阿里WanVideo开源生态:ComfyUI驱动的AI视频创作革命
导语
2025年AI视频生成领域迎来关键突破——阿里巴巴通义万相团队开源的WanVideo_comfy项目,通过ComfyUI生态实现电影级视频生成能力下放,14B参数模型支持消费级GPU部署,重新定义AI内容创作的效率边界。
行业现状:视频生成进入"双轨竞争"时代
2025年全球AI视频生成市场规模预计达7.17亿美元,年复合增长率超20%。当前行业呈现明显技术分化:以Sora为代表的闭源模型追求极致质量,而开源阵营则聚焦"性能-效率"平衡。根据CVPR 2025数据,视频生成相关论文数量同比增长217%,其中模型轻量化、本地化部署技术成为研究热点。
WanVideo_comfy项目正是这一趋势的典型实践。该项目整合并量化了Wan-AI系列视频模型,包括Wan2.1-VACE-14B/1.3B等核心模型,同时兼容TinyVAE、SkyReels等第三方组件,形成完整的视频生成工具链。与闭源模型动辄需要云端算力支持不同,WanVideo通过模型量化(如FP8_Scaled版本)和显存优化技术,首次实现消费级GPU(8GB显存)运行影视级视频创作。
核心亮点:技术突破与场景落地
WanVideo_comfy的核心优势在于**"高质量生成+低门槛部署"**的双重突破。项目提供两种部署路径:通过ComfyUI-WanVideoWrapper插件或原生WanVideo节点,用户可快速搭建从文本/图像到视频的全流程创作管线。
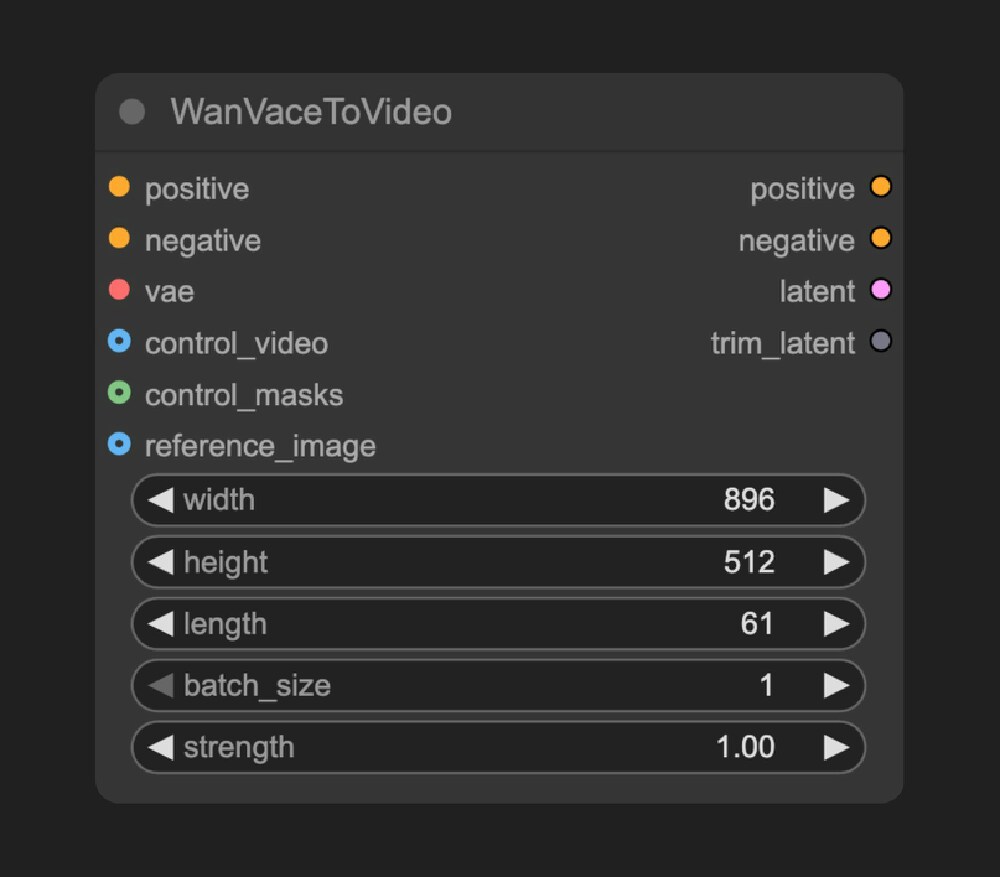
如上图所示,ComfyUI原生Wan Vace To Video节点支持文本、图像、视频等多模态输入,可通过控制遮罩和参考图像精准引导生成过程。这一节点设计充分体现了WanVideo的技术灵活性,为创作者提供了精细化视频生成控制能力。
在技术实现上,项目采用模块化架构:
- 多模型融合:整合Wan2.1-VACE、CausVid等模型,支持文本生成视频(T2V)、图像生成视频(I2V)等多任务
- 量化优化:推出FP8_Scaled版本模型,显存占用降低40%同时保持生成质量
- 生态兼容:支持ComfyUI全流程节点式操作,与VideoHelperSuite等插件无缝协作
实际应用中,WanVideo已展现出广泛适用性:
- 静态图像动态化:将插画转换为角色眨眼、场景微动的短视频
- 广告自动化制作:输入产品图片生成带转场特效的营销视频
- 双语智能字幕:生成视频时自动添加适配人物运动轨迹的字幕
本地化部署:从代码到视频的全流程
对于普通用户,WanVideo_comfy的部署门槛已大幅降低。项目提供完整的本地部署方案,通过Miniconda创建虚拟环境、ComfyUI Manager安装插件,即可完成环境配置。

上图展示了Linux系统中使用wget下载Miniconda并执行安装脚本的关键步骤。根据官方教程,用户只需克隆仓库(git clone https://gitcode.com/hf_mirrors/Kijai/WanVideo_comfy)、下载模型文件并运行ComfyUI,即可启动视频生成工作流。
值得注意的是,项目针对不同硬件配置提供差异化方案:
- 高性能配置:推荐使用Wan2.1-VACE-14B完整模型,生成4K分辨率视频
- 入门级配置:建议选择1.3B轻量化模型,配合FP8量化实现流畅运行
行业影响与未来趋势
WanVideo_comfy的开源释放了多重行业信号:
- 创作民主化加速:将专业级视频生成能力下放至个人创作者,广告制作、自媒体等领域的内容生产效率有望提升3-5倍
- 开源生态成熟:ComfyUI作为AI创作基础设施的地位进一步巩固,节点式工作流成为内容创作新范式
- 技术普惠深化:模型量化和本地化部署技术突破,使AI视频创作摆脱对高端硬件的依赖
未来,随着Wan2.2系列模型(如Wan2.2-Animate-14B)的持续迭代,预计将实现更长时长视频生成(目前支持最长81帧)和更精细的动作控制。同时,项目正在探索LoRA微调功能,允许用户通过少量数据定制专属视频风格,这一方向可能成为开源视频生成的下一个突破点。
结语
WanVideo_comfy的出现,标志着AI视频生成从"实验室演示"迈向"实用化工具"的关键转折。对于内容创作者,这意味着更低成本、更高效率的视频制作方案;对于行业而言,开源模式将推动技术快速迭代和场景创新。
随着模型性能持续优化和生态不断完善,我们有理由相信,AI驱动的视频创作将在未来1-2年内实现真正的产业化落地。而WanVideo_comfy项目,正站在这场创作革命的前沿。
 atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152
atomcodeClaude Code 的开源替代方案。连接任意大模型,编辑代码,运行命令,自动验证 — 全自动执行。用 Rust 构建,极致性能。 | An open-source alternative to Claude Code. Connect any LLM, edit code, run commands, and verify changes — autonomously. Built in Rust for speed. Get StartedRust0152- DDeepSeek-V4-ProDeepSeek-V4-Pro(总参数 1.6 万亿,激活 49B)面向复杂推理和高级编程任务,在代码竞赛、数学推理、Agent 工作流等场景表现优异,性能接近国际前沿闭源模型。Python00
 LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00
LongCat-Video-Avatar-1.5最新开源LongCat-Video-Avatar 1.5 版本,这是一款经过升级的开源框架,专注于音频驱动人物视频生成的极致实证优化与生产级就绪能力。该版本在 LongCat-Video 基础模型之上构建,可生成高度稳定的商用级虚拟人视频,支持音频-文本转视频(AT2V)、音频-文本-图像转视频(ATI2V)以及视频续播等原生任务,并能无缝兼容单流与多流音频输入。00 auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03
auto-devAutoDev 是一个 AI 驱动的辅助编程插件。AutoDev 支持一键生成测试、代码、提交信息等,还能够与您的需求管理系统(例如Jira、Trello、Github Issue 等)直接对接。 在IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。Kotlin03 Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00
Intern-S2-PreviewIntern-S2-Preview,这是一款高效的350亿参数科学多模态基础模型。除了常规的参数与数据规模扩展外,Intern-S2-Preview探索了任务扩展:通过提升科学任务的难度、多样性与覆盖范围,进一步释放模型能力。Python00 skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
skillhubopenJiuwen 生态的 Skill 托管与分发开源方案,支持自建与可选 ClawHub 兼容。Python0112
