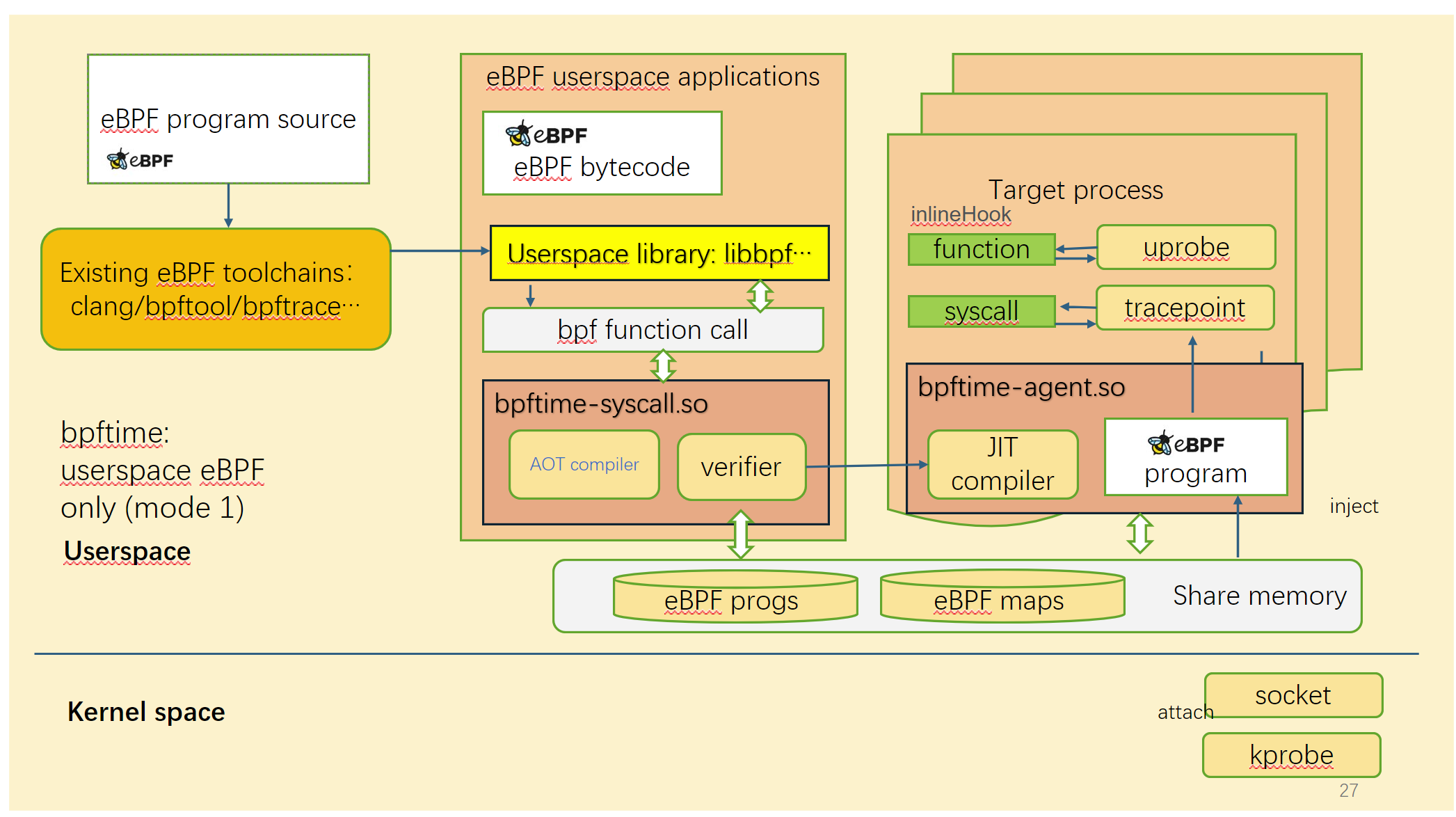
在这种模式下,bpftime 可以在用户空间中运行eBPF程序,无需内核支持,因此可以移植到低版本的Linux或其他系统中,并且无需root权限即可运行。它依赖于用户态验证器来确保eBPF程序的安全性。
与内核eBPF协同运行
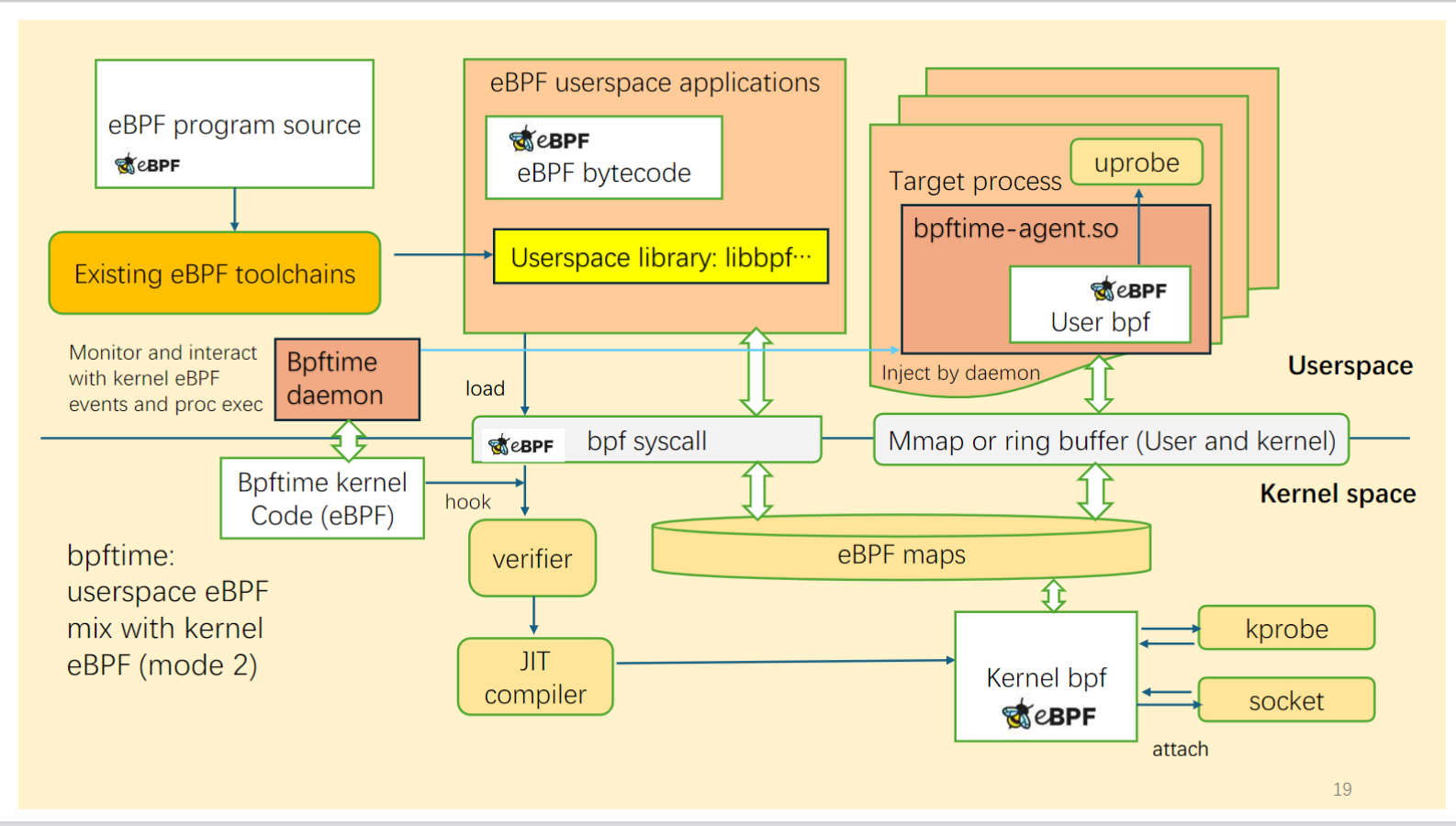
在这种模式下,bpftime 可以与内核eBPF协同运行。它可以从内核加载eBPF程序,并使用内核eBPF映射与内核eBPF程序(如kprobes和网络过滤器)协同工作。
插桩实现
当前的挂钩实现基于二进制重写,底层技术灵感来自:
- 用户态函数挂钩:frida-gum
- 系统调用挂钩:zpoline 和 pmem/syscall_intercept。
挂钩可以轻松替换为其他DBI方法或框架,或在未来添加更多挂钩机制。
更多详细信息,请参阅我们的预印本论文bpftime: userspace eBPF Runtime for Uprobe, Syscall and Kernel-User Interactions。
性能基准测试
用户态Uprobe与内核态Uprobe的性能对比如何?
| 探针/跟踪点类型 | 内核(ns) | 用户态(ns) |
|---|---|---|
| Uprobe | 3224.172760 | 314.569110 |
| Uretprobe | 3996.799580 | 381.270270 |
| 系统调用跟踪点 | 151.82801 | 232.57691 |
| 手动插桩 | 不可用 | 110.008430 |
它可以像内核Uprobe一样附加到正在运行的进程中的函数。
LLVM JIT/AOT与其他eBPF用户态运行时、原生代码或wasm运行时的性能对比如何?

在所有测试中,bpftime的LLVM JIT始终展现出卓越的性能。两者在整数计算(如log2_int)、复杂数学运算(如prime)和内存操作(如memcpy和strcmp)中均表现出高效性。尽管它们在性能上领先,但每个运行时都有其独特的优势和劣势。这些见解有助于选择最适合特定应用场景的运行时。
总结
bpftime 是一个功能强大且高性能的用户态eBPF运行时,适用于多种应用场景。其高性能、无需重启、兼容性强和多JIT支持等特点,使其成为开发和部署eBPF应用程序的理想选择。无论您是性能监控、安全审计还是动态插桩的需求,bpftime 都能为您提供高效、灵活的解决方案。立即尝试bpftime,体验用户态eBPF的强大功能!

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0215
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0215 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0138
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0138 uni-appA cross-platform framework using Vue.jsJavaScript08
uni-appA cross-platform framework using Vue.jsJavaScript08 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00
SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00 tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03

最新内容推荐
