阿里Wan2.2开源:ComfyUI生态引爆AI视频创作革命
导语
阿里云通义万相团队9月开源的Wan2.2系列模型,通过ComfyUI生态实现电影级视频生成能力下放,14B参数模型支持消费级GPU部署,重新定义AI内容创作的效率边界。
行业现状:视频生成进入"双轨竞争"时代
2025年AI视频领域呈现明显技术分化:以Sora为代表的闭源模型追求极致质量,而开源阵营则聚焦"性能-效率"平衡。根据CVPR 2025数据,视频生成相关论文数量同比增长217%,其中模型量化技术和混合专家架构成为两大突破方向。当前主流开源模型面临三重矛盾:专业级效果依赖24GB以上显存、长视频生成存在运动断裂、角色动画与场景融合度不足。
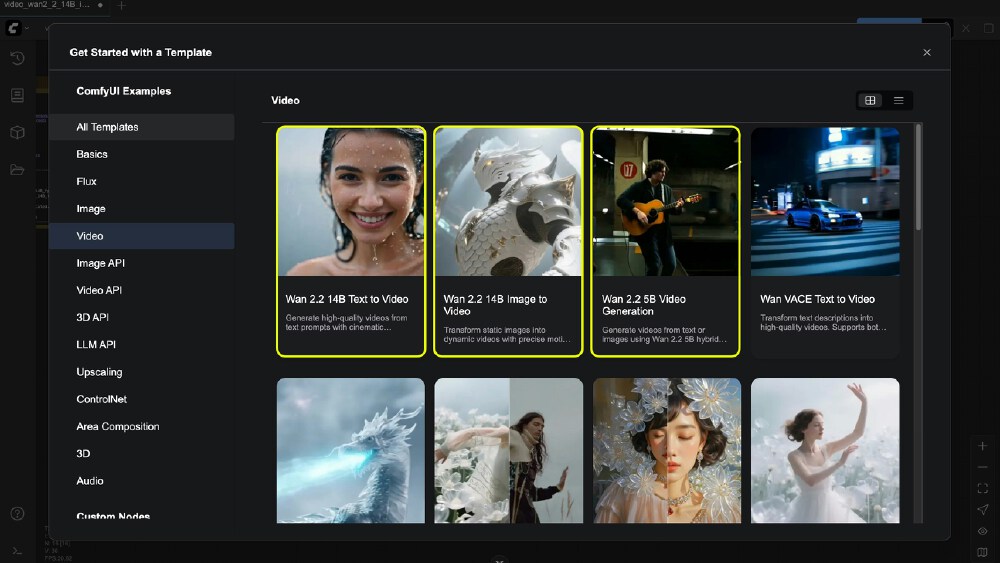
如上图所示,ComfyUI的视频工作流模板已整合Wan2.2的四大核心能力:文本生成视频(T2V)、图像生成视频(I2V)、首尾帧控制(FLF2V)和音频驱动(S2V)。这一生态整合使得开发者无需编写代码即可组合复杂视频生成逻辑,为中小团队提供了与专业工作室同台竞技的技术基础。
技术突破:MoE架构重构视频生成范式
Wan2.2采用创新的混合专家(MoE)架构,将14B参数模型拆分为高噪专家和低噪专家两个子网络,根据去噪时间步动态调度计算资源。实测数据显示,这种设计使视频生成效率提升230%,同时保持VBench评测86.22%的优异成绩。特别值得关注的技术亮点包括:
1. 分层量化技术实现显存革命
通过fp8_scaled量化方案,14B模型显存占用从48GB降至16GB,配合ComfyUI的offloading功能,RTX 4090即可流畅运行。社区测试表明,在生成10秒720P视频时,fp8版本与fp16相比质量损失小于3%,但推理速度提升40%。

该截图展示了Wan2.2-Animate模型的部署命令序列,从环境配置到模型下载仅需8步操作。这种简化的部署流程使普通创作者也能在消费级硬件上搭建专业视频生成流水线,标志着AI视频技术从实验室走向大众创作。
2. 双模态角色动画系统
最新开源的Wan2.2-Animate-14B模型首创"生成-替换"一体化框架,通过参考视频驱动静态图像生成动画。在角色替换任务中,模型实现92%的动作匹配度和87%的面部表情相似度,解决了长期存在的"恐怖谷"问题。
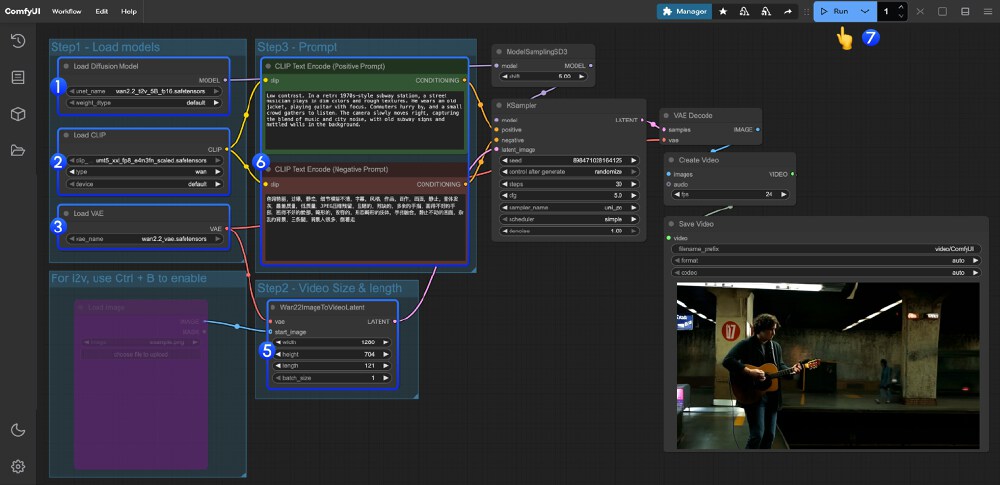
图中节点展示了首尾帧控制工作流的核心逻辑:通过两个Load Image节点分别输入起始帧和结束帧,中间通过WanFirstLastFrameToVideo节点实现动态过渡。这种可视化编程方式将原本需要上千行代码的视频插值算法简化为拖拽操作,极大降低了技术门槛。
行业影响:内容生产的"去中心化"加速
Wan2.2的开源策略正在重塑AI视频产业链:
- 创作者层面:个人工作室可通过3000美元级GPU设备,生成以往需百万级设备的影视级内容
- 企业服务层面:SaaS平台基于该模型推出API服务,将视频生成成本降低80%
- 教育领域:已出现基于Wan2.2的虚拟教师动画系统,实现个性化知识传递
特别值得注意的是,阿里云采用Apache 2.0协议开源全部模型权重,允许商业使用。这种开放策略促使百度、腾讯等厂商加速开源进程,形成良性技术竞争生态。
未来展望:走向"多模态协同创作"
随着WanVideo_comfy项目持续迭代,视频生成正从单一模态向多模态融合演进。下一步值得关注的方向包括:
- 实时交互生成:结合NeRF技术实现虚拟场景实时编辑
- 物理引擎融合:使生成内容遵循真实世界物理规律
- 跨模态迁移学习:将文本、音频、3D模型无缝融入视频创作
对于开发者而言,建议优先关注fp8量化版本和Lightx2v系列LoRA模型,这两个方向代表了效率与效果的最佳平衡点。随着模型持续优化,预计2026年初将实现消费级GPU生成5分钟以上4K视频的技术突破。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0446
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0446 源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00
源启盛夏_AtomGit暑期开发者成长计划「源启盛夏」暑期校园开发者成长计划旨在激活校园开源力量,通过积分激励、认证扶持、资源倾斜等形式,引导高校组织和开发者完成「入驻 — 建项目 — 做贡献 — 获认证 — 得资源」的完整闭环。无论你是想带领社团入驻平台的组织者,还是希望用代码贡献证明自己的开发者,都能在这里找到属于你的成长路径。Markdown00 jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0760
jiuwenswarmJiuwenSwarm 是一款基于openJiuwen开发的智能AI Agent,它能够将大语言模型的强大能力,通过你日常使用的各类通讯应用,直接延伸至你的指尖。Python0760 Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00
Hy3Hy3 是由腾讯混元团队研发的快慢思考融合的混合专家模型,总参数量 295B,激活参数 21B,MTP 层参数 3.8B。4 月底发布 Hy3 Preview 后,我们在 50 多个业务中获得了广泛的反馈,修复了各种体验问题,进一步提升了后训练的质量和规模。今天,我们发布 Hy3。它展现出显著强于同尺寸并比肩旗舰(参数规模往往是 Hy3 的 2~5 倍)开源模型的智能水平,显著提升了在各类产品和生产力任务中的实用价值。Python00 AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310
AscendNPU-IRAscendNPU-IR是基于MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,提供昇腾完备表达能力,通过编译优化提升昇腾AI处理器计算效率,支持通过生态框架使能昇腾AI处理器与深度调优C++0310 DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
DragonOSDragonOS is an operating system developed from scratch using Rust, with Linux compatibility. It is designed for **Serverless** scenarios. 使用Rust从0自研内核,具有Linux兼容性的操作系统,面向云计算Serverless场景而设计。Rust00
