告别机翻尴尬!LunaTranslator自定义评分体系让Galgame翻译质量可控
你是否遇到过Galgame翻译中"主角名字忽男忽女"、"技能术语前后矛盾"的尴尬?作为Visual Novel玩家,翻译质量直接影响剧情沉浸感。LunaTranslator提供的不仅仅是翻译工具,更是一套完整的翻译质量控制体系。本文将详解如何通过自定义评价标准,打造专属于你的翻译质量评分系统,让每一句对话都精准传达角色情感。
核心评分维度与配置路径
LunaTranslator的翻译质量控制基于多维度优化模块,主要评分维度包括:
评分权重配置文件
所有评分维度的权重配置存储在: src/LunaTranslator/defaultconfig/transerrorfixdictconfig.json
该JSON文件采用键值对结构,可通过修改"weight"字段调整各维度权重:
{
"proper_noun_consistency": {
"enabled": true,
"weight": 0.3
},
"text_fluency": {
"enabled": true,
"weight": 0.25
}
}
专有名词一致性评分实现
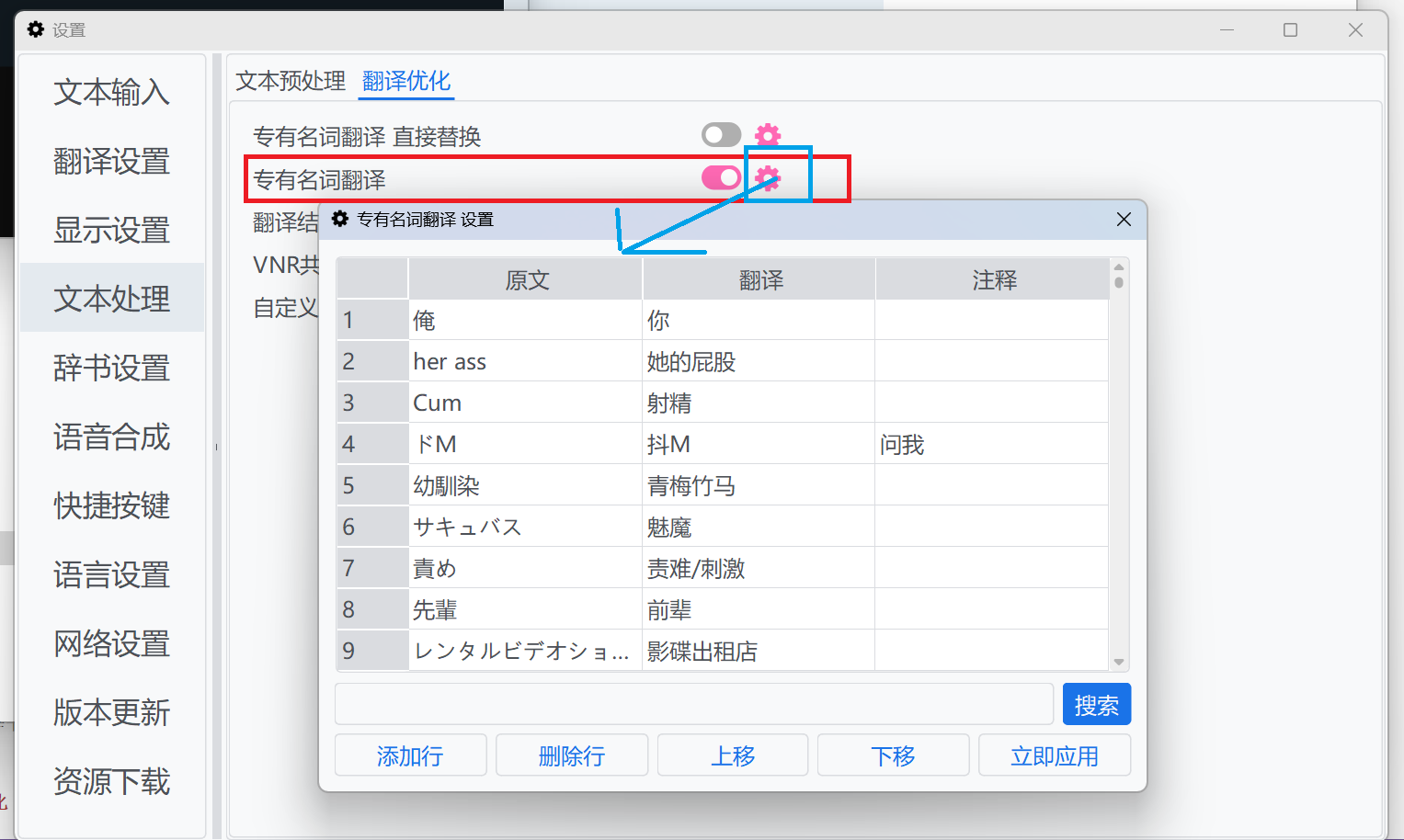
专有名词翻译是Galgame本地化的重中之重。LunaTranslator提供双层控制机制:
- 全局词典:管理跨游戏通用术语
- 游戏专用词典:针对特定作品优化
配置步骤
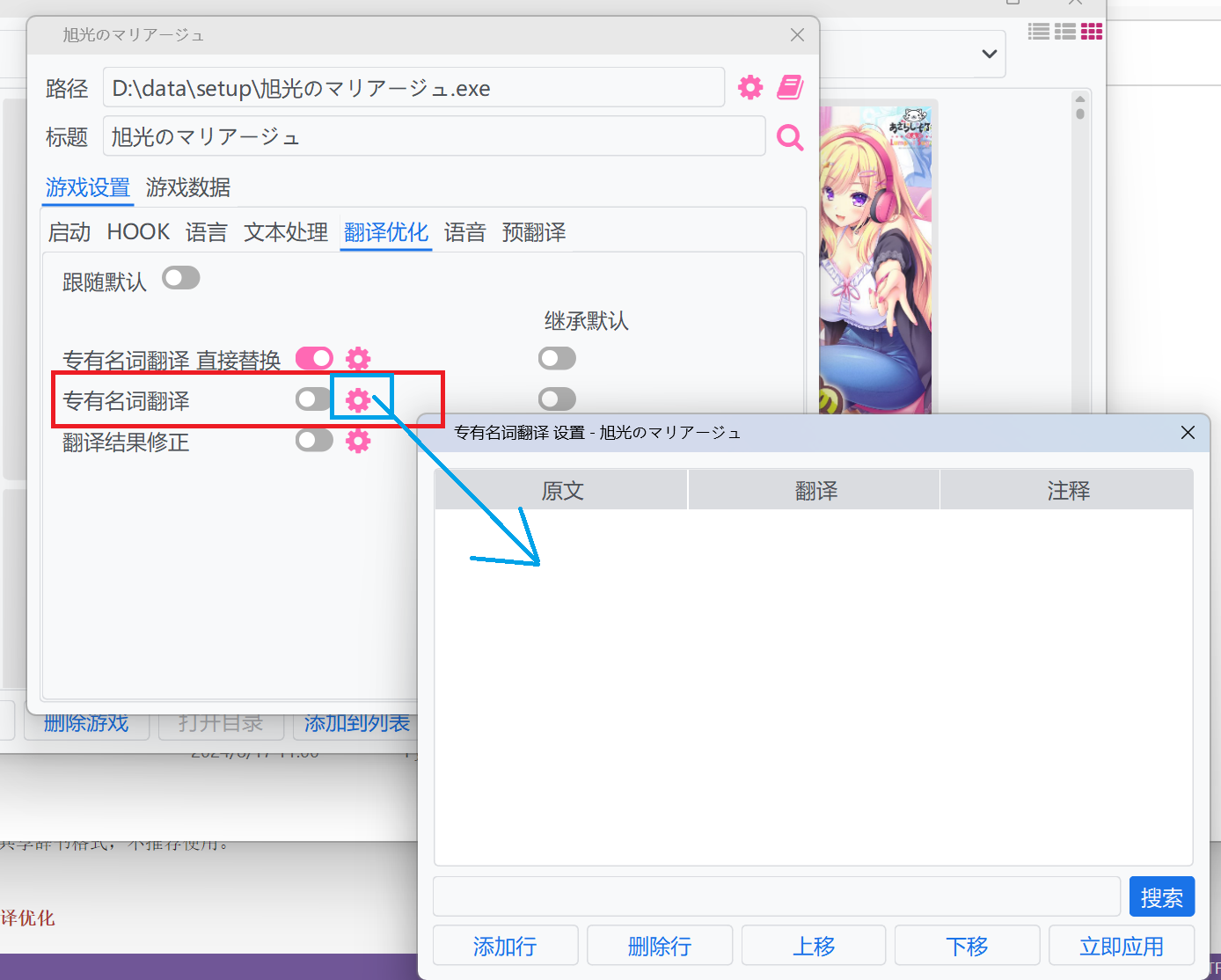
- 打开游戏设置 → 翻译优化
- 取消"跟随默认"选项激活游戏专用设置
- 添加角色名、技能术语等关键名词
评分计算逻辑
系统通过正则匹配检测术语一致性,评分公式为:
# 伪代码示意
consistency_score = (匹配成功次数 / 总术语数) * 权重
关键实现文件:src/LunaTranslator/transoptimi/
文本流畅度自动评分
流畅度评分基于LunaTranslator的文本后处理系统,通过postprocessconfig.json配置修正规则。系统默认启用以下优化:
{
"_2": {
"use": true,
"name": "HOOK_去除重复字符_AAAABBBBCCCC->ABC",
"args": {
"重复次数(若为1则自动分析去重)": 1,
"保持非重复字符": true
}
},
"_3": {
"use": true,
"name": "HOOK_去除重复行_ABCDABCDABCD->ABCD"
}
}
流畅度评分范围为0-10分,通过检测修正规则的应用效果自动计算:
- 重复字符去除率
- 标点符号规范度
- 语句长度合理性
上下文适配性评分体系
Galgame的翻译质量高度依赖场景适配,LunaTranslator在游戏设置中提供"继承默认"选项:
- 激活时:同时应用全局词典+游戏专用词典
- 关闭时:仅使用游戏专用词典
上下文适配性评分通过对比不同场景下的翻译结果差异实现,关键检测点包括:
- 角色语气一致性
- 场景氛围适配度
- 文化梗翻译准确性
自定义评分规则实现
对于高级用户,LunaTranslator支持通过Python脚本扩展评分维度。在postprocessconfig.json中启用自定义处理:
{
"_11": {
"use": true,
"name": "自定义python处理",
"script_path": "custom_score.py"
}
}
示例自定义评分脚本:
def calculate_custom_score(original_text, translated_text):
# 实现自定义评分逻辑
score = 0
# 检查感叹号使用频率
original_excl = original_text.count('!')
translated_excl = translated_text.count('!')
if abs(original_excl - translated_excl) < 2:
score += 5
return score
评分结果可视化与应用
配置完成后,评分结果会实时显示在翻译界面,并生成质量报告。通过以下步骤应用评分结果:
- 设置评分阈值(建议80分)
- 启用"低评分自动修正"
- 配置修正策略(人工审核/自动重试)
常见问题解决可参考官方QA文档,其中详细说明如何处理评分异常情况。

最佳实践与配置模板
根据社区经验,推荐以下评分权重配置:
- 专有名词一致性:35%
- 文本流畅度:25%
- 上下文适配性:20%
- OCR识别准确率:20%
游戏专用配置模板位于:docs/zh/emugames_template.md,可直接导入使用。
通过LunaTranslator的自定义评分体系,你可以告别"碰运气"式翻译体验,打造真正贴合个人阅读习惯的Galgame翻译质量控制方案。立即配置你的专属评分标准,让每一句台词都精准传达创作者的初衷。
提示:所有配置文件修改后需重启软件生效,建议修改前备份原始配置。完整评分体系文档参见官方翻译优化指南。

相关内容推荐
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0214
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0214 cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0138
cann-learning-hubCANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。Jupyter Notebook0138 uni-appA cross-platform framework using Vue.jsJavaScript08
uni-appA cross-platform framework using Vue.jsJavaScript08 GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00
GLM-5.2智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。Jinja00 SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00
SwanLab⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / LLaMA Factory / veRL/ Swift / Ultralytics / MMEngine / Keras etc.Python00 tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
tiny-universe《大模型白盒子构建指南》:一个全手搓的Tiny-UniverseJupyter Notebook03
热门内容推荐

最新内容推荐
